

☞ 문서의 이미지와 내용은 가장 하단 참고문헌 및 사이트를 참고했습니다.
☞ 틀린 내용 및 저작권 관련 문의가 있는 경우 문의하시면 수정 및 삭제 조치하겠습니다.
데이터를 활용하는 프로그래밍
책 'Dive into Deep Learning'에서는 다음과 같은 말이 나온다. "코드를 이용하는 프로그래밍과 데이터를 활용하는 프로그래밍은 차이가 있다." 우리가 실생활에 자주 사용하는 프로그램은 코드를 이용하는 프로그래밍으로 데이터를 필요로 하지 않는다. 쉽게 이해하기 위해서 아래와 같은 예를 들어보자.
첫 째 : 전자레인지를 동작하는 프로그래밍은 다양한 조건에서 동작을 정확하게 작동하게 만드는 몇 가지 논리와 규칙만 존재하면 된다.
둘째 : 주민 번호를 인식하는 프로그래밍은 6자리를 포함해야 하며 앞 2자리는 연도, 중간 2자리는 월, 끝 2자리는 일 같은 규칙을 단순히 확인하면 된다.
위에서 설명한 두 가지 예를 실행하는 프로그램은 더욱 잘 작동하기 위해 현실 세계에서 데이터를 수집하여 특징을 추출하고 학습할 필요가 없다. 왜냐하면 상식과 알고리즘 기술을 이용해서 충분히 작업이 가능하기 때문이다. 하지만 이미지에 강아지, 고양이, 사람, 자동차 등이 있는지를 확인하고 분류하는 문제는 상식과 알고리즘 기술로는 해결이 불가능하다.
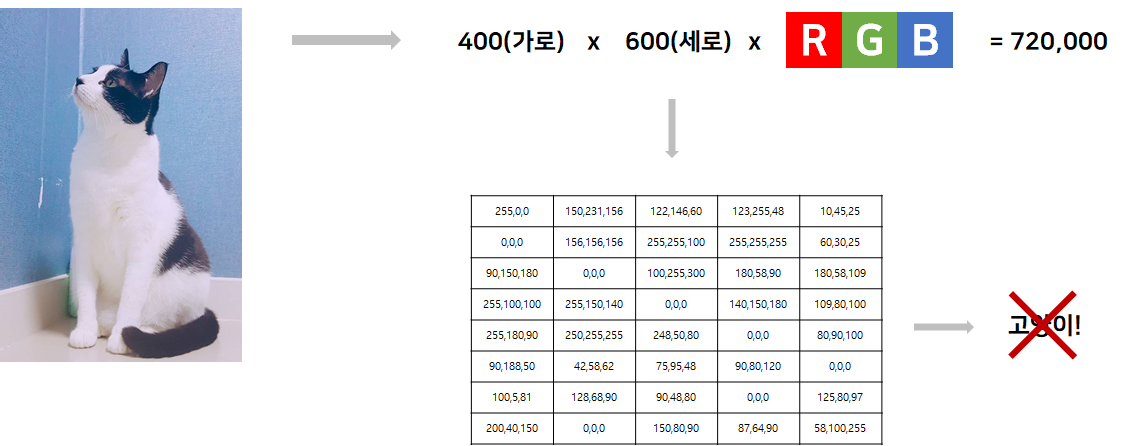
쉽게 이해하기 위해 위와 같은 고양이 이미지가 있다고 생각해보자. 여기서 이미지는 400(가로) x 600(세로)의 크기를 가지고 있으며 각 픽셀에는 RGB(빨간색, 초록색, 파란색)로 구성됐다고 가정하면 720,000개의 숫자로 표시될 것이다. (아래 이미지의 경우 720,000개의 숫자를 전부 표시하기 어렵기 때문에 5x7 크기로 예시를 만들었다.) 우리는 720,000개의 숫자로 표시된 정보를 이용해서 고양이가 어디 있는지 확인하고 분류해야 한다. 이는 기존의 상식과 알고리즘 기술로 해결하기 매우 어려운 일이다.



그 이유는 고양이의 눈, 코, 무늬, 꼬리 등을 결합하여 나타나는 특징을 찾아 이미지를 해석해야 하기 때문이다. 이런 문제를 해결하기 위해서는 고양이가 포함되어 있는지 여부를 배울 수 있는 프로그램을 만들어 학습시켜야 한다. 때문에 현실 세계에서 데이터를 수집하여 특징을 추출하고 학습해야 한다.
인공지능과 데이터의 상관관계
인공지능도 사람과 똑같다. 사람이 한 분야의 공부를 오래 하면 오래 할수록 그 분야의 전문가가 되듯이 인공지능도 데이터를 이용하여 학습을 해 뛰어난 성능을 보여준다. 여기서 인공지능을 학습하기 위한 데이터는 세 가지 종류로 분류할 수 있다.
1. 순수 데이터 : 사용자들이 어떠한 행위를 했을 때 남긴 데이터를 의미하거나 데이터 값 그 자체를 의미한다.
