

☞ 문서의 내용은 가장 하단 참고문헌 및 사이트를 참고하여 필자가 보기 쉽도록 정리한 내용입니다.
☞ 틀린 내용 및 저작권 관련 문의가 있는 경우 문의하시면 수정 및 삭제 조치하겠습니다.
요약
CPM은 선행 연구 구조(pose machine)에 CNN(convolutional neural networks)을 추가하여 Pose estimation한다. CPM은 지역적인 정보(receptive field)를 local한 영역에서 global한 영역으로 확대하여 다른 부위와의 관계를 고려한 모델이다. 각 신체 부위에 대한 2차원 confidence map(belief map = heat map)을 반복적으로 생성하고 다음 입력값으로 넘겨 보다 개선된 탐지가 가능하다. 또한 Gradient vanishing 문제를 해결하기 위해 단계 마다 confidence map의 손실(loss)를 계산한다.
*Gradient vanishing(기울기값이 사라지는 문제)는 인공신경망을 기울기값을 베이스로 하는 method(backpropagation)로 학습시키려고 할 때 발생되는 어려움이다. 특히 이 문제는 네트워크에서 앞쪽 레이어의 파라미터들을 학습시키고, 튜닝하기 정말 어렵게 만든다. 이문제는 신경망 구조에서 레이어가 늘어날수록 더 악화된다. 이것은 뉴럴 네트워크의 근본적인 문제점이 아니다. 이것은 특정한 activation function를 통해서 기울기 베이스의 학습 method를 사용할 때 문제가 된다.
출처 : ydseo.tistory.com/41
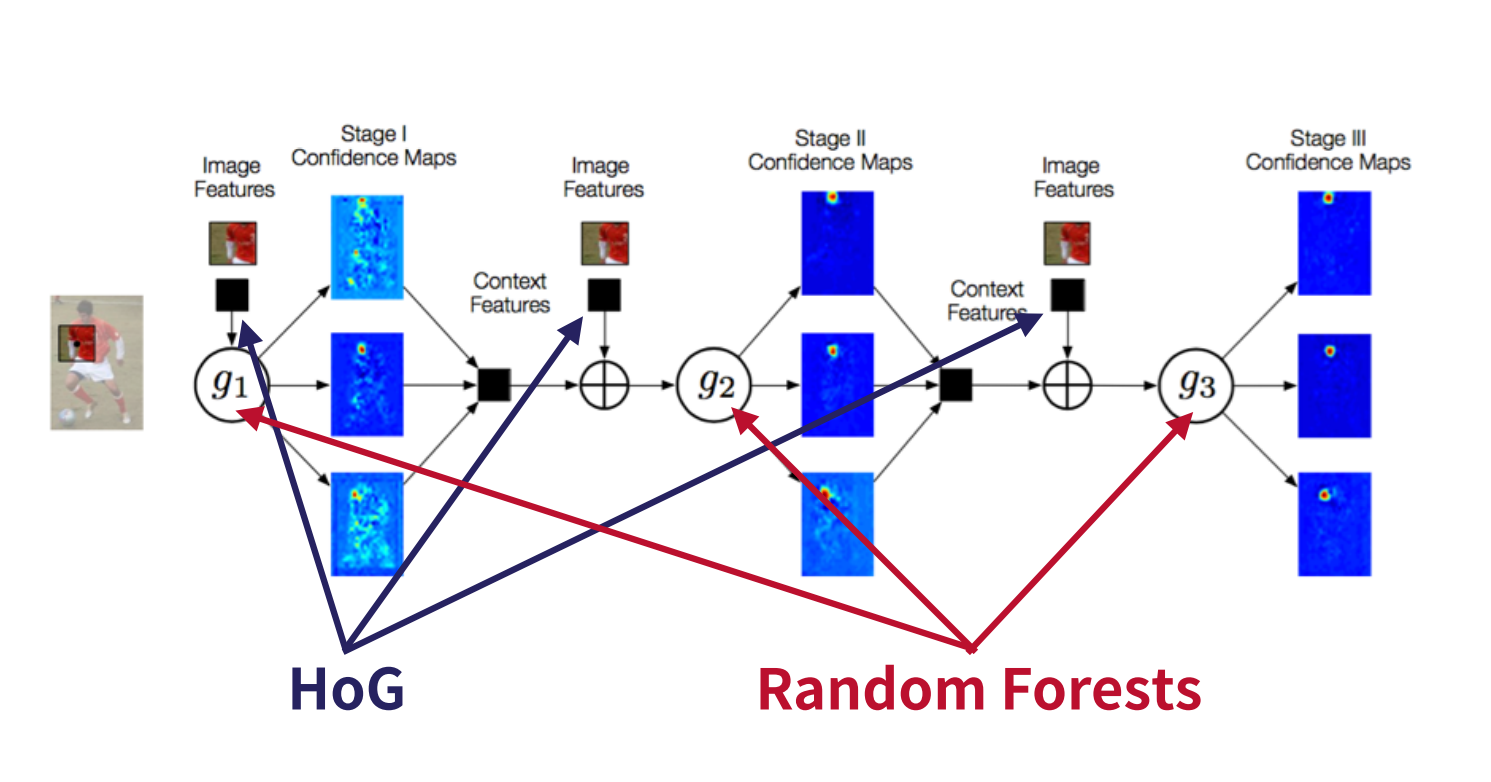
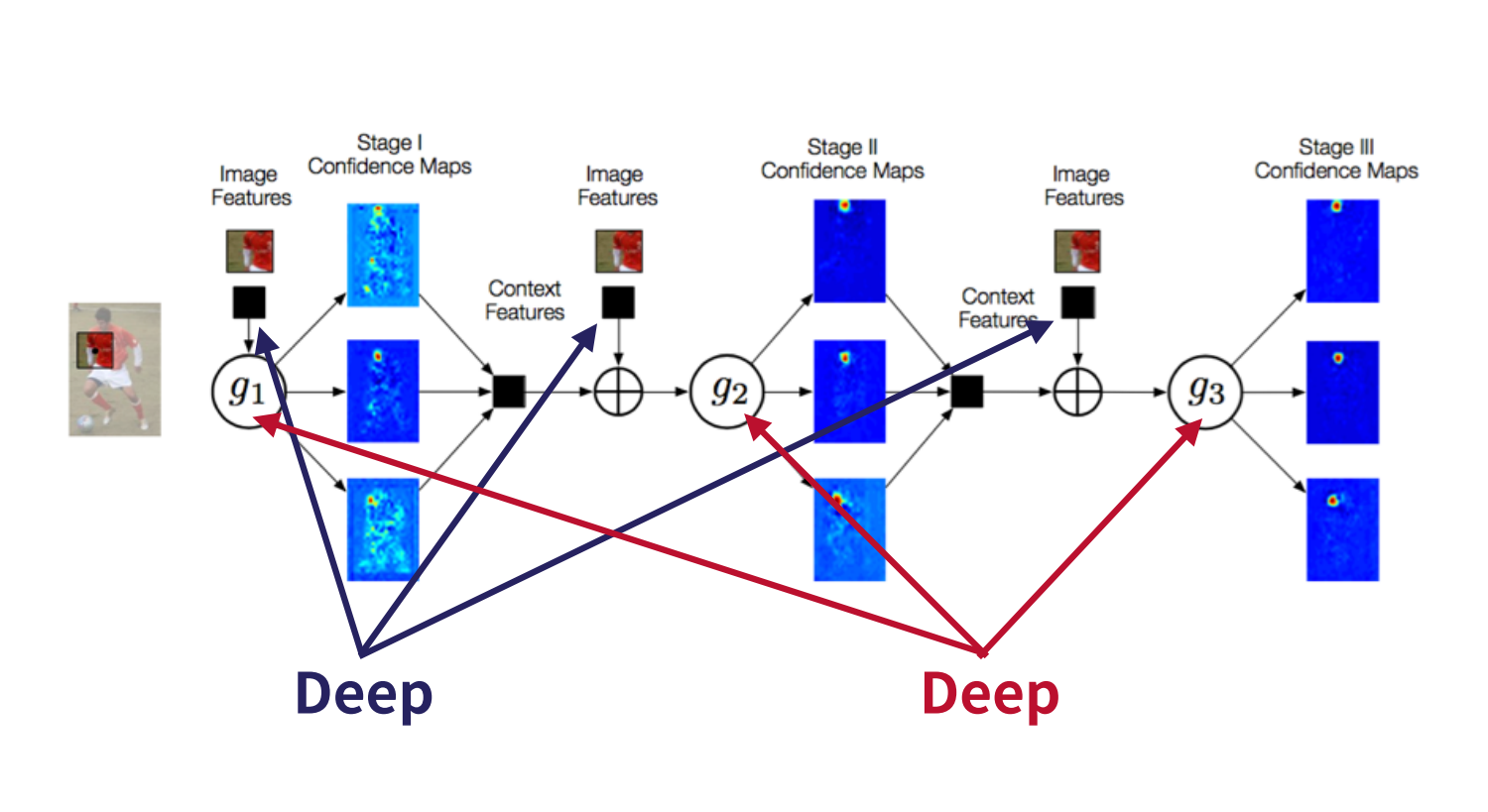
Convolutional Pose machine
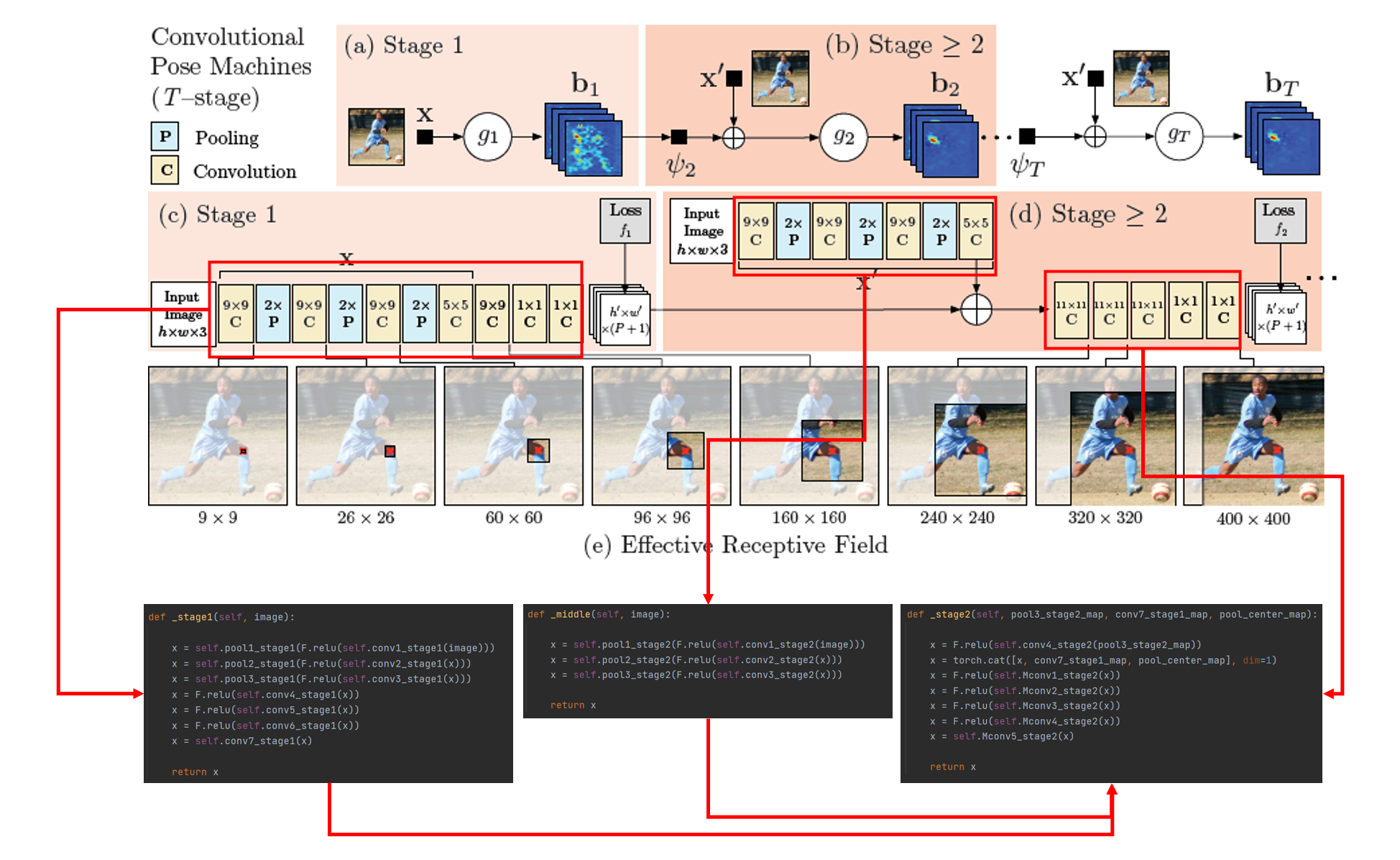
아래 그림은 CPM의 Network architecture로 선행 연구의 multi-stage processing 구조와 유사하다. 각 Stage에서 multi-class classifier를 통해 각 Part에 해당하는 belief map을 추정하고, 추정된 belief map정보는 fine-tuning을 위해 다음 stage로 전달된다. 