

☞ 문서의 내용은 가장 하단 참고문헌 및 사이트를 참고하여 필자가 보기 쉽도록 정리한 내용입니다.
☞ 틀린 내용 및 저작권 관련 문의가 있는 경우 문의하시면 수정 및 삭제 조치하겠습니다.
요약
기존 딥러닝 방법의 대부분은 2차원 Depth map에서 손 또는 인체 관절과 같은 Key point의 3차원 좌표를 2차원 컨볼루션 신경망을 통해 직접 회귀하는 프레임 워크를 기반으로 한다. 이 접근 방식은 두 가지 약점을 가지고 있다. 첫 번째는 2D Depth map에 원근 왜곡이 있다는 것이다. Depth map은 본질적으로 3차원 데이터이지만 3차원에서 2차원 공간으로의 투영된 2차원 이미지이다. 이는 Perspective Distortion문제를 일으킬 수 있다. 두 번째는 2차원 이미지에서 3차원 좌표를 직접 회귀하는 것이 매우 비선형적이므로 학습 절차에 어려움이 있다. 이에 논문에서는 기존 방법들의 한계를 극복하기 위해 기존에 사용되던 입력 형태와 출력 형태를 변경했으며 encoder-decoder 형식의 3D CNN으로 네트워크를 변경했다. 이로 인해 제안하는 모델은 3개의 3D hand pose estimation dataset, 1개의 3D human pose estimation dataset에서 가장 높은 성능을 내었다. 또한 ICCV 2017에서 주최된 HANDS 2017 challenge에 우승했다.
기존 논문의 문제점과 제안 방법
첫 번째 : 2D 깊이 이미지 원근 왜곡
2D 깊이 맵의 픽셀 값은 깊이 카메라에서 물체 지점의 물리적 거리를 나타내므로 깊이 맵은 본질적으로 3D 데이터이다. 그러나 대부분의 방법은 깊이 맵을 2D 이미지 형식으로 사용한다. 때문에 2D 이미지 공간의 값을 투영하여 3D 공간에 실제 개체의 모양을 만든다면 왜곡될 수 있다. 따라서 네트워크는 왜곡된 객체를 보고 perform perspective distortion-invariant을 수행해야한다.

