

1. GRU란?
GRU(Gated Recurrent Unit)는 순차 데이터를 처리하는 데 사용되는 모델입니다. GRU는 Reset Gate, Update Gate라는 두 개의 게이트를 사용하여 작동합니다. ResetGate(리셋 게이트)는 이전 상태를 얼마나 잊어야 하는지를 결정하며 Update Gate(업데이트 게이트)는 이전 상태의 정보를 얼마나 가져와야 할지를 결정합니다.
1.1 GRU 특징 및 장점
GRU는 LSTM(Long Short-Term Memory) 네트워크를 개선하기 위한 모델로 다음과 같은 특징을 가지고 있습니다. 정보의 흐름을 제어하기 위해 두 개의 게이트를 사용하여 계산을 효율적으로 합니다. 이러한 특징 덕분에 LSTM에 비해 빠른 학습 시간을 갖으며 낮은 계산 복잡성을 가지고 있습니다.
2. GRU Architecture (아키텍처)
GRU는 리셋 게이트와 업데이트 게이트를 가지고 있습니다. GRU의 동작 방식은 다음과 같습니다. 첫째, 리셋 게이트는 현재 상태에서 얼마나 이전 상태의 정보를 유지할지 결정합니다. 둘째, 업데이트 게이트는 이전 상태의 정보와 새로운 정보를 결합하는 것 사이의 균형을 결정합니다. GRU의 가장 큰 변화는 셀 상태를 두지 않고 RNN과 마찬가지로 하나의 출력만을 한다는 것입니다.
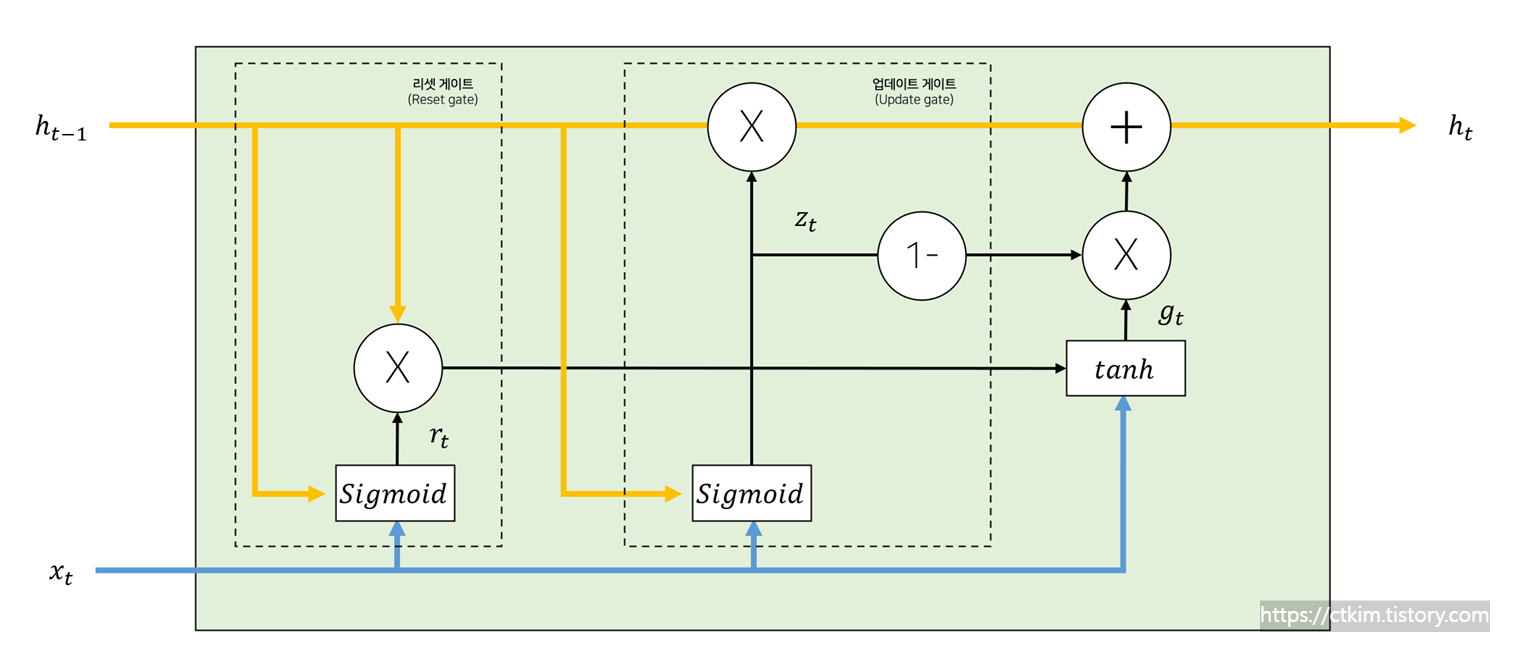
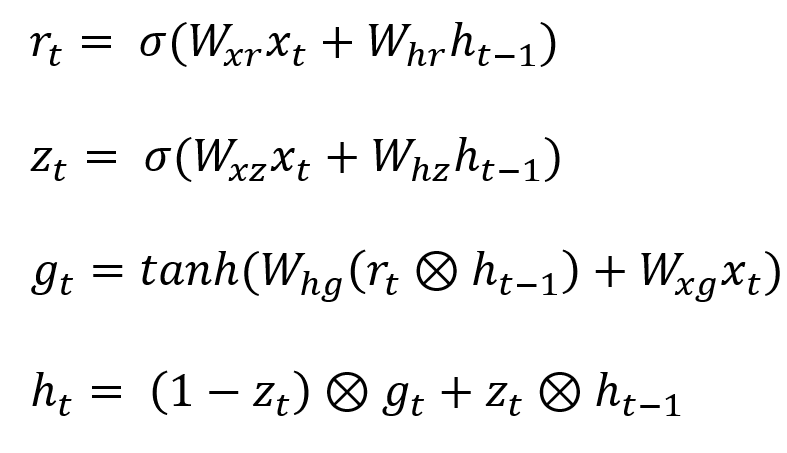
리셋 게이트는 현재 상태에서 얼마나 이전 상태의 정보를 유지할지 결정하는 역할을 합니다. 값이 0에 가까울 수록 이전 상태의 정보를 잊고, 1에 가까울수록 이전 상태의 정보를 기억합니다. GRU의 업데이트 게이트는 이전 상태의 정보와 새로운 정보를 가져오는 것 사이의 균형을 결정하는 역할을 합니다. 이는 LSTM의 망각 게이트와 입력 게이트가 결합된 형태로 비슷한 역할을 합니다. zt는 0과 1사이의 실수 값으로 표현되며, 값이 1에 가까울수록 이전 상태의 정보를 우선적으로 가져오고, 0에 가까울 수록 새로운 정보를 우선적으로 가져오게 됩니다. zt신호가 1일 경우, 1 - zt 연산을 통과한 신호는 0이 되어 입력 게이트의 역할은 수행되지 않습니다. 값이 0일 경우, 망각 게이트는 수행되지 않고 입력 게이트만 수행됩니다.
3. GRU 코드
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.keras.datasets import imdb
from tensorflow.keras.preprocessing import sequence