선행 연구에서는 multi-class classifier(분류기)가 'human-defined function'이었으나, CPM에서는 CNN을 이용하였다. CNN은 하위 레이어에서는 local한 영역을 해석하고 상위 레이어로 갈 수록 receptive field가 커지면서 global한 영역을 해석한다. 이렇게 해석된 정보는 각 stage를 구성하는 CNN의 feature map에 저장된다.
* fine-tuning이란 기존에 학습되어져 있는 모델을 기반으로 아키텍쳐를 새로운 목적(나의 이미지 데이터에 맞게)변형하고 이미 학습된 모델 Weights로 부터 학습을 업데이트 하는 방법을 말한다.
출처 : eehoeskrap.tistory.com/186
Part : 사람의 관절
P(p : 1 ~ P) : 전체 Part 수
Belief map :
- 이미지 내 각 픽셀이 part 위치일 확률(입력 이미지 크기와 동일 크기의 map)
- 각 part 마다 1장 씩 할당
- 각 ground truth part position을 정점으로 하는 gaussian 형태의 확률 분포
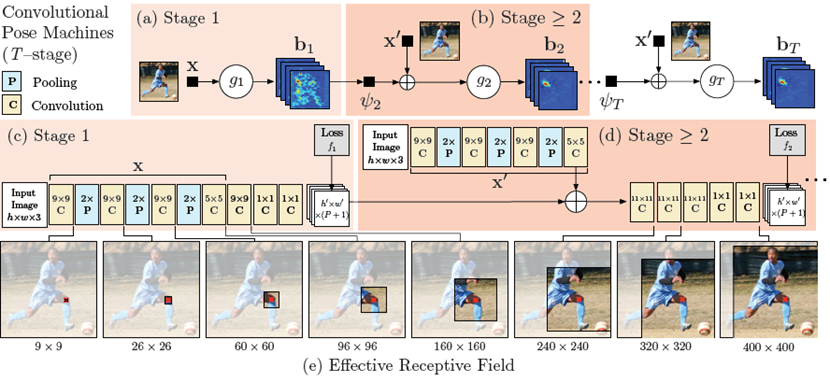
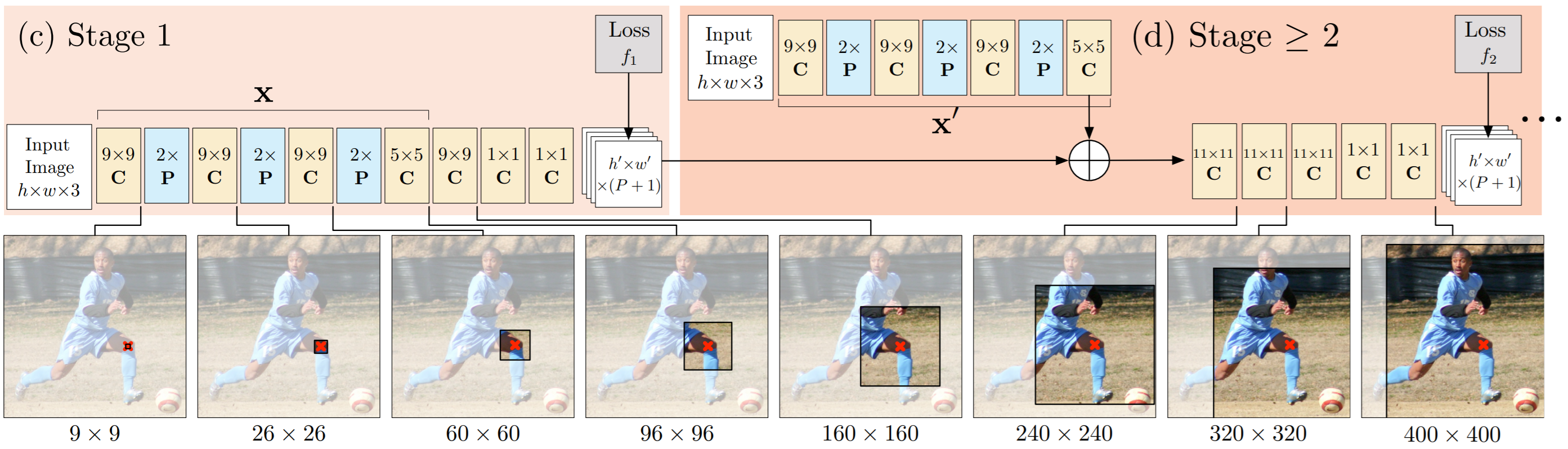
