

Abstract
CNN을 이용하여 시공간 비디오를 학습하는 것은 어렵다. 몇몇 연구에서는 3D Convolution을 이용하여 비디오의 공간적 차원과 시간적 차원을 모두 학습할 수 있는 접근 방식이라는 것을 보여줬다. 그러나 3D CNN의 경우 네트워크가 깊으면 높은 계산 비용과 메모리가 발생한다. 이에 논문에서는 3D CNN에 기존 2D 네트워크에서 사용된 ResNet을 변형하여 사용한다. 본 논문에서는 3x3x3 Convolution을 대신하는 병렬 또는 cas-caded 방식으로 1x3x3 Convolution 층과 3x1x1 Convolution 층을 조합하여 feature map에 시간적 연결을 구축한다. 이때 저자는 한 가지의 방식을 제안하는 것이 아닌 residual learning framework에서 bottleneck building blocks의 여러 변형을 설계하고 제안한다. 아래 이미지에서 P3D-A, P3D-B, P3D-C가 이에 해당된다. 또한, 우리는 Pseudo-3D Residual Net(P3D ResNet)이라는 새로운 Architecture를 제안한다. 이 Architecuture는 위의 P3D-A, P3D-B, P3D-C를 모두 사용한다. 우리의 3D ResNet은 Sports-1M 비디오 분류 데이터 세트에서 각각 5.3%와 1.8% 개선을 달성했다.
Introduction
비디오는 큰 변형과 복잡성을 가지고 있어 CNN을 이용하여 프레임의 시공간 표현을 학습하는데 어려움이 있다. 시공간 정보를 학습하는데 자연스러운 방법 중 하나는 CNN의 Convolution을 2D에서 3D로 확장하고 새로운 3D CNN을 학습시키는 것이다. 최근 연구에서 고무적인 성능이 보고되고 있지만 3D CNN의 훈련은 계산 비용이 매우 많이 들고 모델 크기도 2D CNN에 비해 quadratic growth가 증가한다.
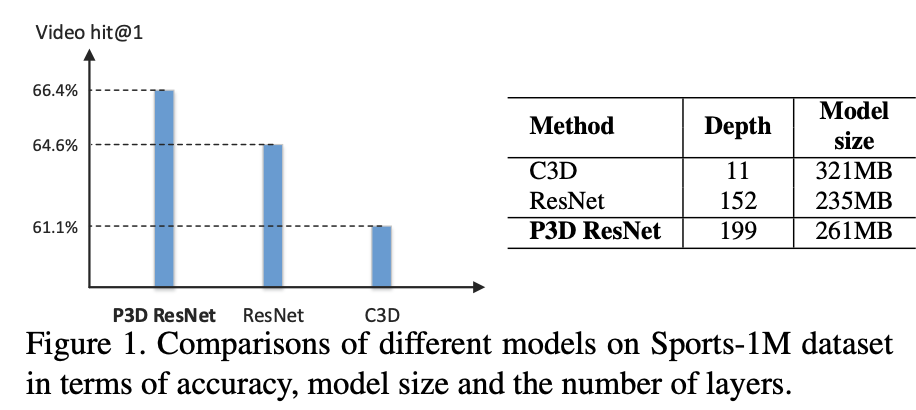
3D CNN에서 널리 사용되는 11 계층의 네트워크가 152 계층 ResNet보다 훨씬 큰 321MB에 이른다. 때문에 매우 깊은 3D CNN을 훈련하기가 매우 어렵다. 더 중요한 것은 Sports-1M Data set에서 ResNet-152를 미세 조정하면 아래 이미지와 같이 3D CNN보다 더 좋은 정확도를 얻을 수 있는 것을 확인할 수 있다.
시공간 비디오 표현을 생성하는 또 다른 대안은 프레임의 표현에 대해 Pooling strategy이나 RNN을 사용하는 것이다. 그러나 이 접근 방식은 top layer의 high-level features의 시간적 연결만 구축하며 동시에 low-level의 상관관계를 완전히 이용하지 않는다. 우리는 이 논문에서 공간 및 시간 Convolution filter를 모두 활용하는 bottleneck building blocks을 고안하여 위의 제한을 완화할 수 있는 것을 보여준다. 