2. 가공 데이터 : 관리자가 데이터를 변경, 결합하는 행위를 거친 데이터, 대부분 인공지능은 가공 데이터를 이용한다.
3. 인조 데이터 : 데이터를 구하기 힘들거나 데이터의 추측 효용성을 증명하기 위해 만들어진 데이터이다.
아래 이미지에서 농구공을 찾는 인공지능을 만든다고 예를 들어보자 그러면 농구공 이미지 데이터를 모아 학습시켜야 농구공을 찾는 인공지능이 만들어진다. 인공지능은 데이터에서 통계적 규칙이나 패턴을 찾아낸다. 때문에 데이터가 많으면 많을수록 인공지능의 성능이 올라간다. 물론 알고리즘, 컴퓨터 성능 등에 따라서 영향을 받을 수도 있다. 하지만 성능을 높이는 방법 중 가장 쉬운 방법은 데이터 수를 늘리는 방법이다.

그렇다면 이렇게 많은 데이터는 어디서 얻을까? 첫 번째는 당연하게도 직접 수집하는 것이다(인터넷에서 *크롤링하는 것을 포함). 두 번째는 공공기관 등에서 제공하는 무료 데이터를 얻는 것이다. 세 번째는 데이터를 구매하는 것이다. 이 보다 더 다양한 방법이 있을 수 있다. 제일 좋은 방법은 직접 수집하는 것이다. 그 이유는 나에게 맞는 데이터를 맞춰서 수집할 수 있기 때문이다. 하지만 직접 수집하는 것은 시간이 많이 걸린다. 때문에 데이터를 제공해줄 대상이 필요하다. 하지만 데이터를 얻기 위해서는 데이터를 주는 대상에게 무엇인가를 줘야 한다. 이런 방법론으로 생각해본다면 기업들은 우리에게 서비스를 왜 공짜로 사용하게 해 주는지 알 수 있게 된다. ( 모든 기업들이 그런 것은 아니다.)
*크롤링 : 쉽게 웹 사이트들에서 자동으로 원하는 정보를 추출하여 저장하는 것이라고 생각하면 됩니다.
아마존, 구글, 페이스북, 네이버, 카카오톡 등 많은 기업들은 플랫폼을 만들고 많은 데이터를 사용자에게 얻으려고 한다. 그 이유는 그 데이터가 정말 중요한 데이터가 될 수 있기 때문이다. 우리는 기업에서 제공하는 서비스를 사용하면서 학습에 도움이 되는 데이터를 기업에게 제공하고 있는 것이다.
우리가 자주 사용하는 SNS인 인스타에 사진을 올리면 인스타는 인공지능을 통해서 그 사진이 어떤 사진인지 분석한다. 사람이 있는지 실외에서 찍은 것인지 실내에서 찍은 것인지 등 이를 통해 인스타는 사진들을 여러 가지 상황으로 이미지를 분류할 수 있어 사람들의 관심사에 따라 인스타 이미지를 보여줄 수 있다. 또한 사람들의 태그와 인공지능의 태그를 분석하여 인공지능이 정확하게 예측했는지를 확인하고 그에 따른 처리를 할 수 있다. 이 처럼 인스타를 고도화하기 위해서는 사용자들의 데이터가 필요하다. (기존에는 개발자 도구에서 인스타가 자동으로 태그 하는 것을 확인할 수 있었다. 현재는 개발자 도구에서 확인이 불가능하다.)
내비게이션 어플의 경우는 사용자들이 사용하면 사용할 수록 지도의 정확도를 높여주고 지도를 고도화 할 수 있다. 이런 고도화된 지도와 사용자들이 사용하는 디바이스의 센서들을 이용하여 새로운 서비스를 제공해줄 수 있다. 만약 이렇게 계속 해서 좋은 서비스를 제공해 준다면 사용자들은 소문으로 네비게이션 어플에 몰려들 것이고 이용자 증가로 실시간 길안내가 교통 분산 효과를 가져오게 할 수도 있다.
구글의 많은 부분을 차지하는 광고 수입은 사용자에게 얼마나 개인 맞춤 광고를 할 수 있는지에 따라 달라진다. 흥미 있는 위주의 광고를 제공할수록 사용자는 광고를 클릭할 확률이 높아지기 때문이다. 때문에 구글은 많은 환경에서 사용자의 데이터를 수집한다. 위치 정보, 검색 정보, 음성 정보 등 이렇게 수집된 정보는 사용자의 식습관, 취향, 연령대, 성별 등 민감한 내용까지 알 수 있게 되고 개인 맞춤 광고 서비스를 제공할 수 있게 된다.
구글은 나에게 어떤 카테고리를 줬을까?
구글이 광고를 위해 여러분들의 정보를 수집하고 최적화한 카테고리를 확인할 수 있는 방법이 있다. 아래 이미지처럼 구글 계정으로 접속한다. 그리고 좌측 상단 데이터 및 맞춤 설정으로 들어간다.
그리고 아래 이미지처럼 광고 설정으로 이동을 클릭한다.