# Load the IMDB dataset
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=10000)
# Pad the sequences to the same length
max_len = 500
x_train = sequence.pad_sequences(x_train, maxlen=max_len)
x_test = sequence.pad_sequences(x_test, maxlen=max_len)
# Build the model
model = tf.keras.Sequential()
model.add(tf.keras.layers.Embedding(10000, 128))
model.add(tf.keras.layers.GRU(128, dropout=0.2, recurrent_dropout=0.2))
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
# Compile the model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# Train the model
history = model.fit(x_train, y_train, batch_size=32, epochs=10, validation_data=(x_test, y_test))
# Plot the loss and accuracy results
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model Loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Validation'], loc='upper right')
plt.show()
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model Accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Validation'], loc='lower right')
plt.show()
4. FAQ
4.1 GRU란?
GRU(Gated Recurrent Unit)는 순차 데이터를 처리하는 데 사용되며, LSTM(Long Short-Term Memory) 네트워크를 개선하기 위한 모델입니다.
4.2 GRU는 어떻게 작동합니까?
GRU는 리셋 게이트와 업데이트 게이트라는 두 개의 게이트를 사용하여 작동합니다.
4.3 LSTM보다 GRU를 사용하면 어떤 이점이 있습니까?
GRU는 아키텍처가 단순하고 매개변수가 적기 때문에 LSTM보다 계산적으로 더 효율적입니다. 또한 LSTM보다 학습 속도가 빠릅니다.