구체적으로 각 블록의 핵심 구성 요소는 표준 3x3x3 컨볼루션 층을 대신하는 병렬 또는 캐스케이드 방식으로 1개의 1x3x3 컨볼루션 층과 3x1x1 컨볼루션 층의 하나의 층을 조합한 것이다. 이와 같이 2D CNN에서 1x3x3 Convolution filter를 3x3 Convolution으로 초기화함으로써 모델 크기가 크게 줄어들고 이미지 영역에서 사전 학습된 2D CNN의 이점을 충분히 활용할 수 있다. 또한, 네트워크의 구조적 다양성을 높이기 위해 전체 ResNet과 같은 아키텍처를 통해 각 설계된 블록을 서로 다른 배치로 구성하는 새로운 Pseudo-3D Residual Net(P3D ResNet)을 제안한다.
P3D Blocks and P3D ResNet
이 섹션에서는 먼저 공간 정보를 학습하기 위한 2D spatial convolutions과 시간 차원에 대한 1D temporal convolutional으로 자연스럽게 분리될 수 있는 비디오 표현 학습을 위한 3D convolutions을 정의한다. 그런 다음, 공간 및 시간 convolutional filter를 모두 활용하기 위해 P3D(Pseudo-3D)라는 bottleneck building blocks의 새로운 residual learning framework을 고안했다. 마지막으로 우리는 ResNet과 같은 아키텍처의 다른 배치에서 각 P3D 블록을 구성하는 새로운 P3D ResNet을 개발하고 성능과 시간 효율성 측면에서 실험적 연구를 통해 여러 변형을 추가로 비교한다.
1. 3D Convolutions
c × l × h × w의 크기를 가진 비디오 클립이 주어졌을 때, 여기서 c, l, h, w는 각각 각 프레임의 채널 수, 클립 길이, 높이 및 폭을 나타낸다. 3D Convolution은 2D 필터와 같은 공간 정보를 동시에 모델링하고 프레임 간에 시간적 연결을 구성합니다. 단순화를 위해 3d 컨볼루션 필터의 크기를 d x k x k로 표시한다. 여기서 d는 filter의 시간적 깊이이고 k는 filter의 공간 크기이다. 따라서, 우리가 3 x 3 x 3 크기의 3D Convolution filter를 가지고 있다고 가정하면, 공간 도메인에 있는 2D CNN에 해당하는 1 x 3 x 3 Convolution filter와 시간 도메인에 맞춘 1D CNN과 같은 3 x 1x 1 Convolution filter로 자연스럽게 분리될 수 있습니다. 이러한 decoupled(분리된) 3D convolutions은 모델 크기를 크게 줄일 뿐만 아니라 이미지 데이터로부터 2D CNN의 pre-training을 가능하게 하여 이미지로부터 장면과 사물에 대한 지식을 활용할 수 있는 능력을 3D CNN에 부여한다.
2. Pseudo-3D Blocks
다음으로 ResNet에서 Residual Units의 기본 설계를 다시 확인하고 P3D blocks을 고안하는 방법을 제시합니다.
Residual Units
ResNet은 많은 staked Residual Units로 구성되며 각 Residual Units은 식(1)과 같다.

