

☞ 문서의 내용은 가장 하단 참고문헌 및 사이트를 참고하여 필자가 보기 쉽도록 정리한 내용입니다.
☞ 틀린 내용 및 저작권 관련 문의가 있는 경우 문의하시면 수정 및 삭제 조치하겠습니다.
Class Activation Map
기존의 CNN에서 사용이 되는 모델은 Convolution Layer가 여러 겹 쌓여있고 마지막에 Fully-connected layer(FCL)로 이어져 분류하여 뛰어난 성능을 보여준다. 하지만 이렇게 FCL로 Flatten할 때 Convolution이 가지고 있던 각 픽셀들의 위치 정보를 잃게 된다. 따라서 분류 정확도가 아무리 좋아도 무엇을 보고 그 class를 판별했는지 알 수 없다. 본 논문에서는 FCL을 GAP(Global Average Pooling)로 변경하여 위치 정보를 잃지 않는 방법을 소개한다. (GAP를 사용하면 파라미터 수를 줄여 오버피팅을 방지 할 수 도 있다.)때문에 추가의 지도 학습 필요 없이 특정 위치를 구별하고 Heat Map을 생성할 수 있다. 이 방법을 사용하면 모델이 어떤 판단을 내려 output을 낼 때 어디에 집중하여 보았는지 볼 수 있기 때문에 Explainable(설명가능)한 결과를 낼 수 있다.

논문의 가장 중요한 핵심은 CAM이다. 이 CAM이 이루어지는 방식은 Conv Layer층 바로 다음 GAP을 붙이고 softmax를 붙이는 모델 구조이다. 아래 그림은 CAM의 네트워크 구조를 보여준다. 우선 기본적인 구조는 CNN과 비슷하다. 하지만 결정적인 차이점은 마지막 FCL로 Flatten하지 않고, GAP을 통해 새로운 Weight를 만들어 낸다. 마지막 Conv Layer가 총 n개의 channel로 이루어져 있다면, 각각의 채널들을 GAP을 통해 하나의 Weight 값으로 나타내고, 총 n개의 Weight들이 생긴다. 그리고 마지막에 Softmax 함수로 연결 돼 이 Weight들도 역전파를 통해 학습을 시킨다. CAM은 이 Weight들을 마지막 n개의 Conv Layer들과 Weighted Sum을 해주면, 하나의 특정 클라스 이미지의 Heat Map이 나오게 된다. 아래 그림의 Heat Map은 이미지 오른쪽 하단에 중요도가 표시되는 것을 볼 수 있다. 이 class의 이름은 Australian terrier 즉 개의 한 종류인데, 원래 이미지를 보면 개의 몸과 얼굴 보고 판단했다는 것을 확인 할 수 있다.

Global Average Pooling
Global Average Pooling은 마지막 convolutional layer에 적용하는 방식으로, 각 Feature map의 평균값을 뽑아 벡터를 만든다. 이해를 돕기 위해 마지막 conv layer의 피쳐맵 개수가 3개고 각각의 크기가 3x3이라고 해보자.

위 예시에서 GAP(Golbal Average Pooling)는 각 Feature map에 대해 모든 값을 더하고, GMP(Global Max Pooling)는 모든 값 중 최대값을 골라 벡터를 만든다. 사실 평균(Average)을 취하면 1+2+1을 한 후 9로 나눠줘야 맞겠지만, 논문 상에서는 합으로 처리되어있다. 어차피 같은 레이어의 모든 피쳐맵은 x, y 개수가 동일하므로 굳이 나눠주지 않아도 되는 것으로 이해했다.
Class Activation Mapping
논문에서 GAP를 사용해서 CAM을 도출하는 일련의 과정을 살펴보자. $f_k(x,y)$는 마지막 Convolutional layer의 k번째 유닛의 활성화를 표현한다. 즉, 위 그림에서 첫 번째 유닛인 붉은색 표가 $f_1(x,y)$가 된다. k번째 유닛에 대해서 GAP를 씌운 값은 $F^k$가 된다. 즉, GAP를 통해 계산한 붉은색 값 4가 $f^1$이 된다. 여기부터 조금 복잡해지는, $w_k^c$를 $f_k$에 곱하고 이를 모두 더해 소프트맥스 레이어에 집어넣을 input인 $S_c$를구한다. 우리가 예측할 클래스의 개수가 3개라고 가정해보면 사실 다음과 같이 간단히 생각할 수 있다.