3D 포인트 클라우드는 3D Pose와 일대일 관계가 있지만 2D 깊이 이미지는 원근 왜곡으로 인해 다대일 관계가 있다. 따라서 네트워크는 perform perspective distortion-invariant 한 수행을 해야한다. 2D 깊이 맵은 3D 포인트 클라우드를 ∆X = -300, 0, 300mm (왼쪽에서 오른쪽으로) 및 ∆Y = -300, 0, 300mm (아래에서 위로)로 변환하여 생성된다. 모든 경우에 ∆Z는 0mm로 설정된다.
두 번째 : Depth map과 3D 좌표간의 Nonlinear Mapping
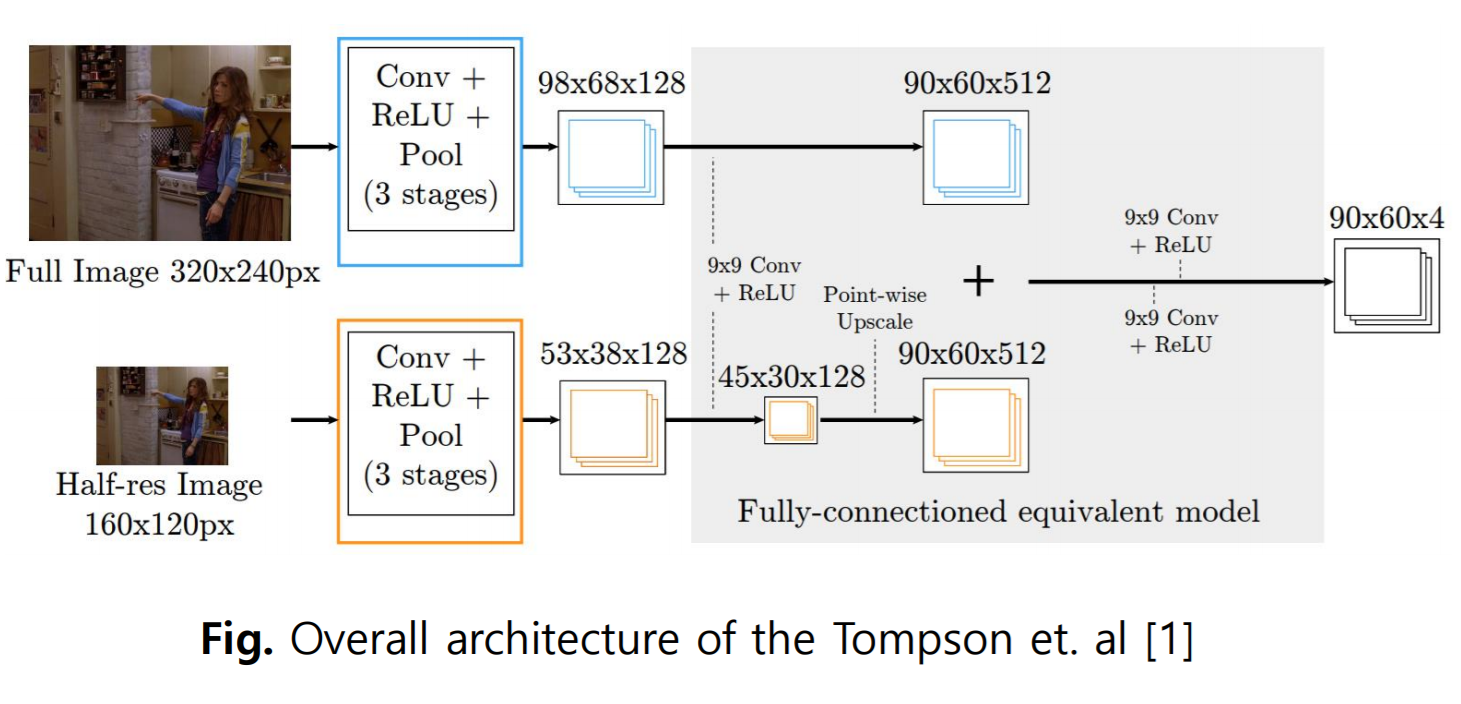
Tompson et.al은 이미지와 key point 좌표간의 mapping이 매우 비선형이라고 주장했다. Nonlinear Mapping은 학습 절차를 방해하고 네트워크가 키포인트의 좌표를 정확하게 추정하지 못하게 한다. 이 높은 비선형 성은 각 키포인트에 대해 하나의 3D 좌표 입력에서 회귀해야 한다는 사실에 기인한다. (기존의 방식은 일대일 mapping이 되지 않는다. / 2D 깊이 이미지는 원근 왜곡으로 인해 다대일 관계가 있다.) 네트워크에 대한 픽셀당 likelhood(가능도 또는 우도)를 감독하는 것이 더 정확한 결과를 주었다. 때문에 3차원 좌표 대신 voxel likelihood를 추정한다.
"우도(likelihood = L(Θ;w|x) 란 이미 주어진 표본데이터(X)들에 비추어 봤을 때 모집단의 parameter인 가중치(w)에 대한 추정이 그럴듯한 정도를 가리키며, 미지의 가중치(=parameter)값인 확률분포에서 뽑은 X값들을 바탕으로 우도를 가장 크게 해주는 추정방식을 Maximum Likelihood Estimation 이라고 한다" 출처 : 89douner.tistory.com/21
제안방법
이러한 한계에 대처하기 위해 포즈 추정을 위한 V2VPoseNet을 제안한다. 이전 방법과 달리 V2V은 복셀화된 그리드를 입력으로 사용하고 각 키포인트에 대한 복셀별 가능성을 추정한다. 입력 2D Depth map을 3D 복셀 형식으로 변환함으로써 네트워크는 원근 왜곡없이 물체의 실제 모양을 볼 수 있다. 또한 각 키포인트의 복셀 별 가능성을 추정하면 입력에서 직접 3D 좌표를 추정하는 Nonlinear Mapping보다 네트워크가 원하는 작업을 더 쉽게 학습할 수 있다.
