

☞ 문서의 내용은 가장 하단 참고문헌 및 사이트를 참고하여 필자가 보기 쉽도록 정리한 내용입니다.
☞ 틀린 내용 및 저작권 관련 문의가 있는 경우 문의하시면 수정 및 삭제 조치하겠습니다.
용어 정리
Part
추정하고자 하는 사람의 관절 (head, neck , ankle 등)
Confidence map
part가 해당하는 위치에 있을 확률을 heatmap으로 표현했다. 붉은색일 수록 해당 위치에 part가 있을 확률이 높다고 예측하는 것이다. 입력 이미지 크기와 동일 크기의 map으로 각 Part마다 1장씩 할당된다.

Image patch
전체 이미지 중 특정 location z 픽셀 주위의 일정 영역(local image)

Level( l : 1~ l)
image patch 크기를 나타내는 인덱스
$x_z$
픽셀 위치 z에서 Image patch 의 특성을 나타내는 hand-crafted feature (feature function은 고정), Histogram of Gradients(HOG) features, Lab color features, 및 gradien magnitude 등

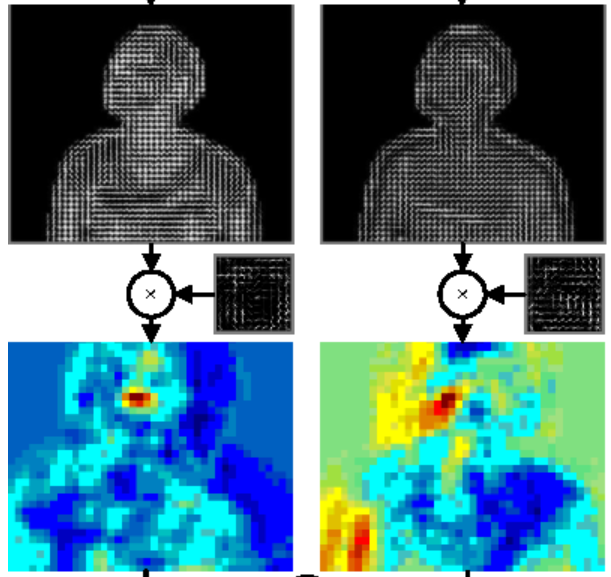
이미지 출처 : Human Pose Estimation from Monocular Images : A comprehensive Survey, Face pose estimation with combined 2D and 3D Hog features
$g_t$
Confidence map을 출력하는 multi-class classifier
⍦
feature function을 의미한다. confdence map은 이 feature function에 input으로 들어가고 feature function을 거쳐서 feature context라는 output이 나온다. 여기서 이 feature context와 image feature가 같이 다음 예측기인 g로 들어가게 되는데 이를 논문에서는 아래 식(1)처럼 표현했다.
$g^{p}$
여기서 p는 part를 말한다. 따라서 $g^{p}$는 각 part를 담당하는 하나의 분류기이다. 그러나 여기서 g를 여러개 사용하지 않고 하나를 사용한 이유는 여러 개의 part를 예측하는 single muticlass predictor로써 g라고 표현하기 때문이다.
$^{l}gt$
Single-multi-class predictor , predictor라고 불린다. t는 stage의 번호를 말하고 l은 level의 정도를 말한다.
$b_t$
b는 confidence map을 의미하고 t는 stage의 번호를 말한다. b는 예측기의 output이다. 만약 $b_t$에 t가 1이라면 1번째 Stage의 예측기를 거치고 나온 confidence map을 의미한다.

