

☞ 문서의 내용은 가장 하단 참고문헌 및 사이트를 참고하여 필자가 보기 쉽도록 정리한 내용입니다.
☞ 틀린 내용 및 저작권 관련 문의가 있는 경우 문의하시면 수정 및 삭제 조치하겠습니다.
네트워크의 성능을 향상하는 직관적인 방법은 네트워크의 크기를 늘리는 것이다. 이 크기는 보통 넓이와 깊이를 의미하며 넓이는 노드의 개수(파라미터의 개수)를 의미하며 깊이는 레이어의 계층 수를 말한다. 다시 말해 성능을 올리고 싶으면 노드 수를 늘리고 레이어를 많이 쌓으면 된다. 하지만 무작정 네트워크의 크기를 늘린다고 성능이 좋아지지 않는다.
큰 네트워크는 구조적으로 두 가지 문제점을 가지게 된다. 첫 번째로 많은 파라미터를 가지게 된다. 파라미터의 개수가 많아지면 Over fitting 일어날 가능성이 높다. 두 번째 문제는 네트워크가 커질수록 컴퓨터가 처리해야 하는 리소스가 기하급수적으로 늘어난다는 것이다. 당시에는 이런 문제를 해결하기 위해 Dropout을 이용하였다. 그러나 이를 통해서도 완전히 해결된 것이 아니었다. 이에 GoogleNet은 구조 자체를 변경하여 문제점을 해결하였다.
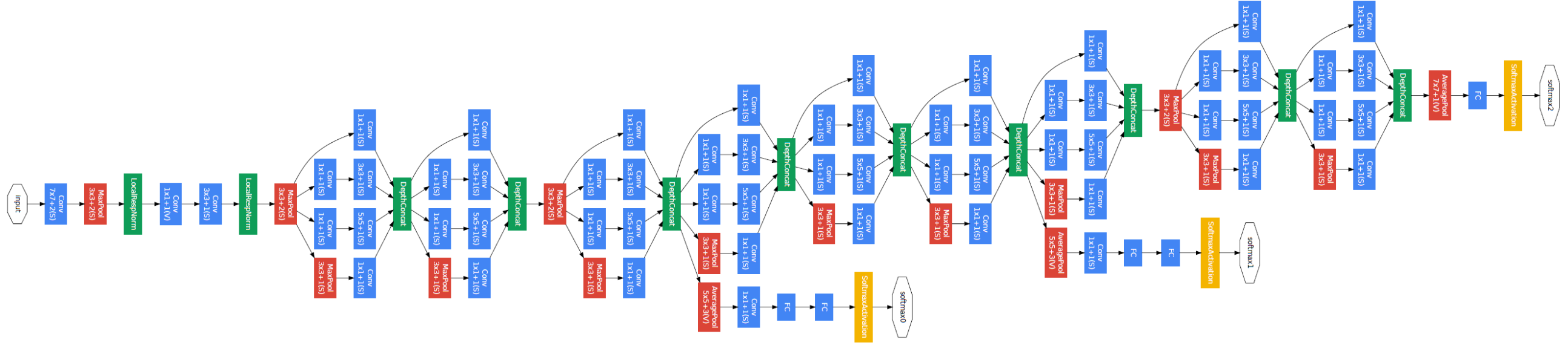
GoogleNet의 Architecture를 살펴보면 22개층으로 구성되어 있다. 먼저 주목해야 하는 것은 1x1사이즈의 filter로 convolution 해주는 것을 볼 수 있다. 1x1 convolution은 feature map의 개수를 줄이는 목적으로 사용된다. (feature map 개수가 줄어들면 그만큼 연산량이 줄어든다. )
14 x 14 x 480의 feature map이 있다고 가정해보자, 1x1 convolution을 사용하지 않을 때는 48개의 5x5x480의 filter로 convolution을 하며 이때 필요한 연산 횟수는 (14x14x48) x (5x5x480) = 112.9M이 된다. 1x1 convolution을 사용하면 먼저 16개의 1x1x480의 filter로 convolution을 해줘 feature map의 개수를 줄인다. 그리고 이 feature map에 48개의 5x5x16의 filter로 convolution 해준다. 이때 필요한 연산 횟수는 (14x14x16) x (1x1x480)+(14x14x48) x(5x5x16) = 5.3M이다. 1x1 convolution을 사용할 때 더 적은 연산량을 가지는 것을 확인할 수 있다. 연산량을 줄일 수 있다는 것은 네트워크를 더 깊이 만들 수 있다는 뜻이다.