- 위 그림 (a)에서의 $b_t$ 또는 위 그림(c)에서 h' x w' x (P+1)
Image patch :
-전체 이미지 중 특정 location z 픽셀 주위의 일정 영역(local image)
$g_t$ :
- Belief map 을 출력하는 multi-class classifier
- t는 stage index
- 위 그림(c)에서 (9x9C -> 1x1C -> 1X1C)
- 위 그림(d)에서 (11x11C->11x11C ->11x11C->1x1C->1x1C)
- t=1일 경우만 다른 구조이고, t>=2 부터는 같은 구조임
⍦ :
- Feature function (아래 그림에서 X또는 X'을 출력)
- 위 그림에서 (9x9C -> 2xP -> 9x9C ->9x9C->2xP->5x5C)
- t>=2인 모든 feature function은 parameter가 같음
- t = 1은 구조는 같으나 파라미터는 다름

p번째 (part) 픽셀 위치, $Y_p ∈ Z ⊂ R^{2}$를 나타낸다. 여기서 Z는 이미지의 모든(u, v)위치의 집합이다. 목표는 모든 part에 대한 이미지 위치 $Y=(Y_1,....Y_p)$를 예측하는 것이다. 각 part를 예측하는 multi-class predictors $g_t(·)$들로 구성되어 있고, 이들의 구성은 stage별로 sequential(연속적)으로 구성되어 있다. $stage t ∈ {1...T}$별로 predictor $g_t$가 있고, 이 predictor들은 당연히 각 part의 $Y_p = z, ∀z ∈ Z $를 예측한다. 이 $g_t$들은 classifier이고, 각 위치에 표시된 location z ( part의 위치를 의미) 이미지를 추출한다. 그리고 각 stage t에서 각 part 즉 $Y_p$ 주위에서 context 정보를 기반으로 하여 분류한다.
첫 번째 Stage = 1에서의 분류기는 아래와 같이 정의 된다.
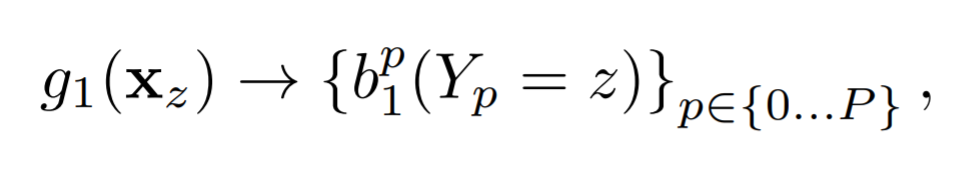
$b_1^{p}(Y_p = z)$ 는 이미지 위치 z에서 첫 번째 stage안에 각 part마다 $g1$ classifier 에 의해 예측된 score들을 의미한다. 이들은 각 파트마다 score map들이 있고, 각 score map은 그 영역(이미지 크기 W x H)별로 각 part의 score가 존재한다. 즉 아래와 같이 정의 된다.