클래스 1 ,2, 3 중에서 우리가 관심있는 클래스가 1이라고 생각해보자. 그러면 우리의 소프트 맥스 인풋은 $S_1$이 되고, 이를 산출하는 공식은 $∑_k w_k^{c}f_k$이 된다. 여기서 k는 1,2,3이므로 이 summation을 다시 풀어서 쓰면 $w_1^{1}F_1 + w_2^{1}F_2 + w_3^{1}F_3$이 되고, 위 그림에서 각 수식에 맞는 값을 끼워보면 $2*4+1*3+0*1$이 되어서 결국 $S_1$은11이된다. $S_c$를 구했다면 이제 이를 소프트맥스 공식에 넣어서 클래스 c의 분류 확률을 구하게 된다.
Global Avg. Pooling (GAP) vs Global Max Pooling(GMP)
마지막 Conv Layer GMP와 GAP를 사용했을 때 중요하다고 보는 부분의 하이라이트 위치가 다르다. GAP 은 네트워크가 특정 object 의 전체적인 분포를 구분할 수 있도록 도와주는 반면(2x2기준이라고 생각한다면 4개의 값 중 하나만을 활용 네트워크가 대상의 범위를 식별하도록 장려하여 점수들이 반영됨), GMP 은 가장 높은 특정 분포들만 구분할 수 있도록 도와준다.(가장 판별적인 영역을 제외한 모든 이미지 영역에서 낮은 점수는 점수 영향에 미치지 않음) Classification Task 에서는 둘의 성능이 비슷하지만, Localization Task 에서는 GAP 가 더 좋은 결과를 낸다.
Full Code
코드는 pytorch로 구현했습니다. 원본 코드는 링크를 통해 참고 할 수 있습니다. 아래 코드는 학습된 VGG19.pt를 사용했습니다. VGG코드는 링크를 통해서 확인 할 수 있습니다.
import os
os.environ['KMP_DUPLICATE_LIB_OK']='True'
import torch
import torchvision
import torchvision.transforms as transforms
import skimage.transform
import numpy as np
import torch.nn as nn
import matplotlib.pyplot as plt
transform = transforms.Compose([
transforms.Resize(224),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
trainset = torchvision.datasets.STL10(root='./data', split='train', download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
testset = torchvision.datasets.STL10(root='./data', split='test', download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=False)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv = nn.Sequential(
#3 224 128
nn.Conv2d(3, 64, 3, padding=1),nn.LeakyReLU(0.2),
nn.Conv2d(64, 64, 3, padding=1),nn.LeakyReLU(0.2),
nn.MaxPool2d(2, 2),
#64 112 64
nn.Conv2d(64, 128, 3, padding=1),nn.LeakyReLU(0.2),
nn.Conv2d(128, 128, 3, padding=1),nn.LeakyReLU(0.2),
nn.MaxPool2d(2, 2),
#128 56 32
nn.Conv2d(128, 256, 3, padding=1),nn.LeakyReLU(0.2),
nn.Conv2d(256, 256, 3, padding=1),nn.LeakyReLU(0.2),
nn.Conv2d(256, 256, 3, padding=1),nn.LeakyReLU(0.2),
nn.MaxPool2d(2, 2),
#256 28 16
nn.Conv2d(256, 512, 3, padding=1),nn.LeakyReLU(0.2),
nn.Conv2d(512, 512, 3, padding=1),nn.LeakyReLU(0.2),
nn.Conv2d(512, 512, 3, padding=1),nn.LeakyReLU(0.2),
nn.MaxPool2d(2, 2),
#512 14 8
nn.Conv2d(512, 512, 3, padding=1),nn.LeakyReLU(0.2),
nn.Conv2d(512, 512, 3, padding=1),nn.LeakyReLU(0.2),
nn.Conv2d(512, 512, 3, padding=1),nn.LeakyReLU(0.2),
nn.MaxPool2d(2, 2)
)
#512 7 4
self.avg_pool = nn.AvgPool2d(7)
#512 1 1
self.classifier = nn.Linear(512, 10)
"""
self.fc1 = nn.Linear(512*2*2,4096)
self.fc2 = nn.Linear(4096,4096)
self.fc3 = nn.Linear(4096,10)
"""
def forward(self, x):
#print(x.size())
features = self.conv(x)
#print(features.size())
x = self.avg_pool(features)
#print(avg_pool.size())
x = x.view(features.size(0), -1)
#print(flatten.size())
x = self.classifier(x)
#x = self.softmax(x)
return x, features
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
load_path="./data/stl10_binary/pth/Vgg19.pt"
net = torch.load(load_path)
net = net.to(device)
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy() #넘파이 배열로 변환
plt.imshow(np.transpose(npimg, (1, 2, 0))) #요소의 위치 이동(이미지 회전)
for data in testloader: #testloader에서 data로 값을 넘겨주면서 for문을 돈다.
images, labels = data #이미지 정보와, 라벨 정보를 넣어준다.
images = images.cuda()
labels = labels.cuda()
outputs, f = net(images)
#torch.max 함수는 주어진 텐서 배열의 최대 값이 들어있는 index를 리턴하는 함수이다.
