

☞ 문서의 내용은 가장 하단 참고문헌 및 사이트를 참고하여 필자가 보기 쉽도록 정리한 내용입니다.
☞ 틀린 내용 및 저작권 관련 문의가 있는 경우 문의하시면 수정 및 삭제 조치하겠습니다.
CNN(Convolutional neural network)은 CNN은 데이터에서 패턴을 학습하고 이미지를 분류하기 때문에 특징을 수동으로 입력할 필요가 없다 때문에 컴퓨터 비전(computer vision)에서 많이 사용된다. CNN 네트워크로 VGG, GoogleNet, ResNet, Yolo 등이 있다.
Fully-connected neural networks(FNN)의 문제점과 CNN
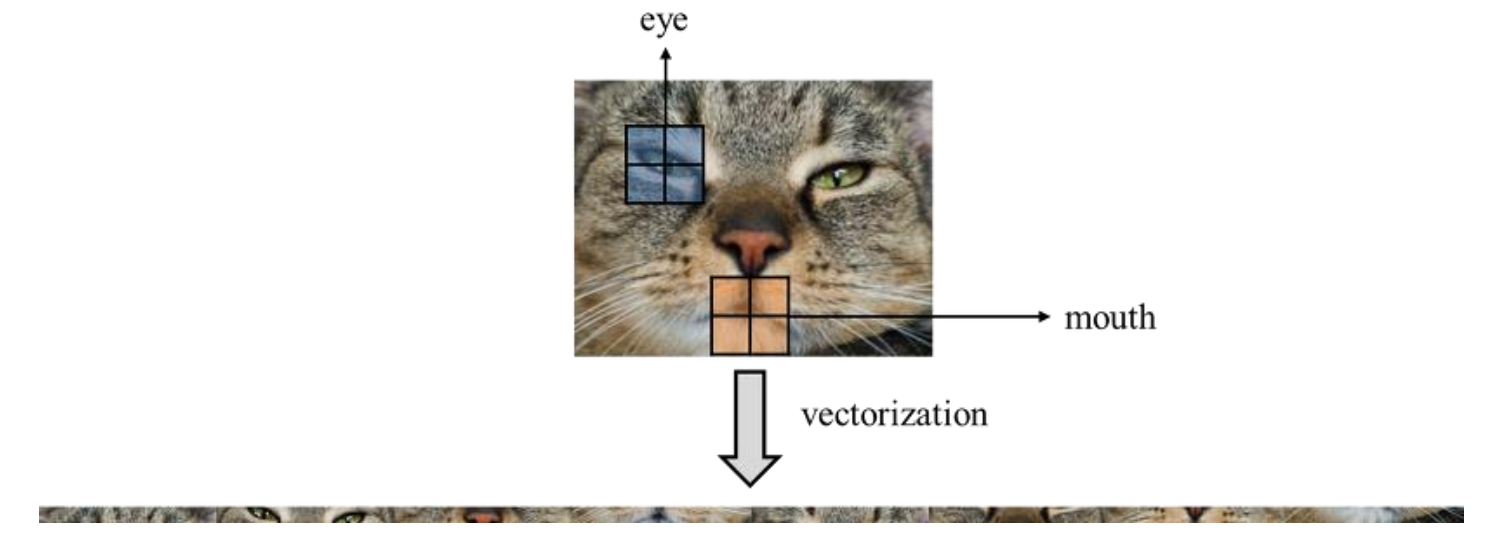
Fully-connected neural networks(FNN)은 그림1(좌) 처럼 한 계층의 모든 뉴런을 다른 계층의 모든 뉴런에 연결하는 완전히 연결된 계층이다. 입력 데이터가 이미지인 경우 그림1(우) 처럼 3차원 데이터를 평평한 1차원 데이터로 평탄화 해줘야 한다. 그런데 이미지는 3차원 형상이며, 이 형상에는 공간적 정보가 담겨 있다. 3차원 속에서 의미를 갖는 본질적인 패턴이 숨어 있는 것이다. 그러나 Fully-connected neural networks는 형상을 무시하고 입력 데이터를 동등한 뉴런으로 취급하여 형상에 담긴 정보를 살릴 수 없다. 또한 막대한 양의 model paramete를 가진다. 만약 FNN을 이용하여 1024 x 1024 크기의 이미지를 처리한다고 하면 약 315만( = $1024^{2}$ x 3 )이라는 막대한 수가 된다. 그렇다면 막대한 양의 뉴런이 필요하고, 이에 따라 인공신경망 전체의 model parameter는 기하급수적으로 증가한다.