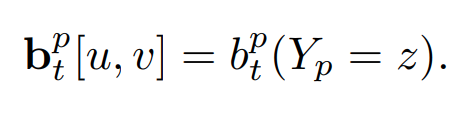
$^{l}b_t^{p} ∈ R^{w × h × (p+1)}$ 같이 각 part 마다 belief map이 구성되어 있다는 의미(+1는 background)
이 다음의 stage에서는 , 위에서 언급한 context 정보를 받는데 ... 그게 바로 이전 단계에서의 belief map이다.
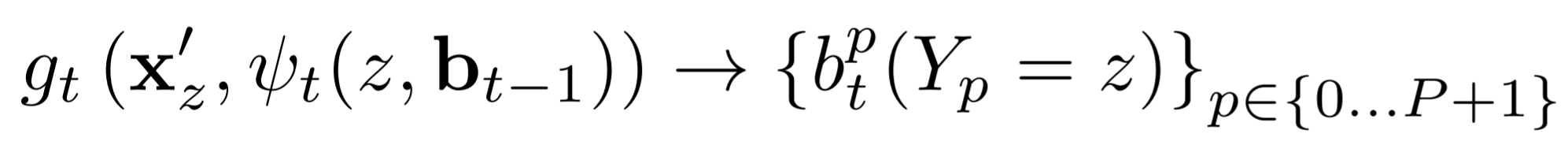
$x' = x$ : input를 계삭 각 stage에 받는 다는 의미.
정리하면 수식을 볼때 Stage > 1부터는 input image & belief map를 받는 다는 의미이다.
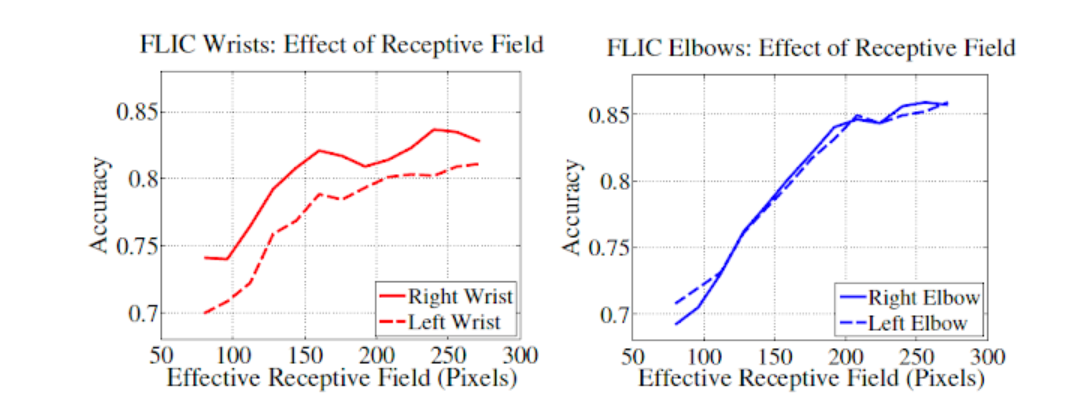
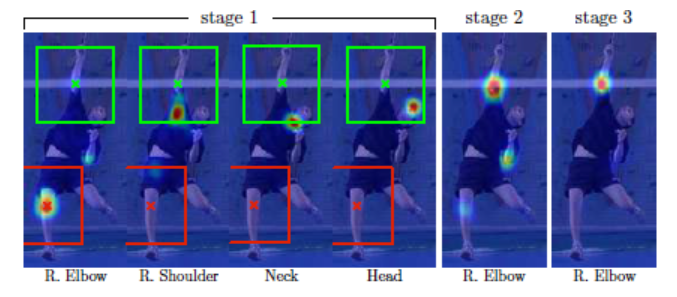
CPM 네트워크 구조를 사용하게 되면, stage가 진행될 수록 convolution layer 수가 증가하므로, receptive field는 점차 커지게 된다. Receptive field가 커지면, 그 만큼 넓은 영역을 참조하여 현재 위치의 belief map을 생성하게 된다. 이러한 특성으로 인하여, 특정 파트에 해당하는 belief map 생성 시, 다른 파트의 belief map에 해당하는 정보를 참조할 수 있게 되어 아래 그림 처럼 right elbow에 대한 belief map이 stage가 진행될 수록 보다 정교한 belief map으로 변화되는 모습을 볼 수 있다.