본 논문에서 합친다는 표현은 위의 그림과 같은 수식을 사용한다고 명시했다.
hand-crafted feature : 머신러닝에서는 사람이 직접 특징을 정해주는데 그 특징을 hand-crafted feature이라 한다.
요약

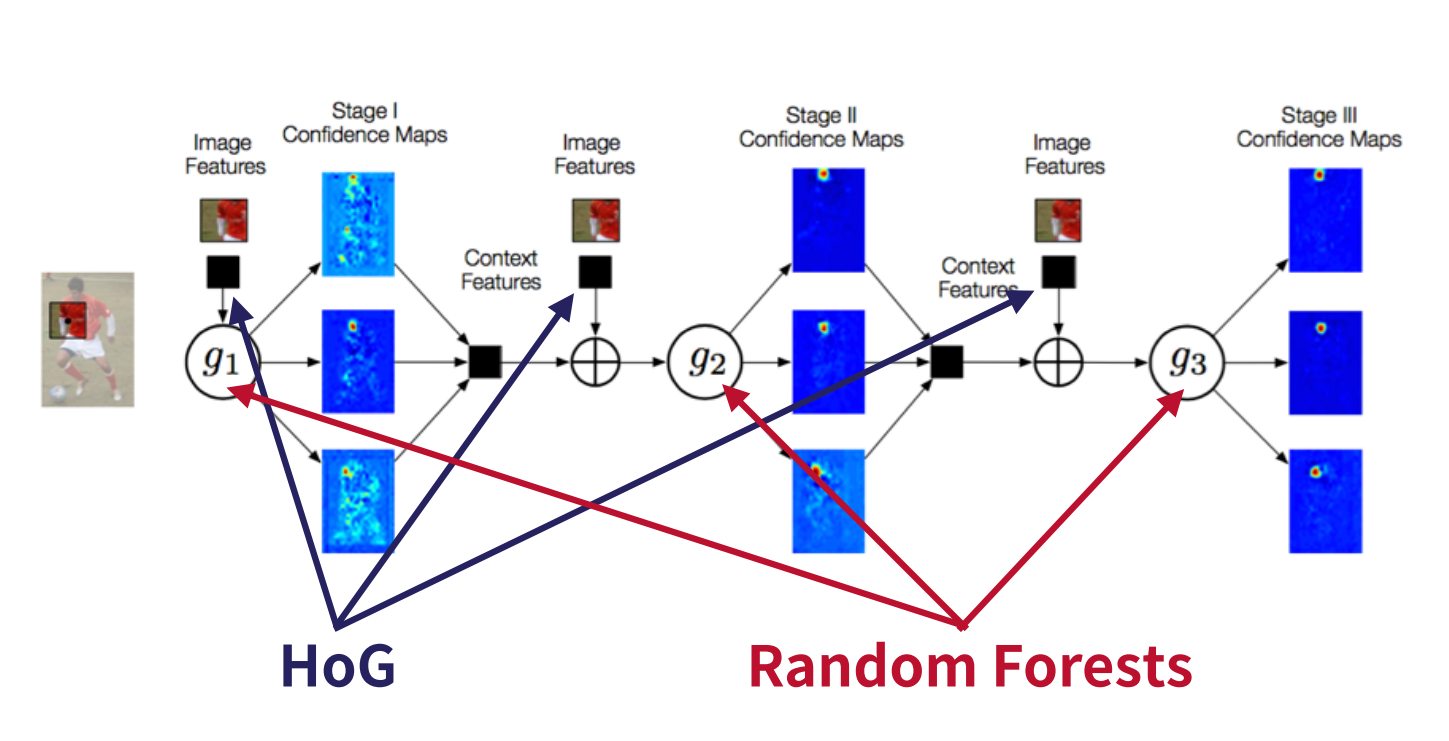
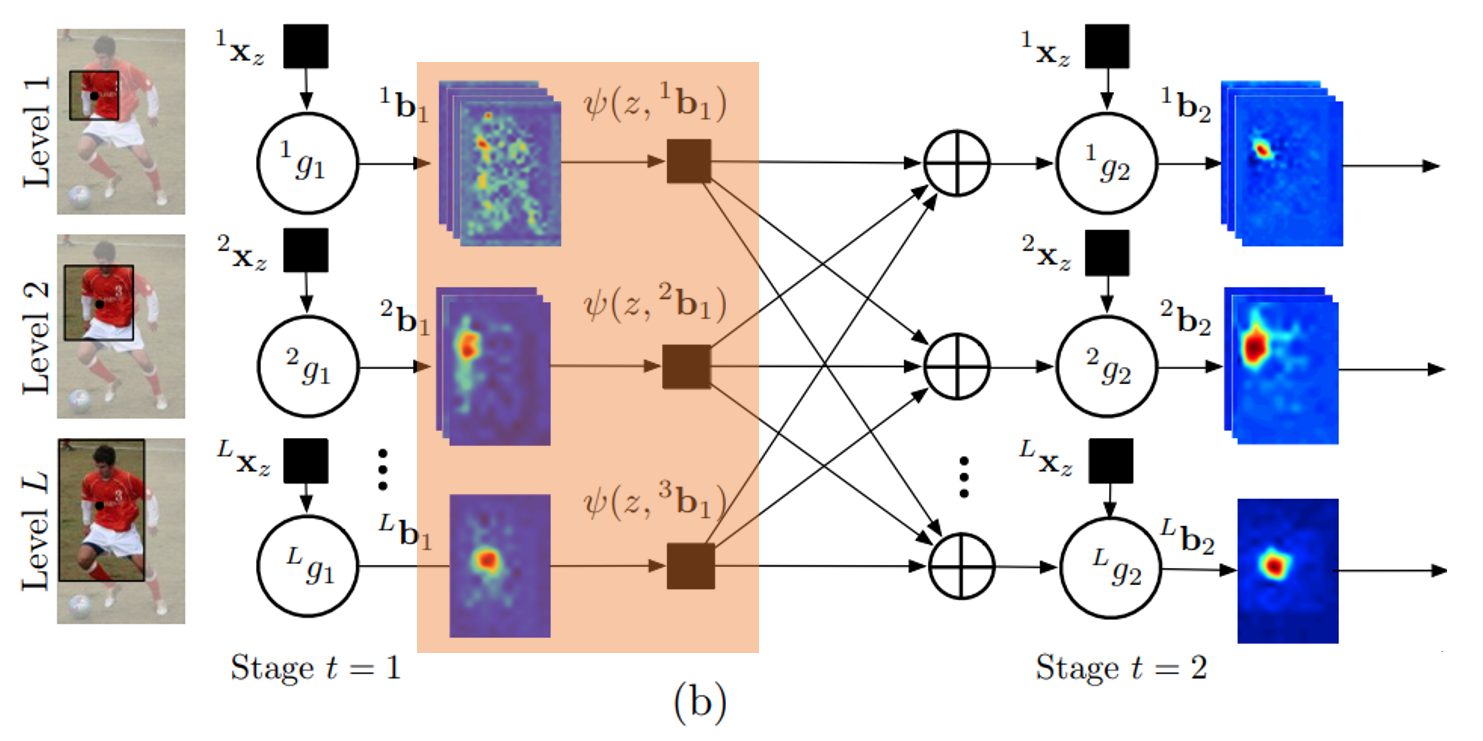
그림 (a)는 image patch로 부터 feature $x_z$를 생성하고, multi-class 분류기 $g_t$를 통해 각 Part의 confidence map $b_t$를 출력하는 과정을 보여준다. 그림 (b)는 각 level 마다 서로 다른 multi-class 분류기를 배치하고, 이러한 stage를 복수로 순차 연결하여 출력하는 과정을 보여준다.
Multi-class 분류기의 출력인 confidence map의 개수는 각 level 마다 다르다. 레벨이 낮으면(image patch size가 작으면) confidence map 개수가 많으며, 레벨이 높으면 (image patch size가 크면) confidence map개수가 작다. 예를 들어, level 1은 출력 confidence map 개수를 P개로 설정하고 (전체 파트 개수), level L은 출력 confidence map 개수를 1로 설정할 수 있다. 이 경우, 레벨 1에서는 part 1개당 confidence map 1개를 할당하여 'local context'를 분석하고, 레벨 L에서는 전체 part P에 대해 confidence map 1개를 할당하여 'global context'를 분석하는 구조로 설계할 수 있다.
이렇게 분석한 local and global context는 다음 stage로 전달되어 stage가 진행될 수록 보다 정교한 confidence map을 추정하게 된다. 이 과정에서, 각 level은 다른 level로 부터의 정보를 함께 입력받음으로써, local an global context를 모두 이용하여 현재 레벨의 confidence map을 생성한다.