여기서 xt와 xt+1은 t번째 Residual Unit의 입력 및 출력을 나타내며, h(xt) = xt는 identity mapping이고 F는 비선형 residual function이다. 따라서 식(1)은 다음과 같이 다시 쓸 수 있다.

여기서 F * xt는 xt에 대해 residual function F를 수행한 결과를 나타낸다.
P3D Blocks design.
ResNet의 각 2D Residual Unit을 시공간 비디오 정보 인코딩을 위한 3D 아키텍처로 개발하기 위해 3.1절에서 소개한 Pseudo 3D 원리에 따라 ResNet의 기본 Residual Unit을 수정하고 여러 Pseudo-3D 블록을 고안합니다. 이러한 변경은 2가지 설계 이슈를 가지고 있어 간단하지 않다.
첫 번째 이슈는 공간 차원 (S)에 있는 2D 필터와 시간 영역(T)에 있는 1D 필터의 모듈이 직간접적으로 서로 영향을 주어야 하는지에 관한 것이다. 두 가지 유형의 필터 내에서 직접적인 영향은 공간 2D 필터의 출력이 임시 1D 필터의 입력으로 연결된다는 것을 의미한다.(즉, cas-caded 방식으로) 두 필터 사이의 간접적인 영향은 연결을 분리하여 네트워크의 다른 경로에 있도록 한다.(즉, 병렬 방식으로)
두 번째 문제는 두 종류의 필터가 모두 최종 출력에 직접적인 영향을 주어야 하는지 여부입니다. 이 문맥에서 직접적인 영향은 각 유형의 필터의 출력이 최종 출력에 직접 연결되어야 함을 나타냅니다.
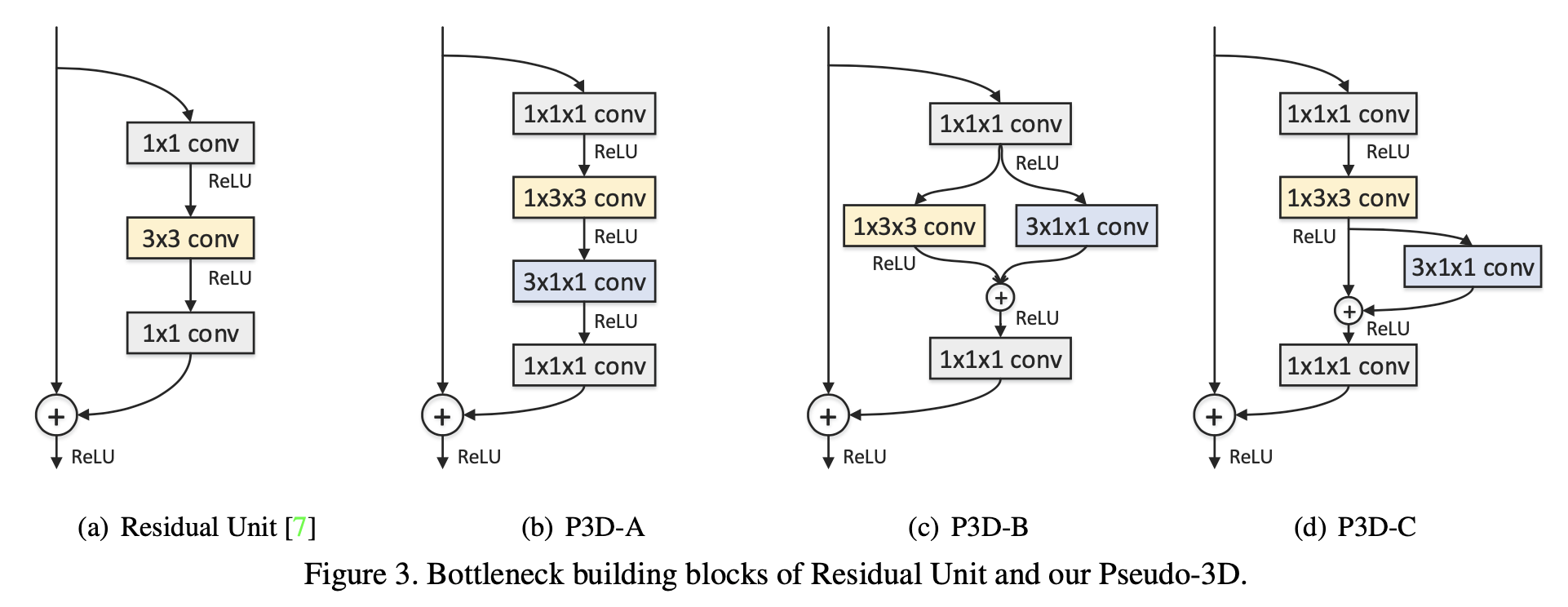
두 가지 설계 문제를 바탕으로 그림 2에 표시된 바와 같이 각각 P3D-A에서 P3D-C로 명명된 세 가지 P3D블록을 도출한다. 이러한 Architecture에 대한 자세한 비교는 다음과 같다.
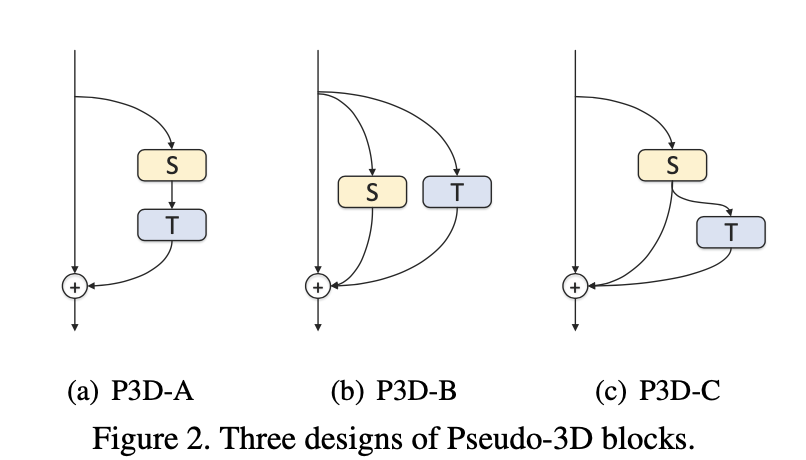
(a) P3D-A : 첫 번째 설계에서는 시간적 1D 필터(T)가 공간적 2D 필터(S)를 cas-caded 식으로 따르도록 하여 stacked Architecture구조를 고려한다. 따라서 두 종류의 필터는 동일한 경로에서 서로 직접적인 영향을 미칠 수 있으며 시간적 1D 필터만 최종 출력에 직접 연결된다.