Input , OutPut
사람의 hand , body의 pose를 추출하는 방식은 아래 그림과 같이 4가지가 존재한다. 어떤 input data를 사용해서 어떤 output을 내느냐에 따라 달라진다. 본 논문에서는 기존의 단점을 해결하기 위해 아래 그림의 (d)에서 보여지는 것 처럼 2D Depth map에서 직접 3D 좌표를 회귀하는 것이 아니라 복셀화 된 그리드 입력에서 복셀 당 likelihood를 추정한다.

V2VPoseNet
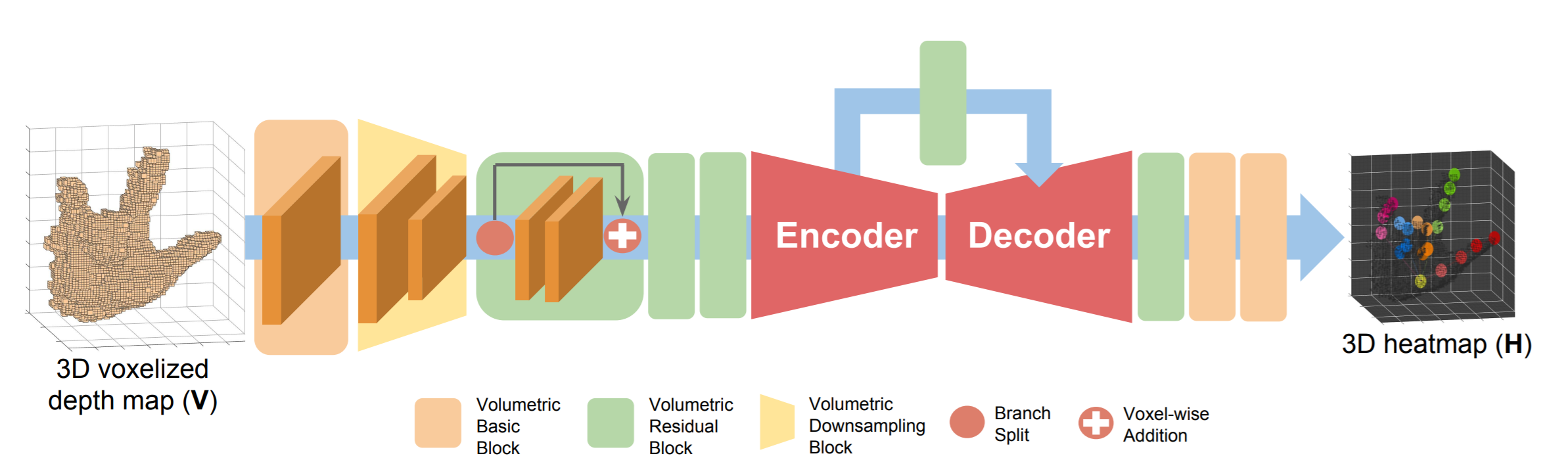
V2VPoseNet의 구조는 아래 그림과 같으며 크게 4종류의 블럭이 존재한다. 첫 번째는 Volumertic basic block으로 Voxel 배치 정규화 및 활성화 함수(ReLU)로 구성된 블록이다. 두 번째는 volumetric residual block은 2D 잔차 블록에서 확장된 복셀 잔차 블록이다. 세 번째는 volumetric downsampling block 은 복셀 최대 풀링 레이어와 동일한 복셀 다운 샘플링으로 구성된 블록이다. 네 번째는 volumetric upsampling block은 레이어, 복셀 배치 정규화 레이어 및 활성화 함수로 구성된 복셀 업 샘플링 블록이다. 논문의 목표는 모든 키포인트의 3D 좌표를 추정하는 것이다. 먼저 3D 공간의 점을 재투영하고 연속 공간을 이산화하여 2D 깊이 이미지를 3D 복셀 형식으로 변환한다. 2D 깊이 이미지를 복셀화 한 후 V2VPoseNet은 3D 복셀화된 데이터를 입력으로 가져와 각 키포인트에 대한 복셀 별 likelihood을 추정한다. 각 키포인트에 대한 가능성이 가장 높은 위치가 식별되고 실제 좌표로 변경하여 모델의 최종 결과가 된다.