#뒤에 들어가는 1은 dimension에 대한 것이다. 값을 한번에 넣어주고 예측한 값을 받아와야 한다.
# 하지만 어떤 단위로 max값을 받아올 것인지 정해주지 않으면 그냥 max 함수는 전체의 element 중 최대의 인덱스를 리턴한다.
_, predicted = torch.max(outputs, 1) #배열에 정답이 담긴다.
break
classes = ('airplance', 'bird', 'car', 'cat', 'deer', 'dog', 'horse', 'monkey', 'ship', 'truck')
params = list(net.parameters())
num = 0
for num in range(64):
print("ANS :",classes[int(predicted[num])]," REAL :",classes[int(labels[num])],num)
#print(outputs[0])
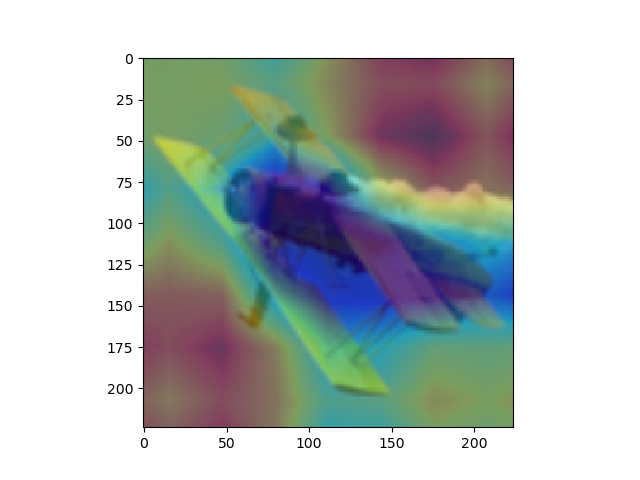
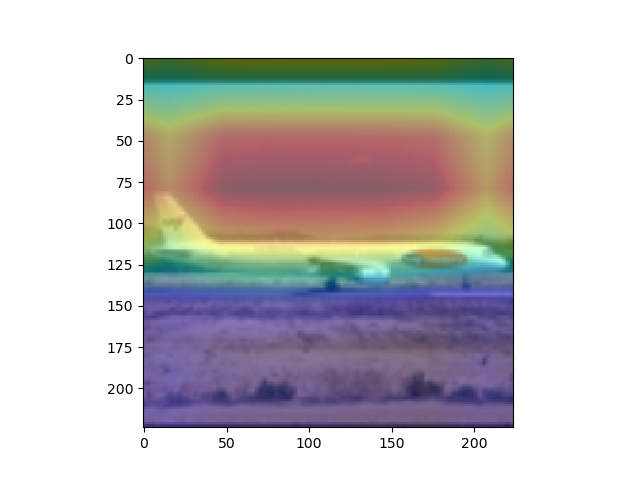
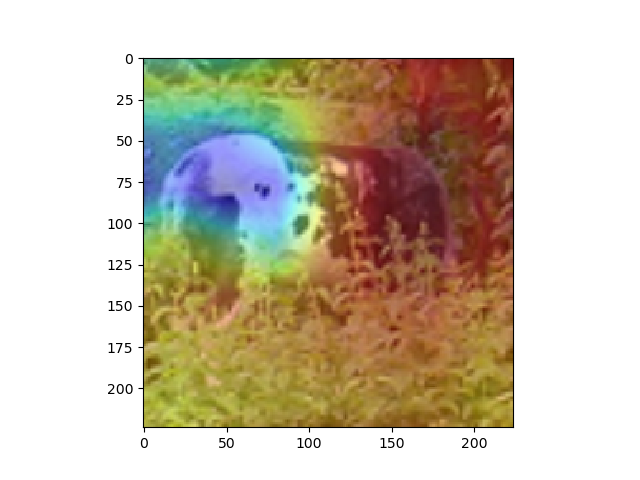
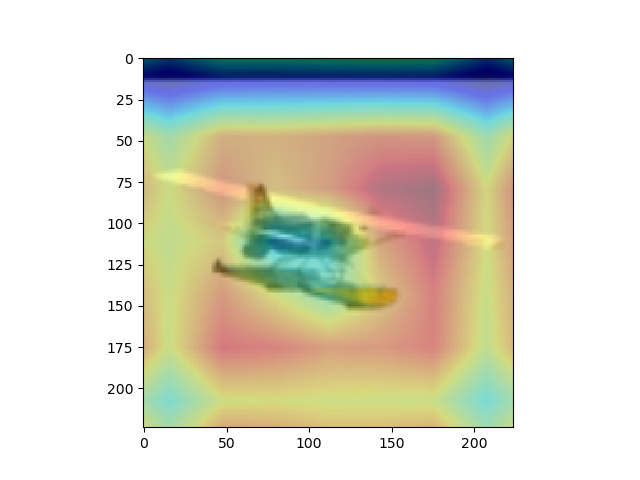
overlay = params[-2][int(predicted[num])].matmul(f[num].reshape(512,49)).reshape(7,7).cpu().data.numpy()
#params[-2]는 뒤에서 부터 두 번째 레이어이다. 이는 512x1 input을 받는 FC레이어의 weight 값들이다. 즉 512x1의 크기를 가진다.
