

☞ 문서의 내용은 가장 하단 참고문헌 및 사이트를 참고하여 필자가 보기 쉽도록 정리한 내용입니다.
☞ 틀린 내용 및 저작권 관련 문의가 있는 경우 문의하시면 수정 및 삭제 조치하겠습니다.
AlexNet
AlexNet은 ILSVRC의 2012년 대회에서 Top 5 test error 15.4%를 기록하여 1위를 차지한 네트워크로 CNN의 우수함을 전세계에 입증한 네트워크로 AlexNet 네트워크 이후로 CNN구조의 GPU구현과 dropout 적용이 보편화 되었다. AlexNet의 논문 이름은 ImageNet Classification with Deep ConvConvolutional Neural Networks이다.
AlexNet구조
AlexNet의 구조는 LeNet-5과 크게 다르지 않다. 위 아래로 filter들이 절반씩 나뉘어서 2개의 GPU로 병렬연산을 수행하는 것이 가장 큰 특징이다. 총 8개의 레이어로 구성되어 있다. 일부분 max-pooling이 적용된 Convolution layer 5개, fully-connected layers 3개로 구성되어 있다. 2, 4, 5번째 Convolution layer는 전 단계의 같은 채널의 특성맵들만 연결되어 있는 반면, 3번째 Convolution layer는전단계의두채널의특성맵들과모두연결되어있다. Input image는 224 x 224 x 3 (RGB 이미지)이다.

Alex Net을 자세히 살펴보면 다음과 같이 [Input layer] - [Conv1] - [MaxPool1] - [Norm1] - [Conv2] - [MaxPool2] - [Norm2] - [Conv3] - [Conv4] - [Conv5] - [Maxpool3] - [FC1] - [FC2] - [Output layer] 으로 구성되어 있다. 여기서 Norm은 수렴 속도를 높이기 위해 local response normalization을 하는 것으로 local response normalization은 특성맵의 차원을 변화시키지 않는다.
| Type | Filter | stride | padding | Input | output | remarks |
| Input layer | - | - | - | - | - | - |
| Conv1 | 11 x 11 x 3 x 96 | 4 | 0 | 224 x 224 x 3 | 55 x 55 x 96 | - |
| MaxPool1 | 3 x 3 | 2 | - | 55 x 55 x 96 | 27 x 27 x 96 | - |
| Norm1 | - | - | - | 27 x 27 x 96 | 27 x 27 x 96 | LRN을 이용한normalization layer |
| Conv2 | 5 x 5 x 96 x 256 | 1 | 2 | 27 x 27 x 96 | 27 x 27 x 256 | - |
