

1. Seaborn 소개
Seaborn은 Matplotlib을 기반으로 한 파이썬 데이터 시각화 라이브러리입니다. Seaborn은 통계를 중심으로 설계되어 있으며, 좀 더 복잡한 그래프를 간단한 코드로 구현할 수 있게 해줍니다. 또한, Seaborn은 보다 퀄리티 있는 그래픽과 복잡한 그래프 기능을 제공하며, Pandas 데이터프레임과 잘 연동됩니다.
2. Matplotlib와 Seaborn의 차이점
- 디자인 : Seaborn은 Matplotlib를 기반으로 하여 통계용 그래프를 그리는데 특화되어 있습니다. 기본적인 테마와 색상 팔레트가 있어 그래프를 향상시키며, 이는 Matplotlib보다 시각적으로 매력적인 그래프를 생성합니다.
- 코드 길이 : Seaborn의 통계 그래픽 함수는 Matplotlib에 비해 코드를 줄일 수 있습니다.
- 데이터 핸들링 : Seaborn은 Pandas 데이터프레임과 잘 작동하며, 데이터프레임 내의 문자열 변수를 자동으로 인식하여 범주형 변수로 처리합니다.
3. Seaborn 내장 데이터셋 사용하기
Seaborn은 다양한 예제 데이터 세트를 포함하고 있습니다. 이들은 다양한 유형의 데이터 시각화를 실습하거나, 새로운 시각화 방법을 실험하는 데 유용합니다.
아래는 Seaborn에서 사용 가능한 내장 데이터셋으로 anagrams, anscombe, attention, brain_networks, car_crashes, diamonds, dots, dowjones, exercise, flights, fmri, geyser, glue, healthexp, iris, mpg, penguins, planets, seaice, taxis, tips, titanic 총 22가지가 있습니다. 이 중 많이 사용되는 데이터셋은 아래와 같습니다.
3.1 iris
Iris 종에 따른 꽃잎과 꽃받침의 길이와 폭을 측정한 데이터셋입니다. 아래 코드는 iris 데이터 셋을 불러오는 코드입니다.
import seaborn as sns
# 내장 데이터셋 'iris' 로드
df = sns.load_dataset('iris')
#iris dataset:
# sepal_length sepal_width petal_length petal_width species
#0 5.1 3.5 1.4 0.2 setosa
#1 4.9 3.0 1.4 0.2 setosa
#2 4.7 3.2 1.3 0.2 setosa
#3 4.6 3.1 1.5 0.2 setosa
#4 5.0 3.6 1.4 0.2 setosa
3.2 mpg
1998년부터 2008년까지 출시된 여러 가지 자동차 모델에 대한 연비, 실린더, 배기량 등의 데이터를 포함하는 데이터셋입니다. 아래 코드는 mpg 데이터 셋을 불러오는 코드입니다.
import seaborn as sns
# 내장 데이터셋 'mpg' 로드
df = sns.load_dataset('mpg')
#mpg dataset:
# mpg cylinders displacement ... model_year origin name
#0 18.0 8 307.0 ... 70 usa chevrolet chevelle malibu
#1 15.0 8 350.0 ... 70 usa buick skylark 320
#2 18.0 8 318.0 ... 70 usa plymouth satellite
#3 16.0 8 304.0 ... 70 usa amc rebel sst
#4 17.0 8 302.0 ... 70 usa ford torino
3.3 penguins
Palmer Archipelago의 펭귄들의 bill 길이, bill depth, flipper length, body mass 등에 대한 데이터셋입니다.
import seaborn as sns
# 내장 데이터셋 'penguins' 로드
df = sns.load_dataset('penguins')
#penguins dataset:
# species island bill_length_mm ... flipper_length_mm body_mass_g sex
#0 Adelie Torgersen 39.1 ... 181.0 3750.0 MALE
#1 Adelie Torgersen 39.5 ... 186.0 3800.0 FEMALE
#2 Adelie Torgersen 40.3 ... 195.0 3250.0 FEMALE
#3 Adelie Torgersen NaN ... NaN NaN NaN
#4 Adelie Torgersen 36.7 ... 193.0 3450.0 FEMALE
3.4 tips
식사 금액, 팁, 성별, 흡연 여부, 요일, 시간, 사람 수 등에 대한 정보를 담고 있는 레스토랑 데이터셋입니다.
import seaborn as sns
# 내장 데이터셋 'tips' 로드
df = sns.load_dataset('tips')
#tips dataset:
# total_bill tip sex smoker day time size
#0 16.99 1.01 Female No Sun Dinner 2
#1 10.34 1.66 Male No Sun Dinner 3
#2 21.01 3.50 Male No Sun Dinner 3
#3 23.68 3.31 Male No Sun Dinner 2
#4 24.59 3.61 Female No Sun Dinner 4
3.5 titanic
타이타닉호의 승객들에 대한 나이, 성별, 클래스, 생존 여부 등의 정보를 포함하는 데이터셋입니다.
import seaborn as sns
# 내장 데이터셋 'titanic' 로드
df = sns.load_dataset('titanic')
#titanic dataset:
# survived pclass sex age ... deck embark_town alive alone
#0 0 3 male 22.0 ... NaN Southampton no False
#1 1 1 female 38.0 ... C Cherbourg yes False
#2 1 3 female 26.0 ... NaN Southampton yes True
#3 1 1 female 35.0 ... C Southampton yes False
#4 0 3 male 35.0 ... NaN Southampton no True
4. Seaborn 그래프 스타일
4.1 set_style()
Seaborn에서는 set_style()을 통해 스타일 테마를 설정할 수 있습니다. Seaborn에서 제공하는 스타일 테마는 Darkgrid, Whitegrid, Dark, White가 있습니다. 아래 코드는 set_style()을 사용하여 스타일 테마를 적용하는 예제입니다. 아래 이미지는 Darkgrid, Whitegrid, Dark 이미지입니다.