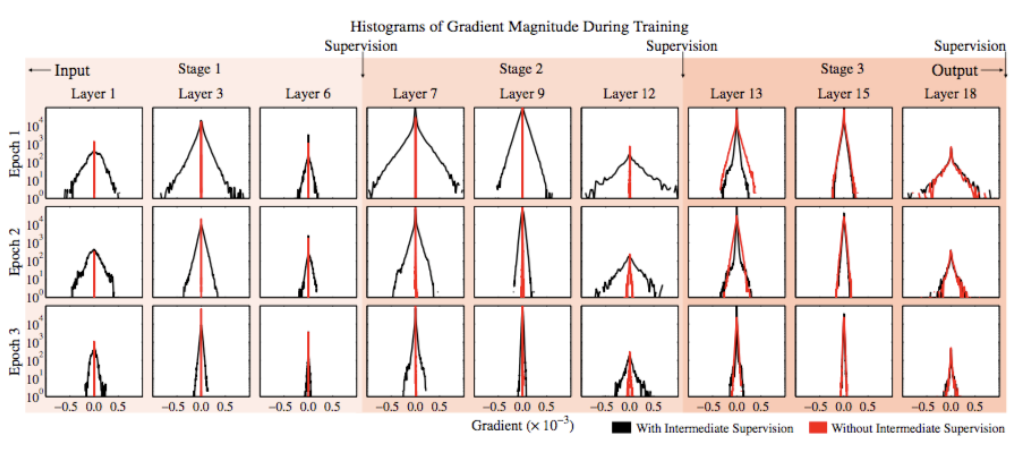
아래 그래프에서 receptive field size가 커질 수록 성능이 향상되는 것을 볼 수 있다. 또한, 위의 손실 함수는 deep neural network 중간 지점에 loss insertion 을 배치시키므로, gradient vanishing problem 을 완화시키는 효과가 있다. (참고로, GoogLeNet 도 유사한 방식으로 중간 레이어 위치에 손실을 강제 삽입하여 gradient vanishing problem 을 완화시킨다.)
우측으로 갈수록(layer가 깊어질수록) 확률분포가 좁아져 한 부분을 더욱 가리키고 있는 모습이고, output 부분은 학습이 진행될수록(Epoch이 커질수록) 넓은 범위를 예측했다가 점차 폭이 좁아지는 것을 알 수 있다.
본 연구의 보고에 의하면, 머리, 목, 어깨 등 고정적인 부분은 검출이 잘 되나, 팔, 다리 등 움직임이 많고 변화가 큰 부분은 검출이 어렵다고 한다. 그러나, 파트 간의 'consistent geometry' 가 있으므로, 고정적인 부분 (오른쪽 어깨) 이 변동적인 부분 (오른쪽 팔꿈치) 검출을 위한 ‘cue’ 를 제공할 수 있다 (예를 들어 오른쪽 어깨 파트가 오른쪽 팔꿈치 파트 검출을 위한 'cue' 를 제공할 수 있다). 이를 위해서는, receptive field 가 넓어야 한다. Convolution cascading 구조가 receptive field 를 넓혀주는 역할을 하고 있다. 아래 그림에서 stage 가 진행되면서 오른쪽 어깨가 오른쪽 팔꿈치를 검출하는데 필요한 정보를 제공하여 (엄밀히 말하면 이것은 연구자의 추정이다.) 오른쪽 팔꿈치를 보다 정교하게 추정하는 과정을 볼 수 있다.
Loss function
학습을 위한 손실 함수는 아래 수식과 같다. 각 stage에서 각 파트의 ground truth belief map과 추정한 belief map의 L2 norm를 손실한수로 설정하였다. 최종 손실함수는 모든 stage에서의 손실 함수를 더한 것으로 설정하였다.