Inception Module
Inception Module에서는 3가지 종류의 크기를 가진 filter가 존재한다. 1x1 Convolution은 Input image의 공간적 정보를 담고, 3x3 그리고 5x5 Convolution은 추상적이고 퍼져있는 정보를 보존한다. 아래 그림 (b)를 보면 1x1 convolution 이 각 filter에도 적용되어 있는 것을 볼 수 있다. 이는 위에서 설명한 것과 같이 feature map 개수 감소의 효과를 보기 위한 것이다. 또한 filter의 개수를 input image보다 적게 설정하여 이미지의 크기를 줄이는 것이 가능하다.(Pooling 효과를 볼 수 있다.)
Inception Module이 서로 다른 필터를 통해 연산결과들의 합을 output image로 추출하는 데에도 명확한 이유가 존재한다. 실제로 컴퓨터 연산 (CPU, GPU 등)은 Dense 한 연산을 처리하는데 최적화되어 있다. Dropout과 같은 sparse 한 연산과정을 도입하고자 하면, 정확도 면에서는 이득을 보게 되지만 리소스 사용이 비효율적인 면을 띠게 된다. Googlenet에서 낸 결론은, 전체적인 구조 면에서는 Sparse한 구조를 갖되 실제 연산 과정은 Dense 한 과정을 거치도록 하자는 것이다.

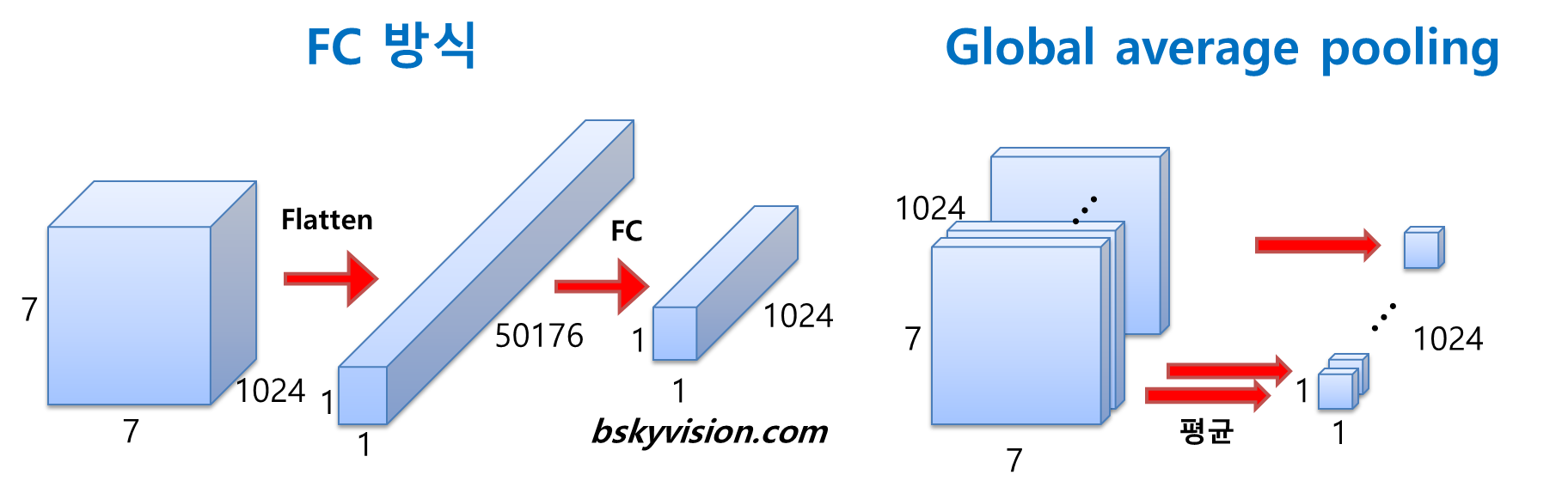
Global average pooling
Googlenet은 FC(Fully Connected) 방식 대신에 GAP(Global Average Pooling)이란 방식을 사용한다. GAP는 전 층에서 산출된 Feature map들을 각각 평균 낸 것을 이어서 1차원 벡터로 만들어주는 것이다. GAP의 이점은, 바로 학습 과정이 필요하지 않다는 점이다. 이는 GAP가 단지 Pooling이기 때문이다. Pooling은 학습과정이 아니기 때문에, 어떠한 파라미터도 추가로 발생하지 않는다. 실제로는 GAP 이후에는 Fc layer가 추가 되었지만, 이는 연산의 효과를 누리기보다는 label에 더 쉽게 접근하기 위해 삽입되었다.
Auxiliary classifier