#이것과 matmul(행렬곱)을 하는 f[num]은 512개의 채널을 가지는 7x7행렬들이다. 이를 512x49로 리쉐잎을 하는 이유는 행렬곱이 2차원 행렬 끼리의 곱만 지원하기 때문이다.
#마지막으로 이것을 cpu로 바꿔주고 넘파이로 바꿔주며 끝을 낸다. cpu로 바꿔주지 않고 numpy로 바꿀 경우 오류가 나게 된다.
#Scaling
overlay = overlay - np.min(overlay)
overlay = overlay / np.max(overlay)
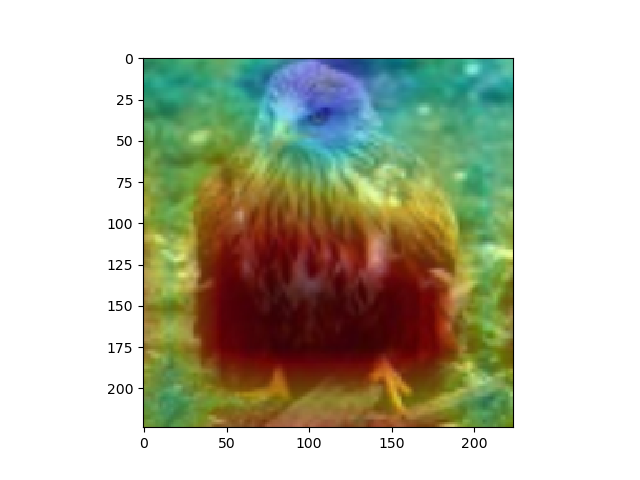
imshow(images[num].cpu()) #RealImage
skimage.transform.resize(overlay, [224,224])
plt.imshow(skimage.transform.resize(overlay, [224,224]), alpha=0.4,cmap='jet') #Hitmap
plt.show() #RealImage + HitMap show
#윗 부분을 통해 이미지를 출력하게 된다. 먼저, imshow로 원본 이미지를 출력해 주고, 같은 팔레트에 위에서 계산한 overlay(cam 값)을 그려준다.
#이를 위해, 이미지와 같은 크기(224x224)로 리사이징을 하고, imshow의 argument값에 alpha값을 0.4로 설정해 주어 반투명 하게 덮어씌워주도록 한다.
#여기서 주의하여야 하는 점은, plt.show()를 해야 현재 팔래트를 화면에 출력하고 새로운 팔래트를 준비한다는 점이다.
imshow(images[num].cpu())#RealImage
plt.show() #RealImage show

참고 자료
CAM: 대선주자 얼굴 위치 추적기
a novice's journey into data science
jsideas.net
Class Activation Map (CAM) 논문 요약/리뷰
[Learning Deep Features for Discriminative Localization] 1. Introduction 보통 CNN의 구조를 생각해보면, Input - Conv Layers - FC Layers 으로 이루어졌다. 즉, CNN은 마지막 컨벌루션 레이어를 FC-Layer..
jays0606.tistory.com
[논문정리]Learning Deep Features for Discriminative Localization (CAM)
Learning Deep Features for Discriminatvie Localization Bolei Zhou, Aditya Khosal, Agata Lapedriza, Aude Oliva, Antonio Torralba Computer Science and Artificial Intelligence Laboratory, MIT Abstract..
dydeeplearning.tistory.com