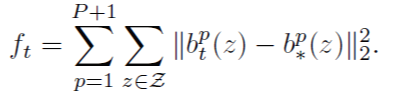
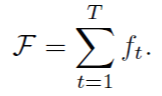
CODE
본 글의 내용은 링크의 코드를 기반으로 설명되어 있습니다. 크게 Model, Dataset, train, test 모듈로 구성되어있다. Model에서는 stage1, middle, stage2, stage3, stage4, stage5, stage6로 구성되어 있다. forward에서 stage에서 계산된 값이 다른 stage의 인자가 되어 계산된다. 아래 이미지를 확인하면 쉽게 이해할 수 있다.
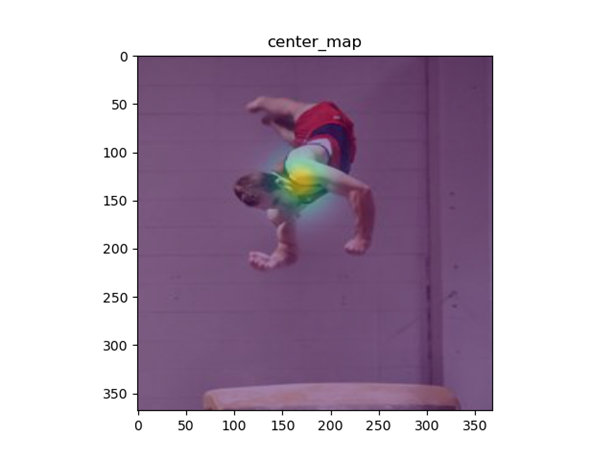
학습을 위한 Dataset의 경우 LSPet Dataset을 사용했으며 검증을 위해서는 LSP Dataset을 사용했다. 다른 Dataset을 사용하기 위해서는 코드 확장이 필요하다. Dataset은 traing을 위해 아래 이미지와 같이 image, center_map, 각 관절의 해당하는 46x46 image, 각 관절의 해당하는 46x46 Belief map이 만들어진다.


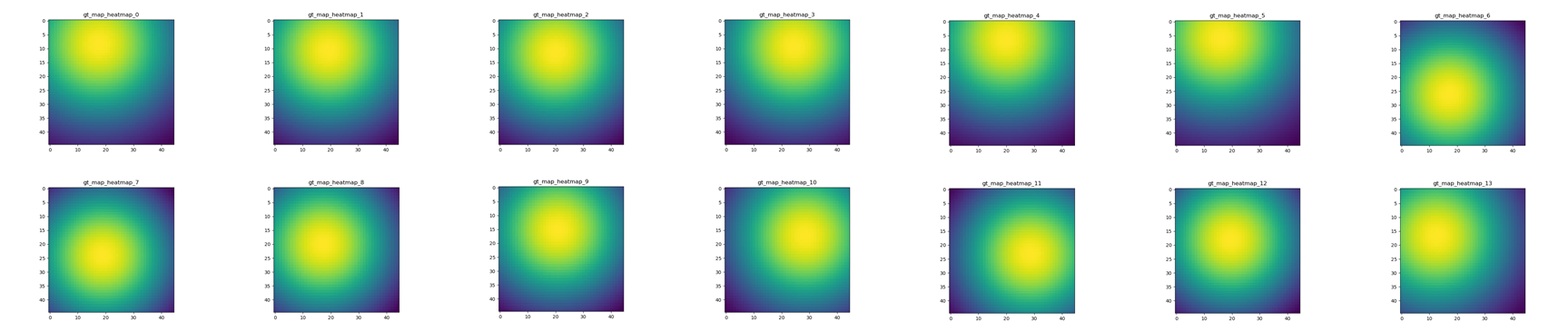
참고문헌
namedBen/Convolutional-Pose-Machines-Pytorch
Pytroch version of Convolutional Pose Machines. Contribute to namedBen/Convolutional-Pose-Machines-Pytorch development by creating an account on GitHub.
github.com
Convolutional Pose Machines · Issue #48 · chullhwan-song/Reading-Paper
https://arxiv.org/abs/1602.00134
github.com
Convolutional pose machines (CVPR 2016)
논문 제목: Convolutional pose machines 연구 기관: Carnegie Mellon University 본 연구는 아래 선행 연구의 후속 연구로써, 선행 연구의 전체 적인 기술 구조는 유사하게 적용하면서 선행 ...
kay7.blogspot.com