Auxiliary Classifier는 깊은 네트워크의 학습에 대한 우려에 의해 추가되었습니다. 네트워크 깊이가 깊어지면 깊어질수록 Vanishing Gradient의 문제를 피하기 어려워진다. 때문에 파라미터의 갱신이 잘 되지 않을 가능성이 존재한다. 이를 피하기 위해, GoogLeNet에서는 연산 도중에 있는 Image를 분류한다. 이렇게 연산 도중에 분류를 실행하게 되면, Vanishing Gradient의 걱정을 조금은 줄일 수 있게 된다. 네트워크 중간에 두번의 Auxiliary classification이 합쳐져 신경망 학습이 이루어진다. 이 Auxiliary classifier는 어디까지나 학습의 용이를 위해 마련되었으므로, 학습이 완료된 후엔 네트워크에서 삭제된다.
Network Structure
GoogleNet은 4개의 구조로 나눌 수 있다. 첫 번째로 Pre-layer, 두 번째로 Inception Layers, 세 번째로 Globar Average Pooling, 네 번째로 Auxiliary Classifier가 있다. Pre-layer 계층은 초기 학습을 위해 존재하는 구간이다. 인셉션 모듈은 저층에서의 학습 효율이 떨어지기 때문에, 학습의 편의성을 위해 추가되었다. 이 구간에서는 일반적인 CNN연산을 거친다. 다음으로 인셉션 모듈 계층이다. GoogleNet에서는 총 아홉 번의 인셉션 모듈을 겹쳐 총 22층의 깊은 레이어를 구성했다. 이렇게 큰 네트워크를 구성하면서도, AlexNet과 비교하여 12배나 적은 파라미터가 사용되었다.


참고문헌
GoogLeNet - POD_Deep-Learning
GoogLeNet 1. 들어가기 GoogLeNet은 2014년에 ILSVRC14에서 우승한 모델입니다. 같은 대회에서 발표되어 주목받은 다른 모델로는 2위를 차지한 VGGNet이 있는데, 둘 다 Lin의 Network in Network(NIN)의 영향을 받
poddeeplearning.readthedocs.io
[CNN 알고리즘들] GoogLeNet(inception v1)의 구조
LeNet-5 => https://bskyvision.com/418 AlexNet => https://bskyvision.com/421 VGG-F, VGG-M, VGG-S => https://bskyvision.com/420 VGG-16, VGG-19 => https://bskyvision.com/504 GoogLeNet(inception v1) =>..
bskyvision.com