CNN 용어 정리
채널(Channel)
컬러 사진은 각 픽셀을 RGB 3개의 실수로 표현한 3차원 데이터이다. 그러므로 컬러 이미지는 3개의 채널로 구성된다. 반면에 흑백 명암만을 표현한다면 2차원 데이터로 1개 채널로 구성된다. 아래 그림2 (좌)는 height가 400pixel 이고 width가 400pixel인 컬러 이미지이고 Shape 표현은 (400, 400, 3)이다. 그림2 (우)는 height가 400pixel 이고 width가 400pixel인 흑백 이미지이고 Shape 표현은 (400, 400, 1)이다.


합성곱(Convolution) & 필터(Filter) & Stride
합성곱 연산은 입력 데이터에 필터를 적용한다. 입력, 필터, 출력은 세로 가로 방향의 Shape을 가졌고 (height, width)로 표기한다. 그림3 에서 입력(5, 5) 필터(3, 3) 출력(3,3) 이다. 필터를 일정 간격으로 이동(Stride)해가며 입력 데이터에 적용한다. 그림3 에서 보듯 입력과 필터에서 대응하는 원소끼리 곱한 후 그 총합을 구한다. 이를 통해 이미지의 feature map을 만들 수 있다.
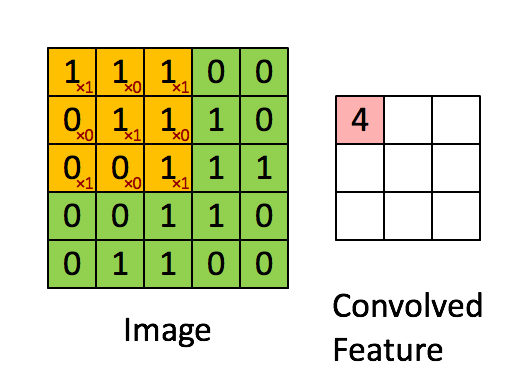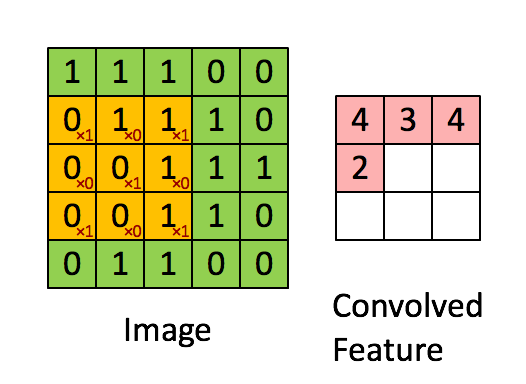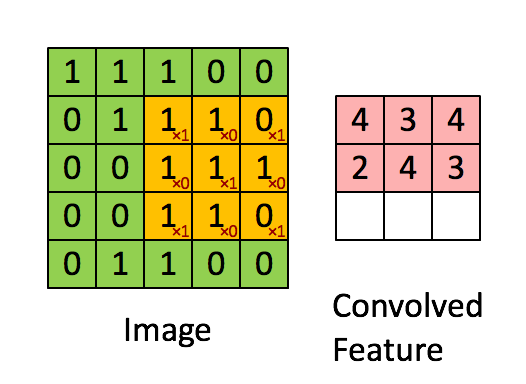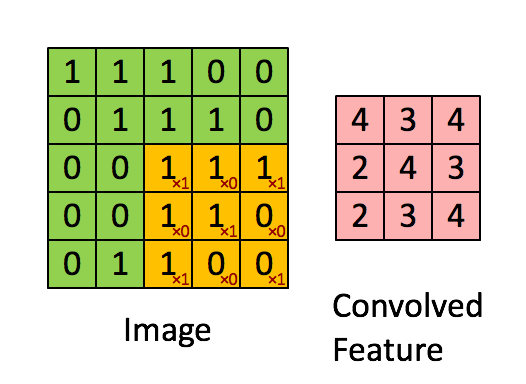
필터는 이미지의 특징을 찾아내기 위한 공용 파라미터이다. 논문에 따라 필터를 커널(kernel)이라고도 부른다. CNN에서 학습의 대상은 필터 파라미터이다. 필터는 입력 데이터를 지정한 간격으로 순회하면서 합성곱을 계산한다. 여기서 지정된 간격으로 필터를 순회하는 간격을 Stride라고 한다. 그림3은 Stride가 1로 필터를 입력 데이터에 순회하는 예제이다. stride가 n로 설정되면 필터는 n칸씩 이동하면서 합성곱을 계산한다.


