

☞ 문서의 내용은 가장 하단 참고문헌 및 사이트를 참고하여 필자가 보기 쉽도록 정리한 내용입니다.
☞ 틀린 내용 및 저작권 관련 문의가 있는 경우 문의하시면 수정 및 삭제 조치하겠습니다.
기존의 CNN 모델들은 모두 입력 이미지가 고정된 크기(ex 224x 244)의 입력이 요구되었다. 때문에 신경망을 통과시키기 위해서는 이미지를 고정된 크기로 crop하거나 warp해야 했다. 이에 모델의 정확도가 하락하는 등 모델의 성능에 악영향을 미쳤다. 사실 Convoltuon filter들은 입력 이미지가 고정될 필요가 없다. sliding window 방식으로 작동하기 때문이다. 이미지 크기의 고정이 필요한 이유는 Fully connected layer가 고정된 크기의 입력을 받기 때문이다. 이에 저자는 원본 이미지의 특징을 고스란히 간직한 feature map을 얻어 크기 변화에 관계 없이 고정된 길이의 출력을 만들어 낼 수 있는 Spatial Pyramid Pooling(SPP)를 제안한다.

전체 알고리즘 순서는 다음과 같다.
1. 전체 이미지를 미리 학습된 CNN을 통과시켜 feature map을 추출한다.
2. Selective Search를 통해서 찾은 각각의 ROI들은 각각의 크기와 비율이 다르다. 때문에 SPP를 이용하여 고정된 크기의 feature vector를 추출한다.
3. feature vector를 fully connectied layer에 통과 시킨다.
4. 추출한 vector로 binary SVM Classifier를 학습 시킨다.
5.추출한 vector로 Bouding box regressor를 학습 시킨다.
가장 핵심은 SPP을 이용하여 크기가 다른 feature map을 고정된 크기의 feuatre vector로 뽑아내는 것이다. 그 이후는 R-CNN과 거의 동일하다.
Spatial Pyramid Pooling
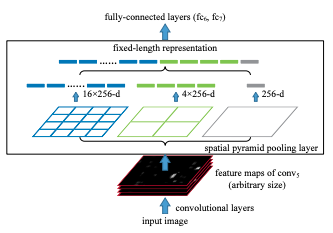
SPP의 동작 방식은 아래 이미지와 같다. 첫 번째로 Convolution Layer로 부터 featrue map을 입력 받는다. 두 번째로 입력된 feature map을 미리 정해져 있는 영역으로 나눈다. (이미지의 경우 4x4, 2x2, 1x1 세가지 영역을 제공하며 분할된 각각을 하나의 피라미드라고 부른다.) 세 번째로 각 bin에 대해서 max pooling 연산을 진행한다. (각 피라미드의 한 칸을 bin이라고 부른다.) 네 번째로 max pooling의 결과를 이어 붙인다.
입력 feature map의 chanel 크기를 k, bin의 개수를 M이라고 했을 때 SPP의 최종 output은 kM차원의 vector이다. 때문에 입력 이미지의 크기와는 상관없이 미리 설정한 bin의 개수와 채널 값으로 SPP의 출력이 결정되므로, 항상 동일한 크기의 결과를 돌려준다.
본 논문에서는 R-CNN이 각 이미지당 2,000개의 window를 생성해 Convolution Layer를 통해 연산해야 하는 문제점을 지적하였다. R-CNN은 Selective Search로 찾은 2천개의 물체 영역을 모두 고정 크기로 조절하고 CNN을 통과시켜 featrue를 추출하기 때문에 속도가 느리다. 하지만 SPPNet은 입력 이미지를 그대로 CNN에 통과시켜 feature map을 추출하고 2천개의 물체 영역을 찾아 SPP를 적용하여 고정된 크기의 feature를 얻는다. 논문에서는 Pascal VOC 2007 기준으로 SPP-net이 R-CNN보다 24~102배 빠르다고 하며, 좀 더 높거나 비슷한 수준의 성능을 보인다고 한다.
SPPNet 여전히 한계점이 있다.
1. 학습이 end-to-end 방식이 아니라 여러 단계까 필요하다. (fine-tuning, SVM training, Bounding Box Regression)
2. 최종 Classfication은 Binary SVM, Region Poposal은 Selective Search를 이용한다.
3. Fine tunig시에 SPP를 거치기 이전의 Conv layer들을 학습 시키지 못한다.
참고문헌
갈아먹는 Object Detection [2] Spatial Pyramid Pooling Network
지난 글 갈아먹는 Object Detection [1] R-CNN 들어가며 지난 시간 R-CNN에 이어서 오늘은 SPP-Net[1]을 리뷰해보도록 하겠습니다. 저 역시 그랬고, 많은 분들이 R-CNN 다음으로 Fast R-CNN 논문을 보시는데요, 해
yeomko.tistory.com
[논문요약] Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
이번 글에서 요약할 논문은 CNN의 고정된 입력 크기에 대한 솔루션을 제시하는 Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition입니다.
velog.io