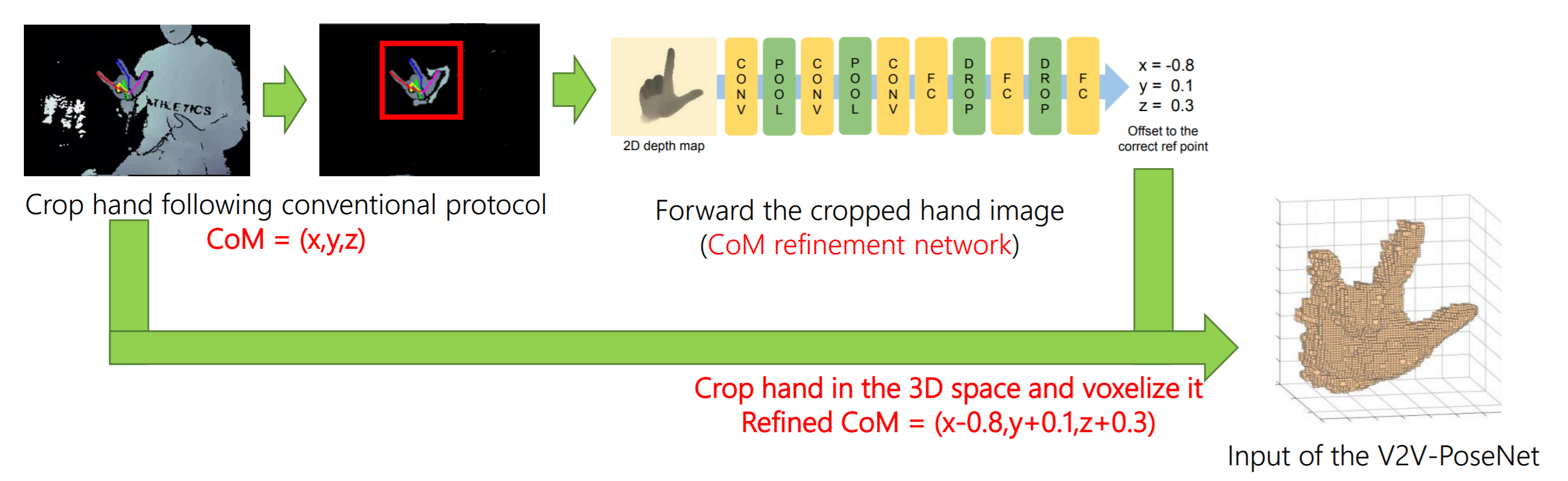
손 또는 인체 관절과 같은 키포인트를 localization하려면 3D 공간에 손이나 인체가 포함된 Cubic box가 필요하다. 이 Cubic Box는 일반적으로 기준점 주위에 배치되며, 이는 ground truth joint 위치 또는 손 영역 주위의 단순한 깊이 임계값 이후 질량 중심을 사용하여 얻습니다. 그러나 실제 응용 프로그램에서는 ground truth joint 위치를 활용하는 것이 불가능합니다. 또한 일반적으로 단순 깊이 임계값으로 계산된 질량 중심을 사용한다고 해도 어수선한 장면에서 질량 중심 계산 오류로 인해 획득한 Cubic Box에 객체가 올바르게 포함된다는 보장은 없습니다. 예를 들어, 다른 객체가 대상 객체 근처에 있는 경우 단순 깊이 임계값 방법은 모든 입력 데이터에 동일한 임계값을 적용하므로 다른 객체를 제대로 필터링할 수 없습니다. 따라서 계산된 질량 중심이 잘못되어 아래 그림 처럼 대상 물체의 일부만 포함하는 Cubic box가 생성됩니다.

