

☞ 문서의 내용은 가장 하단 참고문헌 및 사이트를 참고하여 필자가 보기 쉽도록 정리한 내용입니다.
☞ 틀린 내용 및 저작권 관련 문의가 있는 경우 문의하시면 수정 및 삭제 조치하겠습니다.
LeNet
Yann LeCun은 "Gradinet-based learning applied to document recognition" 논문에서 손글씨 숫자를 인식하는 문제를 해결하기 위해 LeNet을 고안했다. ( Image Class에서 보편적으로 사용되는 CNN(Convolution Neural Network)을 최초로 제안한 모델이다. ) 기존에 classifier로 사용되던 fully-connected layer, 즉 MLP(Multi-Layer Perceptron)는 다음과 같은 문제점이 있었다. 첫 번째로 2D 이미지 정보가 실제로는 많은 pixel로 구성 되어 있기 때문에 이것을 fully-connected로만 학습을 하게 될 경우 너무 많은 학습량, 학습 시간, 많은 weight를 저장해야할 hardware적인 요소가 필요하다. 두 번째로 위상 정보(fully-connected)가 무시된다. Fully Connected Layer에 이미지를 넣으면 3차원의 데이터를 1차원 데이터로 변경해줘야한다. 이때 데이터의 형상이 무시된다. 이러한 문제점을 극복하기 위해 Local receptive field, Shared weight, Sub-sampling의 개념을 결합한 Convolutional Neural Network 구조인 LeNet을 제안했다.
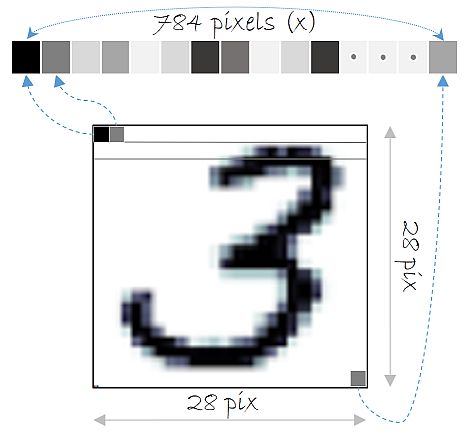
기존 Fully Connected Layer 을 이용해 MNIST 데이터셋을 분류하는 모델을 만들 때는 위의 그림 처럼 3차원인 MNIST 데이터 (28,28,1)를 input으로 넣어주기 위해 1차원의 평평한(flat) 데이터로 펼쳐줘야 했다. 즉, 28 * 28 * 1 = 784의 1차원 데이터로 바꾸어 입력층에 넣어주었다.
Local receptive field
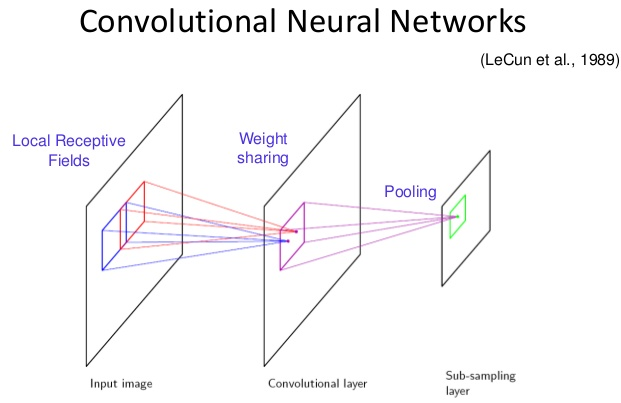
우리가 알고 있는 Convolution filter의 작동 방식을 설명하는 부분이다. filter가 전체 이미지를 돌아다니면서 만나게 되는 filter Size와 동일한 크기의 영역들을 Local receptive fields라고 지칭한다. 이렇게 작은 영역들을 돌아다니면, 뉴런들은 방향성, 꼭지점 커브 등과 같은 기초적인 특징들을 추출할 수 있다. 이러한 특징들은 뒤에 이어서 계산되는 레이어에서 더 높은 차원의 특징들을 구성할 수 있도록 합성된다. 때문에 전체 이미지에서 왜곡이나 움직임이 발생하여도 결국엔 각 클래스를 구분짓는 패턴 특징이 local receptive field에서 만나기 때문에 해당 특징을 반영한 feature map을 만들어 낼 수 있다.