import seaborn as sns
import matplotlib.pyplot as plt
# 테마 설정
sns.set_style("darkgrid")
# 임의의 데이터를 이용해 그래프 그리기
tips = sns.load_dataset("tips")
sns.boxplot(x=tips["total_bill"])
plt.show()
4.2 set_context()
set_context() 함수는 그래프의 스케일(scale)을 설정하는데 사용됩니다. 이는 플롯의 요소 크기를 제어합니다. Seaborn은 paper, notebook, talk, poster로 총 4개의 context를 제공하고 있으며, 각각 다른 프로그램에 최적화되어 있습니다. 아래 이미지는 paper, notebook, poster 이미지 입니다.
- paper : 가장 작은 스케일로 출판물용으로 적합합니다.
- notebook : 주피터 노트북 등에서 그래프를 그릴 때 일반적으로 사용합니다.
- talk : 큰 그림을 필요로 하는 강연이나 프레젠테이션에 적합합니다.
- poster : 큰 포스터와 같이 매우 큰 그림에 적합합니다.

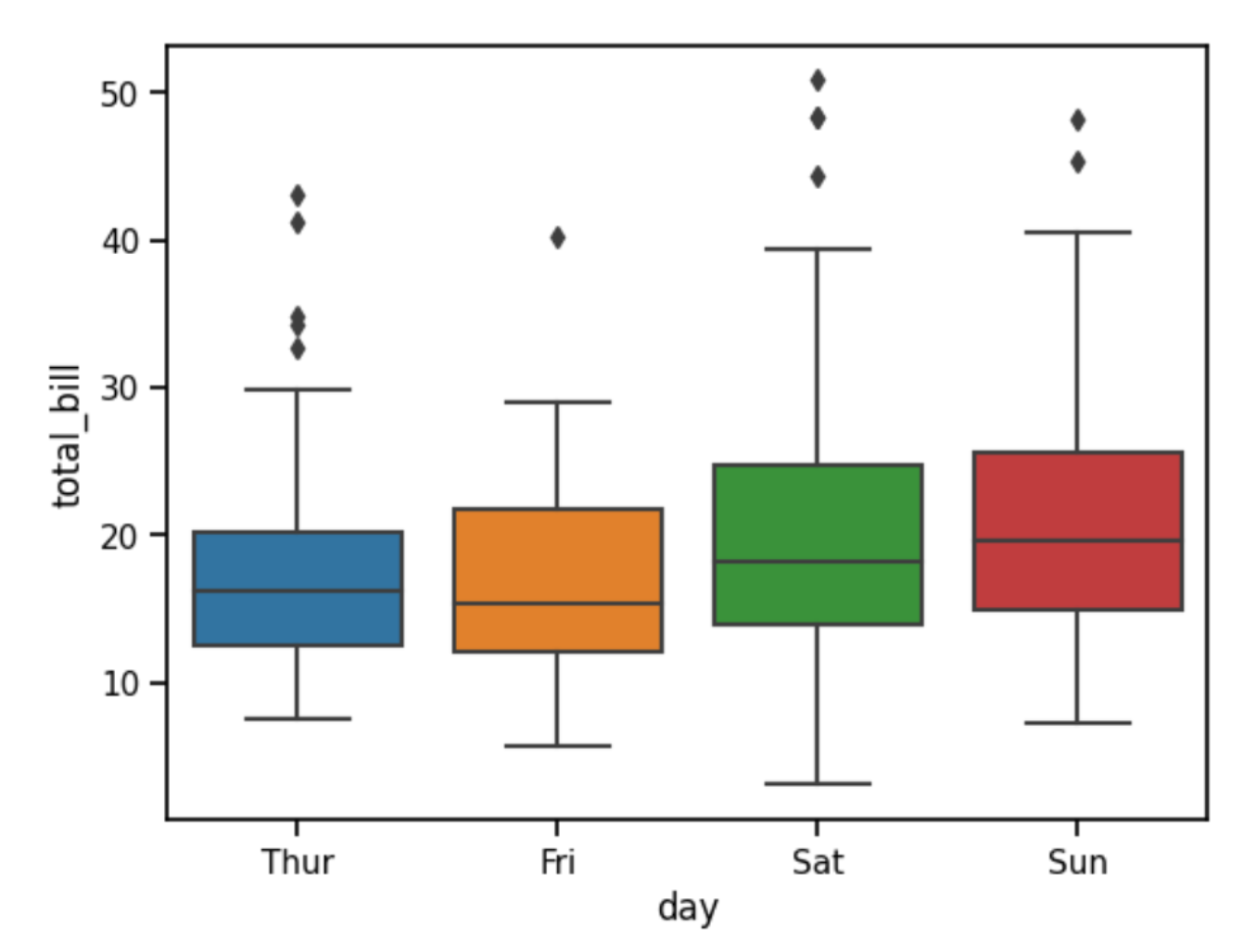
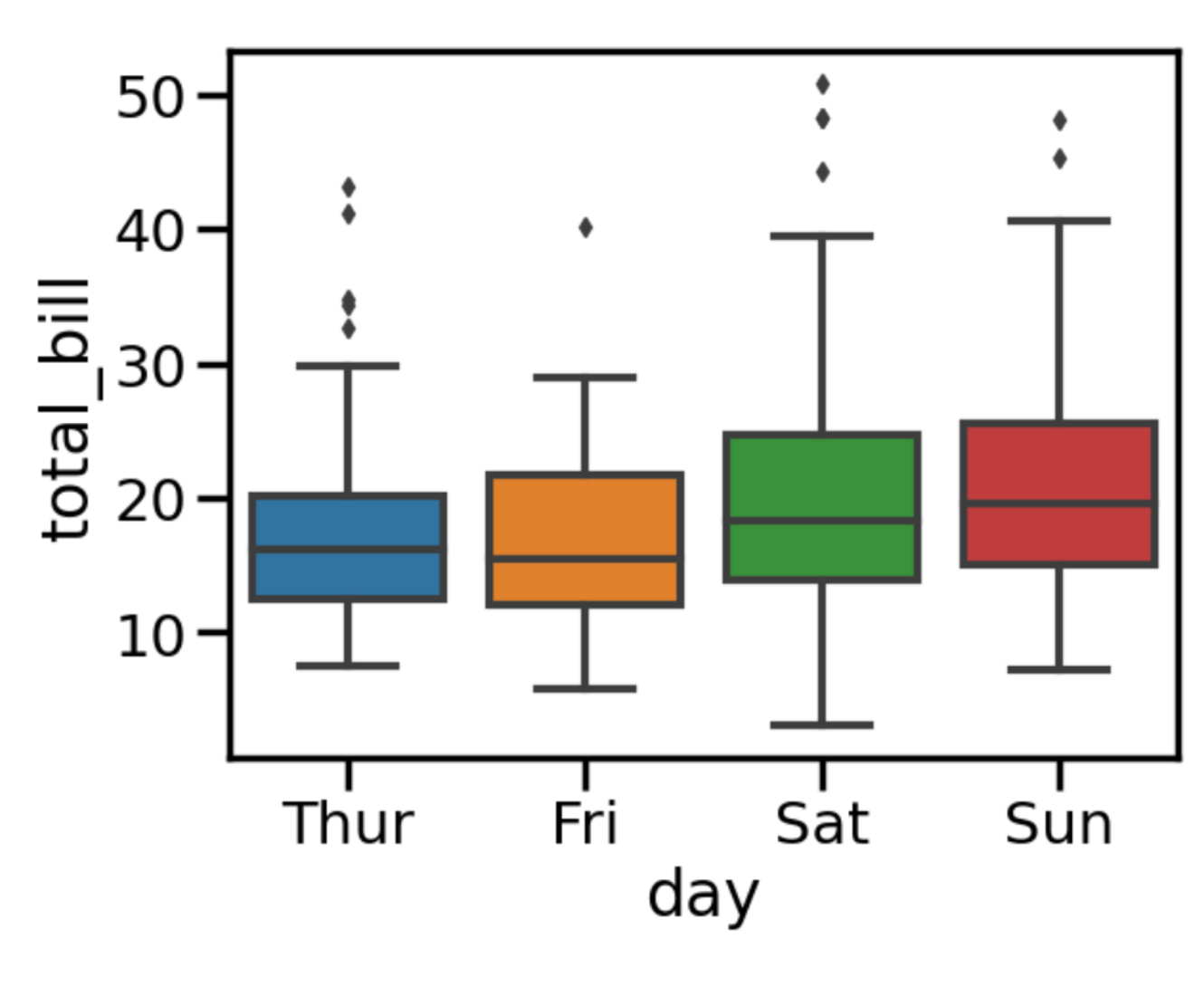
import seaborn as sns
import matplotlib.pyplot as plt
# 컨텍스트 설정
sns.set_context('poster')
# 이후에 그래프를 그릴 때, 설정한 컨텍스트가 적용됩니다.
sns.boxplot(data=sns.load_dataset('tips'), x='day', y='total_bill')
plt.show()
4.3 set_palette()
sns.color_palette() 함수를 사용해 색상 팔레트를 설정할 수 있습니다. 이 함수는 색상 리스트를 반환하며, 이를 sns.set_palette() 함수에 전달하여 전역 색상 팔레트를 설정할 수 있습니다. Seaborn은 다양한 색상 팔레트를 제공합니다. 대표적인 것들은 deep, muted, bright, pastel, dark, colorblind와 같습니다. 또한, Seaborn은 색상의 구성 요소를 명시적으로 지정하여 커스텀 색상 팔레트를 생성하는 것도 가능하게 합니다. 이를 위해서는 아래 코드 처럼 set_palette() 함수에 색상 문자열의 리스트를 전달하면 됩니다. 아래 이미지는 Seaborn에서 제공하는 husl 팔레트와 명시적으로 지정한 커스텀 팔레트를 통한 결과물입니다.