그림 4와 같이 입력 데이터가 여러 채널을 가질 경우 필터는 각 채널을 순회하며 합성곱을 계산한 후, 채널 별 feature map을 만든다. 그리고 각 채널의 feature map을 합산하여 최종 feature map으로 반환된다. 입력 데이터는 채널 수와 상관없이 필터 별로 1개의 feature map이 만들어진다.
패딩(Padding)
패딩은 주로 출력 크기가 줄어드는 것을 방지하기 위해 사용된다. 예를 들어 (4, 4)입력 데이터에 (3,3)필터를 적용하면 출력은 (2,2)가 되어, 입력보다 2만큼 줄어든다. 이를 몇 번 되풀이하면 출력 크기가 1이 되어 문제가 될 수 있다. 패딩은 입력 데이터의 외각에 지정된 픽셀만큼 특정 값으로 채워 넣는다. 보통 0으로 채워 넣는다. 그림 5는 (32, 32, 3) 데이터 외각에 2 pixel을 추가하여 (36, 36, 3) 데이터로 만드는 예시이다.

풀링층(Pooling Layer)
Pooling Layer는 Convolution layer의 출력 데이터(Activation map)를 입력으로 받아서 출력 데이터의 크기를 줄이거나 특정 데이터가 이미지 내의 위치 변화에 영향을 덜 받게 한다. Pooling Layer를 처리하는 방법으로는 Max-Pooling, Average Poolling, Min Pooling이 있다. 정사각 행렬의 특정 영역 안에 값의 최댓값을 모으거나 특정 영역의 평균을 구하는 방식으로 동작한다. 일반적으로 Pooling 크기와 Stride를 같은 크기로 설정하여 모든 원소가 한 번씩 처리되도록 설정한다. 이미지 인식 분야에서는 주로 Max-Pooling을 사용한다. 이는 뉴런이 가장 큰 신호에 반응하는 것과 유사하다고 한다. 이렇게 하면 노이즈가 감소하고 속도가 빨라지며 영상의 분별력이 좋아진다고 한다. Pooling layer는 Convolution 레이어와 비교했을 때 다음과 같은 특징을 가지고 있다. 첫 번째로 학습 대상 파라미터가 없다. 두 번째로 Pooling layer를 통과하면 행렬의 크기가 감소된다. 세 번째로 Pooling layer를 통해서 채널 수 변경이 없다.

그림 7은 계산된 특징이 이미지 내의 위치에 대한 변화에 영향을 받지 않는 것을 보여준다. 예를 들어 이미지의 우측 상단에서 찾는 특징은 이미지의 중앙에 위치하더라도 크게 영향을 받지 않아야 한다. 그렇기 때문에 풀링을 이용하여 불변성(invariance)을 찾아내서 공간적 변화를 극복할 수 있다.