(2) P3D-B : 두 번째 설계는 두 필터 사이의 간접적인 영향을 채택하고 두 필터가 병렬 방식으로 서로 다른 경로에 있다는 점을 제외하면 첫 번째 설계와 유사하다. 비록 S와 T 사이에 직접적인 영향은 없지만, 두 가지 모두 최종 산출물에 직접 누적되어 다음과 같이 표현될 수 있다.

(3) P3D-C : 마지막 설계는 S, T, 최종 출력물 사이에 직간접적인 영향을 동시에 구축함으로써 P3D-A와 P3D-B를 절충한 것이다. 특히 Cascaded P3D-A 아키텍처를 기반으로 S와 최종 출력을 직접 연결할 수 있도록 S에서 최종 출력까지의 바로 연결을 설정하여 출력 xt+1을 다음과 같이 만든다.
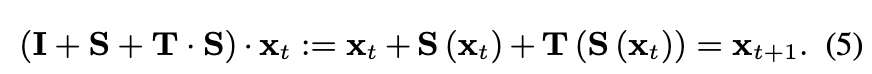
Bottleneck architectures
그림 3(a)에서 볼 수 있듯이 Residual Unit은 단일 공간 2D 필터(3x3 컨볼루션) 대신에 1x1, 3x3, 1x1 컨볼루션의 스택을 채택한다. 여기서 입력 샘플의 치수 감소와 복원을 위해 각각 첫 번째와 마지막 1 x1 convolution solutions가 적용된다.
하나의 공간 2D filter(1x3x3 Convolution)와 하나의 시간 1D filter(3x1x1 Convolution션)로 구성된 각 P3D 블록에 대해, 우리는 추가적으로 경로의 양 끝에 두 개의 1x1x1 컨볼루션을 배치하여 크기를 줄이고 늘린다. 따라서 이러한 bottleneck design를 통해 공간 2D filter와 임시 1D fileter의 입출력 치수가 모두 감소된다.
3. Pseudo-3D ResNet
3개의 P3D 블록의 장점을 검증하기 위해 먼저 P3D-A ResNet, P3D-B ResNet, P3D-C ResNet, ResNet-50의 모델 간의 성능 및 시간 효율성 비교를 제시한다. 그런 다음, 구조적 다양성의 관점에서 세 개의 P3D 블록을 모두 혼합하여 완전한 버전의 P3D ResNet을 제안한다.

Mixing different P3D Blocks.
다양한 P3D 블록을 혼합하여 P3D ResNet의 완전한 버전을 만들었다. 여기서 Residual Units은 P3D-A -> P3D-B -> P3D-C 순으로 P3D 블록이 교체된다. P3D ResNet은 구조적 다양성을 추가로 P3D-A ResNet, P3D-B ResNet 및 P3D-C ResNet에 비해 정확도가 각각 0.5%, 1.4% 및 1.2%으로 향상됐다.

참고문헌
Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks
Convolutional Neural Networks (CNN) have been regarded as a powerful class of models for image recognition problems. Nevertheless, it is not trivial when utilizing a CNN for learning spatio-temporal video representation. A few studies have shown that perfo
arxiv.org