import seaborn as sns
import matplotlib.pyplot as plt
# 컨텍스트 설정
sns.set_context('poster')
#Seaborn 팔레트 사용
#sns.set_palette(sns.color_palette("husl"))
#커스텀 팔레트 사용
custom_palette = ['#A239CA', '#DCD5E4', '#3CBB75', '#D4752E']
sns.set_palette(custom_palette)
# 이후에 그래프를 그릴 때, 설정한 컨텍스트가 적용됩니다.
sns.boxplot(data=sns.load_dataset('tips'), x='day', y='total_bill')
plt.show()
5. Seaborn 다양한 그래프
5.1 Relational Plots
relplot(), scatterplot(), lineplot() 등의 함수를 통해 관계형 그래프를 그릴 수 있습니다. 이러한 그래프는 두 변수 사이의 관계를 시각적으로 표현합니다.
5.1.1 relplot()
relplot()는 멀티 플롯 그리드를 활용하여 여러 개의 관계형 그래프를 그리는 데 유용합니다. relplot() 함수의 주요 매개변수는 아래와 같습니다.
- x, y : x축 및 y축에 그릴 데이터의 이름입니다. 이는 문자열로 제공되어야 합니다.
- hue : 색상으로 구분할 카테고리 변수의 이름입니다.
- style : 마커 스타일로 구분할 카테고리 변수의 이름입니다.
- size : 마커 크기로 구분할 카테고리 변수의 이름입니다.
- data : 그래프에 사용할 데이터프레임입니다.
- row, col : 각각의 행과 열에 표시할 카테고리 변수의 이름입니다. 이를 이용해 그리드를 만들 수 있습니다.
- kind : 그래프의 종류를 지정합니다. 'scatter'와 'line' 두 가지 중 선택할 수 있습니다.
- palette : 색상 팔레트를 지정합니다.
- height : 각 그래프의 높이를 설정합니다.
- aspect : 각 그래프의 가로 세로 비율을 설정합니다.

import seaborn as sns
# Load the example tips dataset
tips = sns.load_dataset("tips")
# Draw a relplot
sns.relplot(x="total_bill", y="tip", hue="day", style="time", size="size", data=tips, kind="scatter", palette="viridis", height=5, aspect=1.2)
5.1.2 scatterplot()
scatterplot()은 두 변수 간의 관계를 보여주는 산점도를 그리는 함수입니다. scatterplot() 함수의 주요 매개변수는 아래와 같습니다.
- x, y : x축 및 y축에 표시할 데이터의 이름입니다. 이는 문자열로 제공되어야 합니다.
- hue : 색상으로 구분할 카테고리 변수의 이름입니다.
- style : 마커 스타일로 구분할 카테고리 변수의 이름입니다.
- size : 마커 크기로 구분할 수치형 변수의 이름입니다.
- data : 그래프를 그리는 데 사용할 pandas 데이터프레임입니다.
- palette : 색상 팔레트를 지정합니다. 문자열, 리스트, 딕셔너리 등 다양한 형태로 지정할 수 있습니다.
- markers : 마커의 모양을 지정합니다. 문자열, 리스트, 딕셔너리 등으로 지정할 수 있습니다.

import seaborn as sns
# Load the example tips dataset
tips = sns.load_dataset("tips")
# Draw a scatterplot
sns.scatterplot(x="total_bill", y="tip", hue="day", style="time", size="size", data=tips, palette="viridis")
5.1.3 lineplot()
lineplot() 함수는 하나의 변수가 다른 변수에 대해 어떻게 변하는지 보여주는 선 그래프를 그립니다. 이 함수는 시간에 따른 변화나 순서가 있는 카테고리 변수 등의 데이터를 시각화하는데 유용합니다. lineplot() 함수의 주요 매개변수는 다음과 같습니다.
- x, y : x축 및 y축에 표시할 데이터의 이름입니다. 이는 문자열로 제공되어야 합니다.
- hue : 색상으로 구분할 카테고리 변수의 이름입니다.
- style : 선 스타일로 구분할 카테고리 변수의 이름입니다.
- size : 선 두께로 구분할 수치형 변수의 이름입니다.
- data : 그래프를 그리는 데 사용할 pandas 데이터프레임입니다.
- palette : 색상 팔레트를 지정합니다. 문자열, 리스트, 딕셔너리 등 다양한 형태로 지정할 수 있습니다.
- markers : 각 데이터 포인트에 마커를 그릴지 여부를 지정합니다. 기본적으로 False로 설정되어 있습니다.
- dashes : 각 선에 대해 dash pattern을 사용할지 여부를 지정합니다. 기본적으로 True로 설정되어 있습니다.

import seaborn as sns
# Load the example flights dataset
flights = sns.load_dataset("flights")
flights = flights.pivot("month", "year", "passengers")
# Draw a lineplot
sns.lineplot(data=flights)
5.2 Categorical Plots
catplot(), boxplot(), violinplot(), countplot(), barplot() 등의 함수를 통해 범주형 그래프를 그릴 수 있습니다. 이러한 그래프는 범주형 변수에 대한 분포를 시각화합니다.
5.2.1 catplot()
catplot() 함수는 범주형 변수와 하나 이상의 수치형 변수 간의 관계를 그리는 함수로, 여러 서브플롯을 그릴 수 있습니다.
- x, y : x축 및 y축에 표시할 데이터의 이름입니다. 이는 문자열로 제공되어야 합니다.
- hue : 색상으로 구분할 카테고리 변수의 이름입니다.
- data : 그래프를 그리는 데 사용할 pandas 데이터프레임입니다.
- row, col : 서브플롯을 나누는 기준이 될 컬럼의 이름입니다.
- kind : 그래프의 종류를 지정합니다. 'strip', 'swarm', 'box', 'violin', 'boxen', 'point', 'bar', 'count' 중에서 선택할 수 있습니다.
- height : 각 서브플롯의 높이를 설정합니다.
- aspect : 각 서브플롯의 가로 세로 비율을 설정합니다.
- palette : 색상 팔레트를 지정합니다.