Shared weight
여기서 Shared weights 특성이란 convolution을 위해 filter를 적용할 때, filter가 적용된 결과(local receptive field)는 계속 변경되지만, 적용하는 filter(weight) 값은 변하지 않는 것을 의미합니다. 한마디로 동일한 weight가 convolution할 때, 동일하게 적용(shared)되는 것을 의미합니다. 예를 들어 , 5x5 filter는 5x5 사이즈와 설정된 Stride에 맞춰 전체 이미지(or feature map)을 돌아다니며 계산을 하지만, 5x5 =25의 weight와 +1개의 bias만 back propagation으로 학습할 뿐이다. 이 처럼 계산되는 영역마다 학습 파라미터가 느는 것이 아니라, Filter가 총 몇개로 설정하는가에 따라 output인 feature map의 수와 학습해야하는 parameter가 늘 뿐이다. 이러한 기법으로 계산을 수행할 local machine에게 요구되어지는 총 계산 capacity를 줄여주고, 학습할 parameter의 수를 줄여줌으로써 자연스럽게 Overfitting을 방지하게 되어 test error와 training error 사이의 gap도 줄여준다.
Sub-sampling
sub-sampling은 우리가 알고 있는 Pooling이라는 개념과 같다. LeNet-5에서는 Average Pooling을 사용한다. local feature로 부터 입력된 데이터의 translation, distortion에 관계없이 위상에 영향을 받지 않는 global feature를 추출하기 위해 사용한다. 해당 과정을 거치고 classification을 진행하게 된다. 논문에서 한번 특징이 검출되면 위치 정보의 중요성이 떨어진다고 말한다. 예를 들어, 입력 이미지가 7 이면 좌측 상당에 수평적인 end-point, 우측 상단에 corner, 이미지의 아래 부분에 수직적인 end-point를 포함한다. 이러한 각 특징의 위치 정보는 패턴을 식별하는 것과 무관할 뿐만 아니라, 입력값에 따라 특징이 나타나는 위치가 다를 가능성이 높기 때문에 잠재적으로 유해하다. 때문에 저자는 feature map으로 encoding 되는 특징들의 위치에 대한 정확도를 감소시키기 위한 가장 간단한 방법은 feature map의 해상도를 감소시키는 것이라고 말한다. sub-sampling layer에서 local average와 sub-sampling을 수행하여 feature map의 해상도를 감소시키고 distortion과 shift에 대한 민감도를 감소시킬 수 있다고 말합니다. 또 위치 정보를 소실시키면서 생기는 손실은, feature map size가 작아질수록 더 많은 filter를 사용하여 다양한 feature를 추출하여 상호보완할 수 있도록 한다.
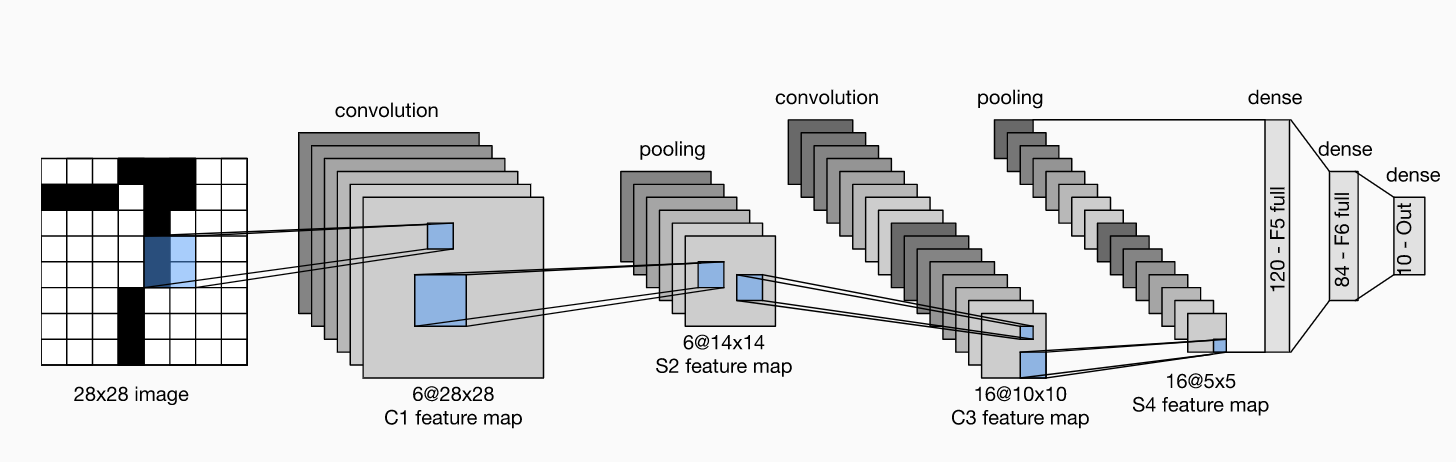
LeNet-5 구조
아래 그림이 “Gradient-based learning applied to document recognition”에서 제안했던 LeNet-5의 Architecture이다. LeNet-5는 Convolution layer(C1,C3,C5) 3개, Subsampling layer(S2, S4) 2개, Fully connected layer(F6) 1개로 구성되어있다.C1~F6 Layers 활성화 함수는 tanh이다.