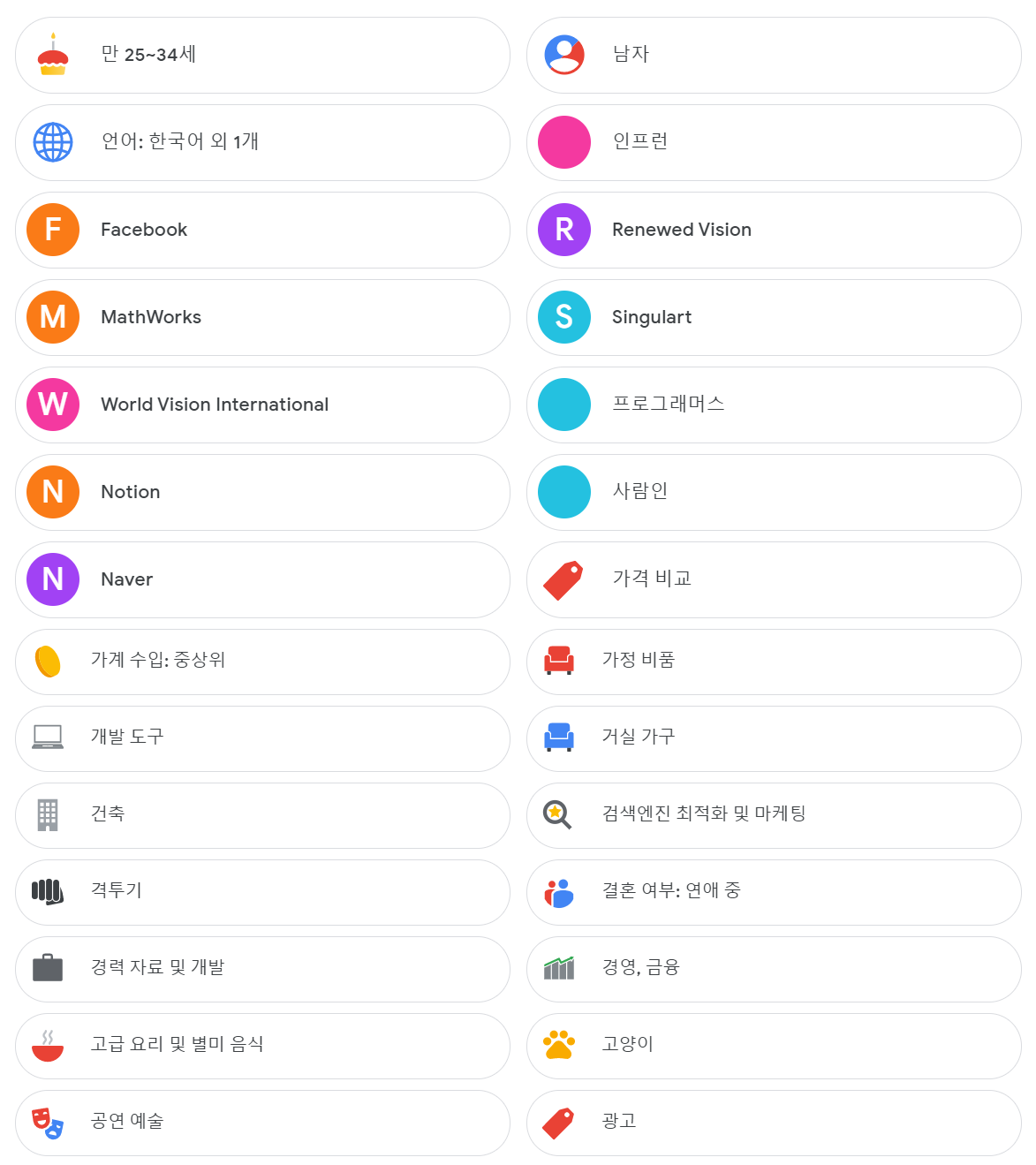
그럼 아래처럼 구글이 수집한 데이터를 기반으로 여러분들에게 여러 가지 카테고리를 준 것을 확인할 수 있다. 이 데이터는 여러분들이 블로그, 사이트 등에 접속했을 때 나오는 구글 광고에 영향을 준다. 몇 가지는 정확하고 몇 가지는 틀리다. (가계 수입 : 중상위 이것은 명백히 잘못된듯하다.)
참고 자료 및 출처
Photo by Markus Spiske on Unsplash
Pro A match: referee shows two free throw – Nürnberg Falcons vs. wiha Panthers Schwenningen . Download this photo by Markus Spiske on Unsplash
unsplash.com
[CS231n] 1. Data Driven Approach
본 내용은 스탠포드대의 강의: CS231n을 학습한 내용을 기반으로 작성되었습니다.최근접이웃 (이하 NN)은 Data Driven Approach의 기초가 되는 분류 기법인데, Data DRiven Approach에 대해 간단히 설명하자면,
velog.io
이미지 인식 및 객체 감지: 파트 1
https://www.learnopencv.com/image-recognition-and-object-detection-part1/ 이것은 이미지 인식 및 객체...
blog.naver.com
1. 딥러닝 소개 — Dive into Deep Learning documentation
ko.d2l.ai