import seaborn as sns
# Load the example tips dataset
tips = sns.load_dataset("tips")
# Draw a catplot
sns.catplot(x="day", y="total_bill", hue="sex", data=tips, kind="bar", palette="viridis", height=5, aspect=1)
5.2.2 boxplot()
boxplot() 함수는 주어진 데이터셋에 대한 다섯 가지 요약 통계량(최솟값, 하위 사분위수(Q1), 중위수(Q2 또는 중앙값), 상위 사분위수(Q3), 최댓값)을 나타내는 박스 플롯을 그립니다. 이를 통해 데이터의 전체적인 분포를 확인하거나 이상치를 찾는 등의 용도로 사용할 수 있습니다.
- x, y : x축 및 y축에 표시할 데이터의 이름입니다. 이는 문자열로 제공되어야 합니다.
- hue : 색상으로 구분할 카테고리 변수의 이름입니다.
- data : 그래프를 그리는 데 사용할 pandas 데이터프레임입니다.
- order, hue_order : 그래프에 표시될 범주들의 순서를 지정할 수 있습니다.
- color : 모든 박스의 색상을 지정합니다.
- palette : 색상 팔레트를 지정합니다. 문자열, 리스트, 딕셔너리 등 다양한 형태로 지정할 수 있습니다.
- width : 각 박스의 너비를 지정합니다.
- fliersize : 이상치의 마커 크기를 지정합니다.

import seaborn as sns
# Load the example tips dataset
tips = sns.load_dataset("tips")
# Draw a boxplot
sns.boxplot(x="day", y="total_bill", hue="smoker", data=tips, palette="Set3")
4.2.3 violinplot()
violinplot() 함수는 박스 플롯과 커널 밀도 추정(KDE)을 결합하여 데이터의 분포와 밀도를 한 번에 표시하는 그래프를 그립니다. violinplot() 함수의 주요 매개변수는 다음과 같습니다.
- x, y : x축 및 y축에 표시할 데이터의 이름입니다. 이는 문자열로 제공되어야 합니다.
- hue : 색상으로 구분할 카테고리 변수의 이름입니다.
- data : 그래프를 그리는 데 사용할 pandas 데이터프레임입니다.
- order, hue_order : 그래프에 표시될 범주들의 순서를 지정할 수 있습니다.
- bw : 커널 밀도 추정에 사용될 밴드폭입니다. 이 값이 클수록 부드러운 곡선이 그려집니다.
- cut : 바이올린 그래프의 테일을 얼마나 길게 그릴 것인지 결정합니다.
- scale : 바이올린 그래프의 너비를 결정하는 방식입니다. 'area', 'count', 'width' 중 하나를 선택할 수 있습니다.
- inner : 바이올린 내부에 그려질 그래프를 선택합니다. 'box', 'quartile', 'point', 'stick', None 중 하나를 선택할 수 있습니다.
- split : 각 바이올린을 두 개의 카테고리에 따라 나눌 것인지 결정합니다. hue 매개변수가 주어져야 사용할 수 있습니다.
- palette : 색상 팔레트를 지정합니다. 문자열, 리스트, 딕셔너리 등 다양한 형태로 지정할 수 있습니다.

import seaborn as sns
# Load the example tips dataset
tips = sns.load_dataset("tips")
# Draw a violinplot
sns.violinplot(x="day", y="total_bill", hue="smoker", data=tips, palette="muted", split=True)5.2.4 countplot()
countplot() 함수는 범주형 열에 대한 빈도수를 막대 그래프 형태로 표시하는 함수입니다. countplot() 함수의 주요 매개변수는 다음과 같습니다.
- x, y : x축 혹은 y축에 표시할 데이터의 이름입니다. 이는 문자열로 제공되어야 합니다. 이 둘 중 하나만 지정해야 합니다.
- hue : 색상으로 구분할 카테고리 변수의 이름입니다.
- data : 그래프를 그리는 데 사용할 pandas 데이터프레임입니다.
- order, hue_order : 그래프에 표시될 범주들의 순서를 지정할 수 있습니다.
- palette : 색상 팔레트를 지정합니다. 문자열, 리스트, 딕셔너리 등 다양한 형태로 지정할 수 있습니다.
- saturation : 막대의 색상 채도를 설정합니다. 0부터 1 사이의 값을 지정합니다.
- dodge : hue 매개변수가 지정되었을 때, 막대를 분리하여 그릴 것인지, 하나로 합쳐서 그릴 것인지 결정합니다. 기본값은 True입니다.

import seaborn as sns
# Load the example tips dataset
tips = sns.load_dataset("tips")
# Draw a countplot
sns.countplot(x="day", hue="smoker", data=tips, palette="viridis")
5.2.5 barplot()
barplot() 함수는 범주형 데이터에 대한 막대 그래프를 그리는 함수입니다. 각 범주에 대해 데이터의 평균과 신뢰 구간을 계산하고 표시합니다.
- x, y : x축 및 y축에 표시할 데이터의 이름입니다. 이는 문자열로 제공되어야 합니다.
- hue : 색상으로 구분할 카테고리 변수의 이름입니다.
- data : 그래프를 그리는 데 사용할 pandas 데이터프레임입니다.
- order, hue_order : 그래프에 표시될 범주들의 순서를 지정할 수 있습니다.
- palette : 색상 팔레트를 지정합니다. 문자열, 리스트, 딕셔너리 등 다양한 형태로 지정할 수 있습니다.
- saturation : 막대의 색상 채도를 설정합니다. 0부터 1 사이의 값을 지정합니다.
- ci : 신뢰 구간을 계산하는 데 사용되는 신뢰 수준입니다. None으로 설정하면 신뢰 구간이 그려지지 않습니다.
- capsize : 신뢰 구간을 나타내는 막대(caps)의 너비를 설정합니다.
- dodge : hue 매개변수가 지정되었을 때, 막대를 분리하여 그릴 것인지, 하나로 합쳐서 그릴 것인지 결정합니다. 기본값은 True입니다.