레이어별 출력 데이터 계산
Convolution layer 출력 데이터 크기 산정
입력 데이터에 대한 필터의 크기와 Stride 크기에 따라서 Feature Map 크기가 결정된다. 공식은 다음과 같다. 공식의 결과는 자연수가 되어야 한다. 또한 Convolution layer 다음에 pooling layer가 온다면, Feature Map의 행과 열 크기는 Pooling 크기의 배수여야 한다.
$$OutputHeight = OH =\frac{(H + 2P - FH)}{S} + 1 $$
$$OutputWeight = OW =\frac{(W + 2P - FW)}{S} + 1 $$
H : Input data height
W : Input data weight
FH : Filter height
FW : Filter weight
S : Stride size
P : Padding size
Pooling layer 출력 데이터 크기 산정
일반적으로 Pooling Size는 정사각형입니다. Pooling Size를 Stride 같은 크기로 만들어서, 모든 요소가 한 번씩 Pooling 됨으로 입력 데이터의 행 크기와 열 크기는 Pooling Size의 배수여야 한다. 결과적으로 Pooling layer의 출력 데이터의 크기는 행과 열의 크기를 Pooling Size로 나눈 값이다.
$$OutputRowSize = \frac{(InputRowSize)}{PoolingSize} $$
$$OutputColumnSize = \frac{(InputColumnSize)}{PoolingSize} $$
CNN 전체 구성
CNN의 전체적인 구성은 그림 8과 같다. CNN은 크게 2단계로 나눠진다. 첫 번째 단계는 특징 추출(Feature extraction) 두 번째는 분류(classification)이다. 특징 추출 단계는 입력 데이터(input)의 고유한 특징(invariance)을 찾는 단계이다. 분류 단계는 추출된 특징을 이용하여 Class를 선택하는 단계이다.
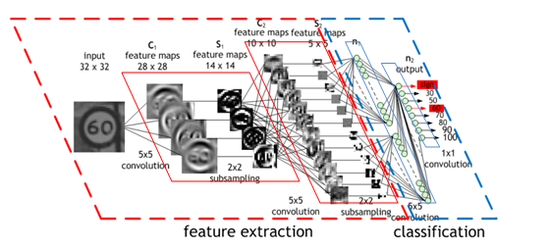
특징 추출 단계(Feature Extraction)
Convolution과 Pooling을 반복하면서 이미지의 feature를 추출
- Input : 이미지
- Convolution Layer : 필터를 통해 이미지의 특징을 추출
- Pooling Layer : 특징을 강화시키고 이미지의 크기를 줄임 ( sub-smapling )
이미지 분류 단계(Classification)
- Flatten Layer : 데이터 타입을 FC네트워크 형태로 변경. 입력 데이터의 shape 변경만 수행.
- Softmax Layer : Classification수행
- output : 인식 결과
참고 자료
호다닥 공부해보는 CNN(Convolutional Neural Networks)
CNN?CNN은 이미지를 인식하기위해 패턴을 찾는데 특히 유용합니다. 데이터에서 직접 학습하고 패턴을 사용해 이미지를 분류합니다. 즉, 특징을 수동으로 추출할 필요가 없습니다.이러한 장점때문
gruuuuu.github.io
CNN, Convolutional Neural Network 요약
Convolutional Neural Network, CNN을 정리합니다.
taewan.kim
딥러닝 피드 포워드 (feed forward)
신경망 (Neural Network)을 기반으로 하는 딥러닝 (Deep Learning) 피드포워드 입니다. 딥러닝의 피드 ...
blog.naver.com
합성곱신경망(CNN, Convolutional Neural Network)
CNN에 대해 더 자세한 내용은 아래의 링크를 참고하시면 됩니다. 자세한 설명 : 06. 합성곱 신경망 - Convolutional Neural Networks 텐서플로 실습 위주 : [러닝 텐서플로]Chap04 - 합성곱 신경망 CNN 1. Convolu..
excelsior-cjh.tistory.com
[머신 러닝/딥 러닝] 합성곱 신경망 (Convolutional Neural Network, CNN)과 학습 알고리즘
1. 이미지 처리와 필터링 기법 필터링은 이미지 처리 분야에서 광범위하게 이용되고 있는 기법으로써, 이미지에서 테두리 부분을 추출하거나 이미지를 흐릿하게 만드는 등의 기능을 수행하기 ��
untitledtblog.tistory.com
What is max pooling in convolutional neural networks?
Answer (1 of 7): Max pooling is a sample-based discretization process. The objective is to down-sample an input representation (image, hidden-layer output matrix, etc.), reducing its dimensionality and allowing for assumptions to be made about features con
www.quora.com