| MaxPool2 | 3 x 3 | 2 | 27 x 27 x 256 | 13 x 13 x 256 | - | |
| Norm2 | - | - | - | 13 x 13 x 256 | 13 x 13 x 256 | LRN을 이용한normalization layer |
| Conv3 | 3 x 3 x 256 x 384 | 1 | 1 | 13 x 13 x 256 | 13 x 13 x 384 | - |
| Conv4 | 3 x 3 x 384 x 384 | 1 | 1 | 13 x 13 x 384 | 13 x 13 x 384 | - |
| Conv5 | 3 x 3 x 384 x 256 | 1 | 1 | 13 x 13 x 384 | 13 x 13 x 256 | - |
| MaxPool3 | 3 x 3 | 2 | - | 13 x 13 x 256 | 6 x 6 x 256 | - |
| FC1 | - | - | - | 6 x 6 x 256 | 4096 | - |
| FC2 | - | - | - | 4096 | 1000 | - |
| Output layer | - | - | - | - | - | - |
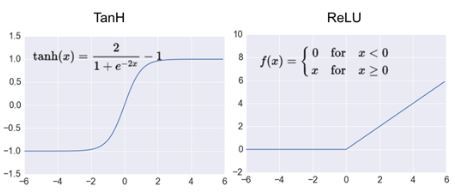
ReLU
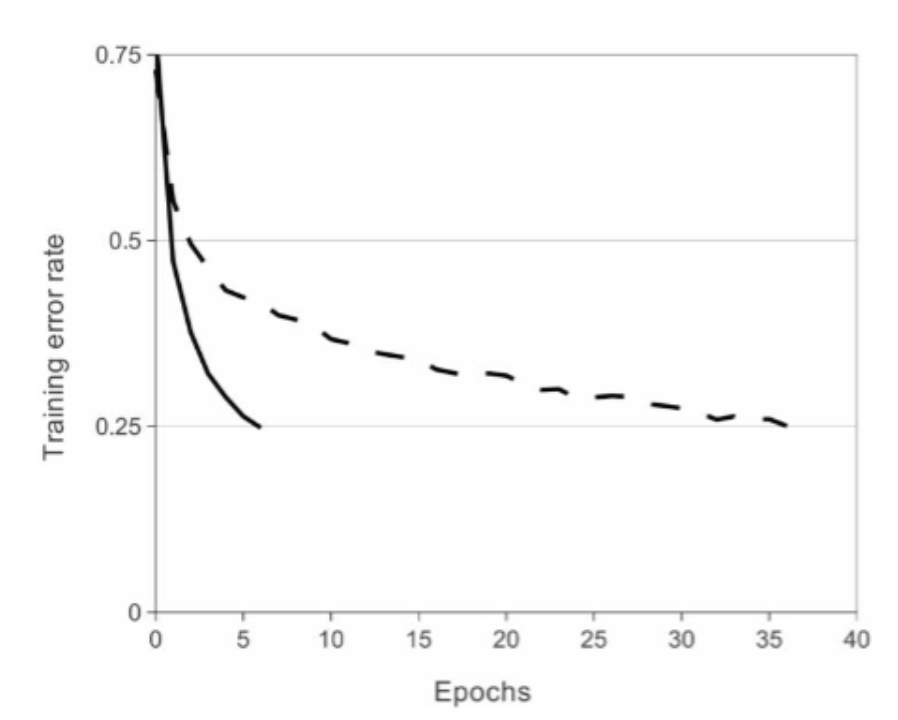
저자는 tanh와 Relu의 학습 속도를 비교했다. CNN으로 CIFAR-10 dataset을 학습시켰을 때 25% training error에 도달하는 실험결과는 아래 그림과 같다. 점선인 tanh은 35epoch이 지나서야 도달한다. 하지만 ReLU를 사용하면 6epch만에 도달한다. 약 6배 정도 빠르다. 이에 Alex Net에서는 ReLU를 활성화 함수로 사용한다.
Training on Multiple GPUs
Alex Net은 network를 2개의 GPU로 나누어서 학습했다. 이를 GPU parallelization이라고 한다. 저자는 2개의 GPU로 나누어서 학습 시켜 top-1 error와 top-5 error가 1.7%, 1.2% 감소되었으며 학습속도가 빨라졌다고 한다. 아래 그림은 GPU1, GPU2 각각에서 학습된 kernel map으로 GPU1에서는 색상과 관련 없는 정보를 학습하고 GPU2는 색상과 관련된 정보를 학습하는 것을 확인 할 수 있다.

Dropout
과적합(over-fiting)을 막기 위해서 dropout을 사용했다. dropout이란 뉴런 중 일부를 생략하면서 학습을 진행하는 것을 말한다. 매 입력마다 dropout을 적용시키면 가중치는 공유되지만 신경망은 서로 다른 구조를 띄게 된다. 때문에 뉴런은 특정 다른 뉴런의 존재에 의존하지 않기 때문에 co-adaptation을 감소시킨다고 한다. 그러므로 서로 다른 뉴런의 임의의 부분집합끼리 결합에 유용한 robust 특징을 배울 수 있다. dropout은 훈련시에 적용되는 것이고 테스트시에는 모든 뉴런을 사용한다.