import seaborn as sns
# Load the example tips dataset
tips = sns.load_dataset("tips")
# Draw a barplot
sns.barplot(x="day", y="total_bill", hue="smoker", data=tips, palette="Set2", capsize=.2)
5.3 Distribution Plots
kdeplot(), histplot(), rugplot() 등의 함수를 통해 분포 그래프를 그릴 수 있습니다. 이러한 그래프는 변수의 분포를 시각화합니다.
5.3.1 kdeplot()
kdeplot() 함수는 커널 밀도 추정(Kernel Density Estimation, KDE)을 사용하여 데이터의 밀도를 표시하는 그래프를 그립니다. 이는 데이터의 분포를 시각적으로 나타내는 데 유용합니다. kdeplot() 함수의 주요 매개변수는 다음과 같습니다.
- data : 그래프를 그리는 데 사용할 데이터입니다. 일차원 배열이나 리스트를 입력합니다.
- data2 : 두 번째 데이터 세트입니다. data2가 주어지면 2차원 KDE를 그립니다.
- shade : True로 설정하면, KDE 곡선 아래의 영역이 색칠됩니다.
- vertical : True로 설정하면, y축에 대한 KDE를 그립니다.
- kernel : 커널 종류를 설정합니다. 가능한 값은 {‘gau’ | ‘cos’ | ‘biw’ | ‘epa’ | ‘tri’ | ‘triw’ }입니다.
- bw : 커널의 밴드폭을 설정합니다. 이 값이 클수록 부드러운 KDE를 얻습니다.
- gridsize : KDE를 계산할 그리드의 크기를 설정합니다.
- cut : KDE 곡선을 얼마나 멀리 확장할지 결정합니다. 커널의 지원 범위 밖에서 값을 계산하는 데 사용되는 것보다 더 넓게 KDE를 그립니다.
- clip : KDE를 계산할 범위를 설정합니다.
- legend : True로 설정하면, 범례가 그려집니다.

import seaborn as sns
# Load the example tips dataset
tips = sns.load_dataset("tips")
# Draw a KDE plot
sns.kdeplot(tips["total_bill"], shade=True)
5.3.2 histplot()
histplot() 함수는 데이터의 분포를 나타내는 히스토그램을 그립니다. 이는 데이터의 빈도수를 시각화하는 데 매우 유용한 도구입니다. histplot() 함수의 주요 매개변수는 다음과 같습니다.
- data : 그래프를 그리는 데 사용할 pandas 데이터프레임, numpy 배열, 리스트 등입니다.
- x, y : x축 혹은 y축에 표시할 데이터의 이름입니다. 이는 문자열로 제공되어야 합니다. 둘 다 설정하면 2D 히스토그램을 그립니다.
- hue : 색상으로 구분할 카테고리 변수의 이름입니다.
- bins : 히스토그램의 빈의 수를 지정합니다. 정수, 시퀀스, 문자열 중 하나를 선택할 수 있습니다.
- binwidth : 히스토그램의 빈의 폭을 지정합니다.
- binrange : 히스토그램의 빈의 범위를 지정합니다.
- weights : 각 데이터에 가중치를 부여하려면 해당 가중치의 리스트를 지정합니다.
- stat : 히스토그램에서 보여줄 통계량을 지정합니다. count, frequency, density, probability 중 하나를 선택할 수 있습니다.
- kde : True로 설정하면, 커널 밀도 추정치(KDE)를 함께 그립니다.
- color : 히스토그램의 색상을 지정합니다.

import seaborn as sns
import matplotlib.pyplot as plt
# Load the example tips dataset
tips = sns.load_dataset("tips")
# Draw a histogram for total bill
sns.histplot(data=tips, x="total_bill", kde=True)
plt.show()
5.3.3 rugplot()
rugplot() 함수는 데이터 분포의 각 데이터 포인트를 표시하는 간단한 그래프를 생성합니다. 각 데이터 포인트는 축을 따라 작은 세로선으로 표시되며, 데이터의 분포를 쉽게 확인할 수 있게 돕습니다.
- a : 그래프를 그리는 데 사용할 데이터입니다. 일차원 배열이나 리스트를 입력합니다.
- height : 세로선의 높이를 지정합니다. 기본값은 0.05입니다.
- axis : 데이터를 표시할 축을 지정합니다. 'x' 또는 'y'를 선택할 수 있습니다.
- linewidth : 세로선의 너비를 지정합니다.
- alpha : 세로선의 투명도를 지정합니다. 0(완전 투명)에서 1(완전 불투명) 사이의 값을 선택합니다.
- color : 세로선의 색상을 지정합니다.