C1, S2(Convolution and subsampling)
입력 이미지 (32 x 32)을 6개의 필터(5x5)와 Convolution하여 28x28 Feature map 6장을 생성한다. 그리고 이를 2x2 SubSampling(Average pooling 사용)으로 14 x 14 Feature map 6개를 만든다.
C3, S4 (Convolution and subsampling)
여기서 다시 5x5 Filter로 Convolution하여 10x10 Feature map 16개를 만들고(즉, 6장의 14x14 Feature map으로터 16장의 10x10 Feature map을 산출해낸다.), 이를 2x2 Subsampling (Average pooing 사용)하여 5x5 Feature map 16개를 만든다. 참고로 여기서 각 Filter의 값들은 지정하는 것이 아니라 학습을 통해 결정된다. 6개의 모든 Feature map이 16개의 Filter처리 하는 것이 아니라 아래 Table과 같이 선택적으로 입력 영상을 선택하여 반영했다. 이 과정에서 6개의 feature map을 처음 6개는 연속되게 이웃하는 3개의 featuremap들의 조합에서 구하고, 그 다음 6개는 연속되게 이웃하는 4개 feature maps의 조합, 그 다음 3개는 sparse하게 남는 4개의 조합, 그리고 마지막 16번째는 6개를 모두 반영한 feature를 뽑을 수 있도로 구성했다. 그 이유는 연산량의 크기를 줄이고, 연결의 symmetry(대칭)를 깨줌으로써 처음 convolution으로부터 얻은 6개의 low-level feature가 서로 다른 조합으로 섞이며 global feature로 나타나기를 기대하기 때문이다. 아래 Table에서 보면 1열의 값들 0~5는 S2 Layer에서의 피쳐맵들이고, 1행의 0~15는 16장의 필터를 뜻한다.

C5, F6 (Convolution and fully connection)
한 번 더 5x5 Feature map 16개를 5x5 Filter로 Convolution 하여 1x1 Feature map 120개를 만든다. 이렇게 만들어진 120개의 Feature map을 크기가 84인 Fully connected layer에 연결한다. 마지막으로 크기가 10인 Layer와 연결하여 최종적으로 10개의 Class를 구분할 수 있게 만들었다.