본 논문에서는 이러한 한계를 극복하기 위해 Oberweger [29]가 제안한 간단한 2D CNN을 훈련시켜 아래 그림 처럼 보정한다. 그림에서 처럼 먼저 기존의 방식을 통해 특정 부분을 잘라내고 해당 부분의 center를 찾는다. 해당 부분을 2D Depth 이미지로 변환한 후 모델에 입력 값으로 넣어 center의 위치가 옮겨가야하는 offset값을 받는다. 이렇게 보정된 center를 중심으로 정해진 크기 만큼 crop한다.

이렇게 찾아낸 손 부분을 V2V posenet에서 입력값으로 사용할 voxel 형태로 바꿔준다. 기존에 입력으로 받았던 이미지는 2d depth 이미지, 위 그림에서 가장 왼쪽 있는 사진이다. 해당 이미지를 실제 depth 값을 기반 해서 3d 상으로 값을 옮겨줘야 한다. 특정 voxel 공간에서 해당 좌표에 손의 부분이 위치하면 1, 그렇지 않으면 0으로 채워준다.
V2V-PoseNet은 Voxel-Voxel 예측을 수행한다. 따라서 커널 모양이 w x h x d가 되도록 z축을 공간 축으로 처리하는 3D CNN 아키텍처를 기반으로 한다. 우리의 네트워크 아키텍처는 보다 정확한 추정을 위해 수정된 Stacked hourglass networks을 기반으로 한다. 아래 그림에서 볼 수 있듯이 네트워크는 7x7x7 volumetric basic block과 volumetric downsampling block에서 시작된다. feature map을 다운 샘플링한 후 세 개의 연속적인 residual block이 유용한 로컬 feature를 추출한다. 잔여 블록의 출력은 아래 그림에서 설명된 인코더와 디코더를 통과한다.
Encoder에서 Volumetric Downsampling Block은 feature 맵의 공간 크기를 줄이는 반면 Volumetric residual block은 채널 수를 증가시킵니다. 이러한 채널 수의 증가가 실험의 성능을 개선하는데 도움이 되는 것으로 경험적으로 확인되었습니다. 한편, Decoder에서 Volumetric Upsampling Block은 feature 맵의 공간 크기를 확대합니다. Upsampling할 때 네트워크는 추출된 특징을 압축하기 위해 채널 수를 줄입니다. Decoder에서 복셀 크기를 확대하면 feature 맵에서 복셀 사이의 보폭이 줄어들기 때문에 네트워크가 key point를 조밀하게 지역화하는 데 도움이 됩니다. Encoder와 Decoder는 각 스케일에 대한 복셀 단위 추가로 연결되어 Decoder가 feature 맵을 보다 안정적으로 Upsampling할 수 있습니다. Encoder와 Decoder를 통해 입력을 전달한 후 네트워크는 2 개의 1x1x1 volumetric basic block과 1 개의 1x1x1 volumetric convolutional layer를 통해 각 키포인트에 대한 복셀 별 likelihood을 예측합니다.

Network training
각 Key Point에 대한 Voxel 별 likelihood를 구하기 위해 3D heatmap을 생성한다. 여기서 Gaussian peak의 평균은 다음과 같이 ground truth joint에 위치한다. 여기서 H*n은 n번째 Key Point의 Ground truth이고 (in, jn, kn)은 n번째 Key Point의 ground truth Voxel 좌표이다. σ = 1.7는 Gaussian peak의 표준 편차이다.

또한 다음과 같이 손실 함수 L로 평균 제곱 오차를 채택한다. 여기서 H*n 및 Hn은 각각 n 번째 Key Point에 대한 ground truth 및 추정 Heatmap이고 N은 Key Point 수를 나타냅니다.