import seaborn as sns
# Load the example tips dataset
tips = sns.load_dataset("tips")
# Draw a rug plot
sns.rugplot(data=tips, a="total_bill", height=0.5, color="blue")
5.4 Matrix Plots
heatmap(), clustermap() 등의 함수를 통해 행렬 그래프를 그릴 수 있습니다. 이러한 그래프는 행렬 형태의 데이터를 시각화합니다.
5.4.1 heatmap()
heatmap() 함수는 데이터를 색상으로 표현한 행렬을 그리는 데 사용됩니다. 이 함수는 특히 상관계수 행렬과 같은 데이터를 시각화하는 데 유용합니다. heatmap() 함수의 주요 매개변수는 다음과 같습니다.
- data : 히트맵을 그리는 데 사용할 데이터셋. pandas DataFrame이나 2차원 배열을 전달합니다.
- vmin, vmax : 컬러맵의 최소 및 최대값을 설정합니다.
- cmap : 컬러맵을 설정합니다. 기본값은 None으로, 기본 컬러맵을 사용합니다.
- center : 컬러맵의 중심을 설정합니다. None으로 설정하면 컬러맵의 중심이 vmin과 vmax의 중간값이 됩니다.
- robust : True로 설정하면 컬러맵의 범위를 robust하게 설정하며, 이상치의 영향을 줄입니다.
- annot : True로 설정하면 각 셀에 값이 표시됩니다.
- fmt : 값 표시 형식을 설정합니다. annot=True일 때만 사용됩니다.
- linewidths : 셀 간 경계선의 너비를 설정합니다.
- linecolor : 셀 간 경계선의 색상을 설정합니다.
- cbar : 컬러바의 표시 여부를 설정합니다.
- cbar_kws : 컬러바의 속성을 설정하는 딕셔너리를 전달합니다.
- square : True로 설정하면 셀이 정사각형이 되며, 축의 비율이 무시됩니다.

import seaborn as sns
# Load the example flights dataset
flights = sns.load_dataset("flights")
# Pivot the dataframe
flights = flights.pivot("month", "year", "passengers")
# Draw a heatmap
sns.heatmap(data=flights, annot=True, fmt="d", cmap="YlGnBu")
5.4.2 clustermap()
clustermap() 함수는 히트맵에 계층적 클러스터링을 적용하여 그립니다. 이 함수는 특히, 변수 간의 패턴이나 구조를 발견하는 데 유용합니다. clustermap() 함수의 주요 매개변수는 다음과 같습니다.
- data : 클러스터맵을 그리는 데 사용할 데이터셋. pandas DataFrame을 전달합니다.
- pivot_kws : 데이터를 피벗하는 방법을 지정하는 딕셔너리입니다.
- method : 클러스터링 방법을 지정합니다. 기본값은 'single'입니다.
- metric : 거리 계산 방법을 지정합니다. 기본값은 'euclidean'입니다.
- z_score : 데이터를 표준화하는 방법을 지정합니다.
- standard_scale : 데이터를 표준 스케일로 변환하는 방법을 지정합니다.
- figsize : 그림의 크기를 지정합니다. (너비, 높이) 형태의 튜플을 전달합니다.
- cbar_kws : 컬러바의 속성을 설정하는 딕셔너리를 전달합니다.
- row_cluster, col_cluster : 행과 열의 클러스터링을 수행할지 여부를 지정합니다. 기본값은 True입니다.
- row_linkage, col_linkage : 행과 열에 대한 클러스터링 방법을 지정합니다.

import seaborn as sns
# Load the example flights dataset
flights = sns.load_dataset("flights")
# Pivot the dataframe
flights = flights.pivot("month", "year", "passengers")
# Draw a clustermap
sns.clustermap(data=flights, cmap="YlGnBu", standard_scale=1)
5.5 Regression Plots
lmplot(), regplot() 등의 함수를 통해 회귀 그래프를 그릴 수 있습니다. 이러한 그래프는 두 변수 사이의 선형 관계를 시각화합니다.
5.5.1 lmplot()
lmplot() 함수는 두 변수 간의 선형 관계를 시각화하는 데 사용되며, 이를 위해 선형 회귀 모델의 결과를 그래프로 나타냅니다. lmplot() 함수의 주요 매개변수는 다음과 같습니다.
- x, y : 데이터에서 사용할 변수의 이름입니다.
- data : 사용할 데이터 프레임입니다.
- hue : 색상을 기준으로 구분할 카테고리 변수의 이름입니다.
- col, row : 서브플롯을 생성하여 분리할 카테고리 변수의 이름입니다.
- palette : 색상 팔레트를 지정합니다.
- markers : 각 데이터 포인트에 대한 마커 모양을 지정합니다.
- scatter_kws, line_kws : 각각 산점도와 회귀선에 대한 추가적인 키워드 인자를 전달하는 딕셔너리입니다.
- ci : 회귀선 주위에 그릴 신뢰 구간의 크기를 지정합니다. None을 설정하면 신뢰 구간이 그려지지 않습니다.
- fit_reg : False를 설정하면 회귀선이 그려지지 않습니다.
- logistic, lowess, robust, logx : 회귀선을 적합시키는 방법을 지정합니다. 기본적으로 선형 회귀 모델을 사용합니다.

import seaborn as sns
# Load the example tips dataset
tips = sns.load_dataset("tips")
# Draw a lmplot
sns.lmplot(x="total_bill", y="tip", data=tips, hue="time", markers=["o", "v"])
5.5.2 regplot()
regplot() 함수는 두 변수 간의 선형 관계를 시각화하는데 사용됩니다. 이를 위해 선형 회귀 모델의 결과를 그래프로 나타냅니다. regplot() 함수의 주요 매개변수는 다음과 같습니다.
- x, y : 데이터에서 사용할 변수의 이름입니다.
- data : 사용할 데이터 프레임입니다.
- color : 플롯의 색상을 지정합니다.
- marker : 각 데이터 포인트에 대한 마커 모양을 지정합니다.
- scatter_kws, line_kws : 각각 산점도와 회귀선에 대한 추가적인 키워드 인자를 전달하는 딕셔너리입니다.
- ci : 회귀선 주위에 그릴 신뢰 구간의 크기를 지정합니다. None을 설정하면 신뢰 구간이 그려지지 않습니다.
- fit_reg : False를 설정하면 회귀선이 그려지지 않습니다.
- logistic, lowess, robust, logx : 회귀선을 적합시키는 방법을 지정합니다. 기본적으로 선형 회귀 모델을 사용합니다.