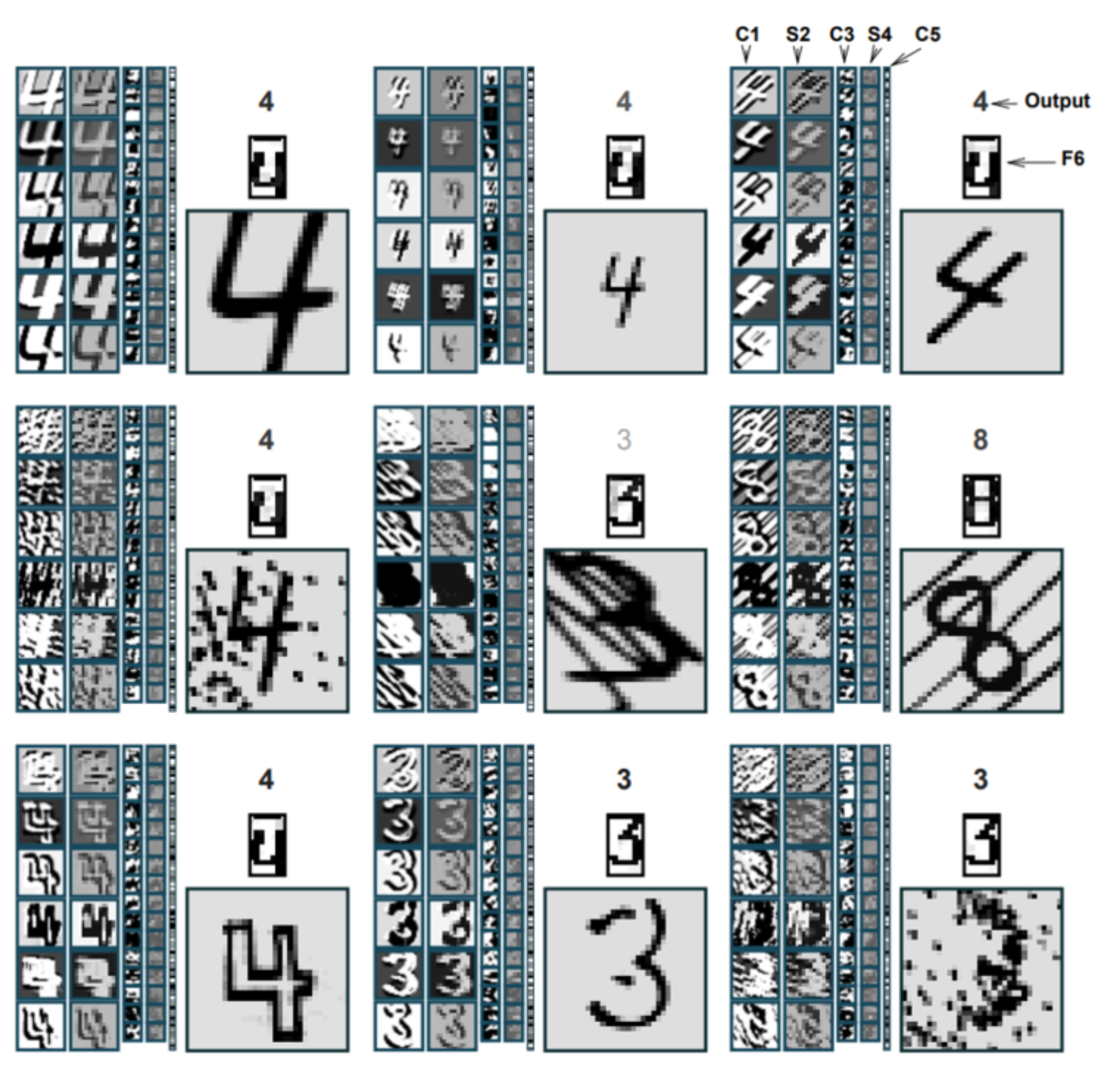
아래 그림은 LeNet-5에서 C1, S2, C3, S4, C5, F6에서 이미지가 변환된 결과를 보여주는 그림이다. 여기서 C1과 C3는 Convolution 결과이고, S2와 S4는 Subsampling 결과이다. C1/S2, C3/S4, C5 단계를 거치면서 Topology 변화에 강한 Feature를 생성한 후, F6의 Fully connected layer를 지나 Output layer로 전달되어 최종적으로 숫자를 인식하게 된다. 이러한 Convolution과 Subsampling 과정으로 Topological 변화에 강한 Global feature를 얻었기 때문에 Noise가 상당한 경우에도 잘 구분하는 것을 볼 수 있다.
참고 자료
LeNet — Organize everything I know documentation
그 이후로 계속 개선하여 최종적으로 1998년에 LeNet-5를 발표했다. LeNet-5에서는 입력 이미지의 크기가 커졌고, Fully connected layer가 추가되었다. LeNet-1에서는 16x16로 이미지를 줄이고 28x28 중앙에 위
oi.readthedocs.io
LeNet - 1998
Convolution의 시작. 딥러닝 조상님 LeNet 리뷰! | DO NOT REINVENT THE WHEEL. 위의 격언처럼, 역사적으로 어떠한 기존의 한계 때문에 어떤 시도들을 해왔는지, 또 그런 시도들이 현대에 와서는 어떤 것으로
brunch.co.kr
LeNet-5
Yann LeCun (얀 르쿤)의 "Gradient-based learning applied to document recognition" 논문에서 손글씨 숫자 인식하는데 문제를 해결하기 위해 사용된 모델 기존의 Fully-Connected Neural Network가 가지고 있는..
my-coding-footprints.tistory.com
[논문 리뷰] LeNet-5 (1998), 파이토치로 구현하기
가장 기본적인 CNN 구조인 LeNet-5 논문을 읽어보고 파이토치로 직접 구현해보면서 CNN에 대한 이해도를 높여보겠습니다. LeNet-5은 1998년 Yann LeCun의 논문 'Gradient-Based Learning Applied to Document Re..
deep-learning-study.tistory.com