co-adaptation : 신경망의 학습 중, 어느 시점에서 같은 층의 두 개 이상의 노드의 입력 및 출력 연결강도가 같아지면, 아무리 학습이 진행되어도 그 노드들은 같은 일을 수행하게 되어 불필요한 중복이 생기는 문제를 말한다. 즉 연결강도들이 학습을 통해 업데이트 되더라도 이들은 계속해서 서로 같은 입출력 연결 강도들을 유지하게 되고 이는 결국 하나의 노드로 작동하는 것으로써, 이후 어떠한 학습을 통해서도 이들은 다른 값으로 나눠질 수 없고 상호 적응하는 노드들에는 방비가 발생하는 것이다. 결국 이것은 컴퓨팅 파워와 메모리의 낭비로 이어진다.

Overlapping pooling
기존 LeNet-5의 경우 average polling을 사용했으며 stride를 커널 사이즈보다 작게 하는 non-overlapping을 적용했다. 하지만 AlexNet은 max pooling을 사용 했으며 overlapping pooling을 적용 했다. 따라서 overfit을 방지하고 top-1와 top-1와 top-5 error를 각각 0.4% 0.3% 낮췄다고 한다. 아래 그림은 non-overlapping pooling과 overlapping pooling의 비교 모습이며 max pooling을 예로 설명 했다. 그림을 보면 non-overlapping은 중첩없이 진행되는 모습을 보이며 overlapping은 중첩되는 모습을 보인다.

local response normalization (LRN)
LRN은 generalization(일반화)을 목적으로 한다. sigmoid나 tanh함수는 입력 data의 속성이 서로 편차가 심하면 saturation(weight 업데이트가 멈추는 현상)되는 현상이 심해져 vanishing gradient problem(기울기 값이 사라지는 문제)를 유발할 수 있게 된다. 반면에 ReLU는 non-saturating nonlinearity 함수이기 때문에 saturation을 예방하기 위한 입력 normalization이 필요로 하지 않는 성질을 갖고 있다. ReLU는 양수값을 받으면 그 값을 그대로 뉴런에 전달하기 때문에 너무 큰 값이 전달되어 주변의 낮은 값이 뉴런에 전달되는 것을 막을 수 있다. 이것을 예방하기 위한 normalization이 LRN이다. 논문에서 LRN을 측면 억제(later inhibition)의 형태로 구현된다고 나와 있다. 측면 억제는 강한 자극이 주변의 약한 자극을 전달하는 것을 막는 효과를 말한다. 이러한 기법으로 top-1와 top-5 error를 각각 1.4% 1.2% 감소시켰다. AlexNet 이후 현대의 CNN에서는 local response normalization 대신 batch normalization기법을 사용한다.
non-saturating nonlinearity 함수는 어떤 입력 x가 무한대로 갈때 함수의 값이 무한대로 가는 것을 의미한다. saturating nonlinearity 함수는 어떤 입력 x가 무한대로 갈때 함수의 값이 어떤 범위내에서만 움직이는 것을 의미한다.