import seaborn as sns
# Load the example tips dataset
tips = sns.load_dataset("tips")
# Draw a regplot
sns.regplot(x="total_bill", y="tip", data=tips, color="green", marker="+")
5.6 Multi-plot Grids
pairplot(), FacetGrid() 등의 함수를 통해 복수의 서브 플롯을 한 번에 그릴 수 있습니다.
5.6.1 pairplot()
pairplot() 함수는 데이터 프레임에서 쌍으로 이루어진 관계를 그리는 데 사용됩니다. 즉, 데이터셋의 모든 가능한 쌍 조합에 대한 산점도를 그리고, 주 대각선에는 해당 데이터의 히스토그램 또는 KDE 플롯을 그립니다. pairplot() 함수의 주요 매개변수는 다음과 같습니다.
- data : 사용할 데이터 프레임입니다.
- hue : 색상을 기준으로 구분할 카테고리 변수의 이름입니다.
- palette : 색상 팔레트를 지정합니다.
- vars : 사용할 변수의 리스트를 지정합니다. 지정하지 않으면 데이터 프레임의 모든 수치형 변수가 사용됩니다.
- kind : 그릴 플롯의 종류를 지정합니다. scatter와 reg 중 선택할 수 있습니다.
- diag_kind : 주 대각선에 그릴 플롯의 종류를 지정합니다. hist와 kde 중 선택할 수 있습니다.
- markers : 각 그룹에 대한 마커 모양을 지정하는 문자열 리스트입니다.
- height : 각 플롯의 크기를 지정합니다.
- plot_kws, diag_kws : 각각 산점도와 대각선 플롯에 대한 추가적인 키워드 인자를 전달하는 딕셔너리입니다.

import seaborn as sns
# Load the example iris dataset
iris = sns.load_dataset("iris")
# Draw a pairplot
sns.pairplot(data=iris, hue="species", markers=["o", "s", "D"])
5.6.2 FacetGrid()
FacetGrid()는 여러 서브플롯을 생성하고 각각에 데이터를 시각화할 수 있습니다. 이는 데이터의 여러 측면을 동시에 비교하거나 표현하고자 할 때 유용합니다. FacetGrid() 함수의 주요 매개변수는 다음과 같습니다.
- data : 사용할 데이터 프레임입니다.
- row, col : 행과 열에 해당하는 변수의 이름입니다. 이 변수들을 기준으로 그리드를 생성합니다.
- hue : 색상을 기준으로 구분할 카테고리 변수의 이름입니다.
- palette : 색상 팔레트를 지정합니다.
- row_order, col_order, hue_order : 각 변수의 레벨을 정렬하는 데 사용할 리스트를 지정합니다.
- height, aspect : 각 플롯의 크기와 가로세로 비율을 지정합니다.

아래 코드는 FacetGrid() 함수를 사용하여 플롯을 생성하고, map() 메서드를 사용하여 각 서브플롯에 데이터를 시각화하는 예제입니다. time'에 따라 열을 구분하고, 'smoker'에 따라 색상을 구분하는 그리드를 생성합니다. 각 서브플롯에는 'total_bill'과 'tip' 사이의 산점도가 그려집니다.
import seaborn as sns
# Load the example tips dataset
tips = sns.load_dataset("tips")
# Create a FacetGrid
g = sns.FacetGrid(tips, col="time", hue="smoker")
# Map a scatter plot to each facet
g.map(sns.scatterplot, "total_bill", "tip")
# Add a legend
g.add_legend()
map() 메서드는 먼저 그리드에 설정된 각 조합에 대해 데이터를 선택하고, 해당 데이터와 인수로 제공된 다른 인수와 함께 함수를 호출합니다. FacetGrid.map() 메서드의 주요 매개변수는 다음과 같습니다.
- func : 각 서브플롯에 적용할 함수입니다. 대부분의 경우, 이것은 Matplotlib이나 Seaborn에서 제공하는 플로팅 함수일 것입니다.
- *args : 함수에 전달할 추가 인수입니다. 여기에는 데이터 프레임의 변수 이름을 전달할 수 있습니다.
5.7 Joint Plots
5.7.1 jointplot()
jointplot() 함수는 두 변수 사이의 이변량(또는 조인트) 관계와 각 변수의 일변량(또는 마진) 분포를 동시에 표시하는 그래프를 생성합니다. 기본적으로 jointplot()는 중앙에 산점도를 표시하고, 상단과 오른쪽 축에는 각 변수의 히스토그램을 표시합니다. jointplot() 함수의 주요 매개변수는 다음과 같습니다.
- x, y : 데이터셋에서 비교할 두 개의 변수 이름입니다.
- data : 사용할 데이터 프레임입니다.
- kind : 그리려는 플롯의 종류를 지정합니다. "scatter" (기본값), "kde", "hist", "hex", "reg", "resid" 등을 선택할 수 있습니다.
- color : 모든 요소의 색상을 지정합니다.
- height : 그래프의 크기를 지정합니다.
- ratio : 중앙 그래프와 마진 그래프의 높이 비율을 지정합니다.
- space : 중앙 그래프와 마진 그래프 사이의 공간을 지정합니다.

import seaborn as sns
# Load the example tips dataset
tips = sns.load_dataset("tips")
# Create a joint plot of total bill and tip
sns.jointplot(data=tips, x="total_bill", y="tip", kind="hex", color="g")