코드와 데이터 셋
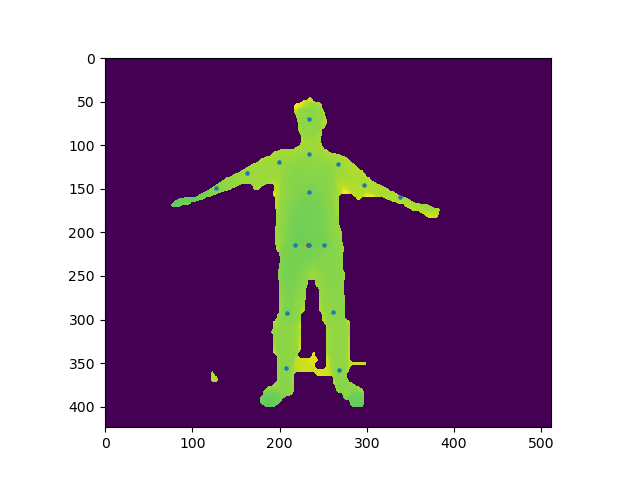
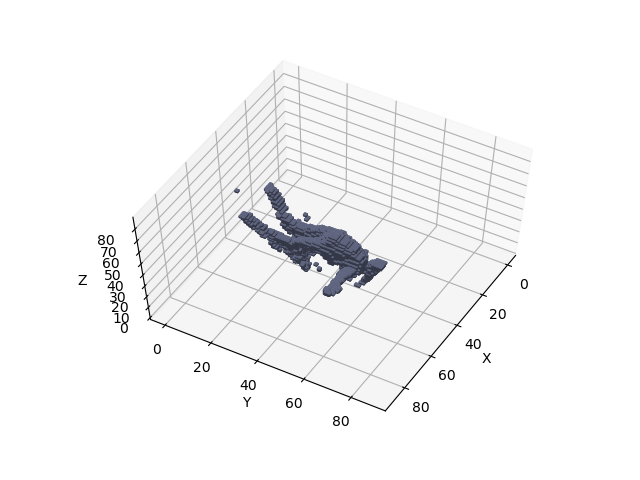
본 논문에서 사용하는 데이터셋은 다음과 같다. ICVL Hand Posture Dataset, NYU Hand Pose Dataset, MSRA Hand Pose Dataset, HANDS 2017 Frame-based 3D Hand Pose Estimation Chaalenge Dataset, ITOP Human Pose Dataset Human Pose Dataset인 ITOP 데이터셋을 제외하고는 모두 Hand Pose Dataset이다. official 코드는 lua와 torch7으로 구현이 되어있다. 코드는 링크를 이용하여 확인 할 수 있다. non offcial로 pytorch로 구현된 코드가 있으나 MSRA Hand Pose Dataset의 코드만 구현했다. 때문에 다른 dataset을 사용하기 위해서는 코드 수정이 필요하다. 코드는 링크를 이용하여 확인 할 수 있다. 필자의 경우 non-offcial로 만들어진 pytorch 버전을 이용하여 ITOP 데이터셋과 필자가 만든 KINECT V2의 데이터셋을 이용하여 실험 결과 아래 이미지와 같이 복셀화가 진행되었고 Pose estimation 되는 것을 볼 수 있었다.
참고문헌
V2V-PoseNet: Voxel-to-Voxel Prediction Network for Accurate 3D Hand and Human Pose Estimation from a Single Depth Map
NAVER Engineering | 발표자: 문경식 (서울대학교 박사과정) 발표일: 2018.08 본 논문은 single depth map으로부터의 정확한 3D hand pose estimation을 목표로 한다. 3D hand pose estimation은 HCI, AR등의 기술을 구현함에
tv.naver.com
[CVPR-2018]V2V-PoseNet: Voxel-to-Voxel Prediction Network for Accurate 3D Hand and Human Pose Estimation from a Single Depth Map
* 본글의 모든 그림은 논문의 본문과 저자의 발표 자료에서 가져왔습니다. 정말 너무너무 오랜만에 새로운 논문을 들고왔습니다. 이런 완성도 낮은 글을 누가 찾아볼까 생각했는데, 생각보다 틈
reading-cv-paper.tistory.com