출처 : m.blog.naver.com/PostList.nhn?blogId=smrl7460
Data augmentation
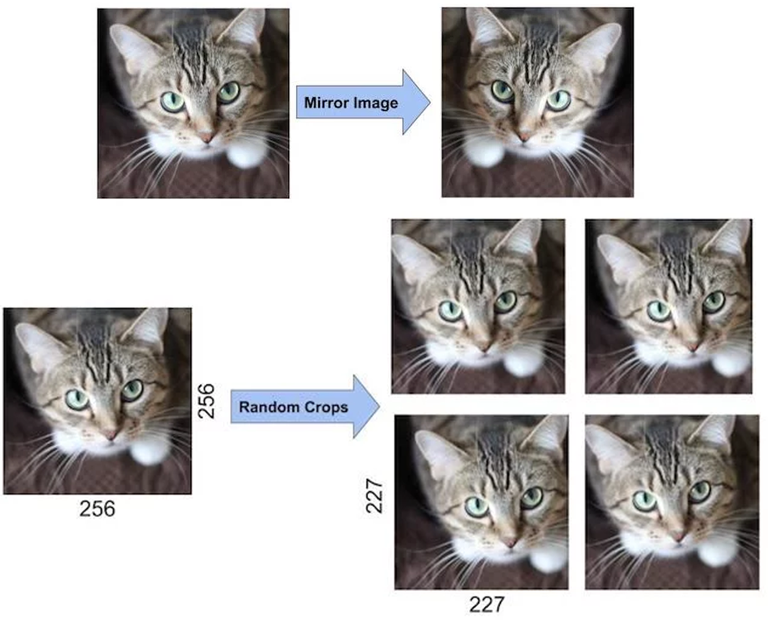
논문에서는 2가지의 Data augmentation을 적용했다. Data augmentation은 현재 가지고 있는 데이터를 변형하여 다양한 데이터를 좀 더 얻는 것으로 CNN모델을 학습시키기 위해 만들어진 개념이다. Data augmentation은 적은 노력으로 다양한 데이터를 형성하게 하여 over-fiting을 피하게 해준다. Alex net에서 사용된 첫 번째 기법은 generating image translation and horizontal reflection이다. 이 기법은 256 x 256 이미지를 수평 반전하고 224 x 224 크기로 Random 하게 crop 한다. 그리고 생성된 이미지를 horiontal reflection한다. 그러면 하나의 이미지에서 10개의 이미지를 생성할 수 있다. 모델이 10개의 패치에 대해 예측한 값을 평균내어 최종 예측값으로 사용한다.
두 번째 기법은 RGB channerl의 강도 조절이다. 아래의 공식에서 볼 수 있듯이 RGB pixel 값들의 3x3 covariance matrix의 eigenvector와 eigenvalue를 뜻하는 $P_{i}$, $λ_{i}$에 랜덤 값인 $α_{i}$을 곱해서 RGB image pixel에 더해줬다. 이를 통해 조명의 영향과 색의 intesity 변화에 대한 불변성을 지닌다. 이 기법을 통해 top-1 error를 1% 낮췄다고 한다.
$$[P_{1},P_{2},P_{3}][α_{1}λ_{1},α_{2}λ_{2},α_{3}λ_{3}]^{T}$$
참고문헌
[논문 리뷰] AlexNet(2012) 리뷰와 파이토치 구현
딥러닝 논문 읽고 파이토치로 구현하기 시리즈 1. [논문 리뷰] LeNet-5 (1998), 파이토치로 구현하기 이번에 읽어볼 논문은 'ImageNet Classification with Deep Convilutional Neural Networks'(AlexNet) 입니..
deep-learning-study.tistory.com
AlexNet - 2012
CNN의 강려크함을 세상에 널리 알려주신 조상님. AlexNet 리뷰! | ImageNet Large-Scale Visual Recognition Challenge(이하 ILSVRC)-2012에서 Top-5 test 기준, 에러율 15.3%로 1등을 차지하면서 26.2%인 2등과의 격차를 10%
brunch.co.kr
[CNN 알고리즘들] AlexNet의 구조
LeNet-5 => https://bskyvision.com/418 AlexNet => https://bskyvision.com/421 VGG-F, VGG-M, VGG-S => https://bskyvision.com/420 VGG-16, VGG-19 => https://bskyvision.com/504 GoogLeNet(inception v1) =>..
bskyvision.com
6. AlexNet
안녕하세요~ 이제부터는 CNN이 발전해왔던 과정을 여러 모델을 통해 알려드릴까해요. 그래서 이번장에서는 그 첫 번째 모델이라 할 수 있는 AlexNet에 대해서 소개시켜드릴려고 합니다! AlexNet의 논
89douner.tistory.com