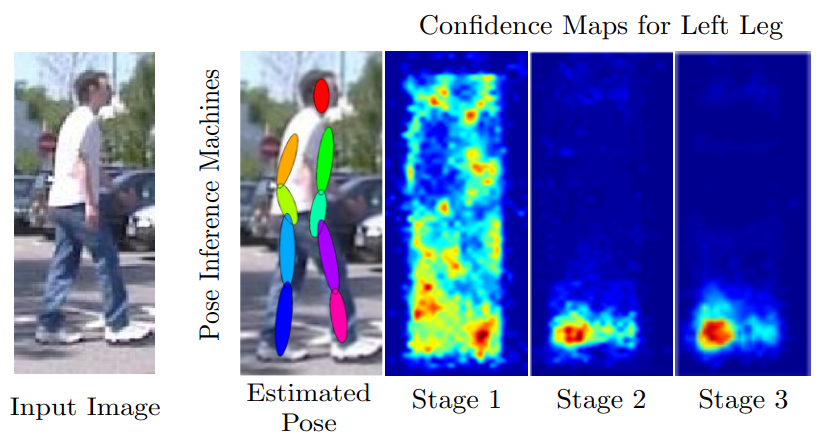
3 Pose Inference Machines
3.1 Background
본 논문에서는 Pose estimation을 structured prediction(구조 예측) 문제로 본다. 즉, 이미지 $Y_p ∈ Z ⊂ R^{2}$ 에서 part의 픽셀 위치를 찾는다. 여기서 Z는 이미지의 모든 (u, v)위치 집합이다. 우리의 목표는 모든 Part p에 대해 구조화 된 출력 Y=(Y1,....Yp)를 예측하는 것이다. inference machine는 각 Part의 위치를 예측하도록 훈련된 multi-class classifiers gt (·)로 구성된다. 각 단계 t ∈ {1. . . T}에서 분류기는 이미지 데이터 $x_z ∈ R^{d}$의특징과 각 $Y_p$ 주변의 이웃에 있는 이전 분류자의 상황 정보를 기반으로 각 부분 $Y_p = z, ∀z ∈ Z$에 위치를 할당하기 위한 신뢰도를 예측한다. 각 단계에서 계산된 신뢰도는 변수에 대해 점점 더 정제된 추정치를 제공한다. 시퀀스의 각 단계 t에 대해 할당 $Y_p = z$에 대한 신뢰도가 계산되고 아래 식과 같이 표시된다.
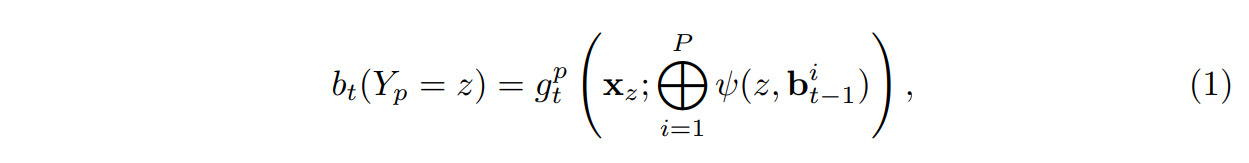
여기서 아래 식은 p번째 부분의 모든 위치 z에서 평가된 이전 분류기의 신뢰 집합이다. feature function $ψ : Z × R^{|Z|}$ -> $R^{d_c}$는 분류기의 이전 신뢰도에서 contextual feature을 계산한다.
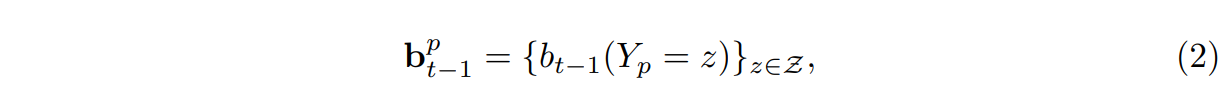
structured prediction : 일반적으로 구조화된 예측은 결과를 산출하기 위해 적용할 수 있는 라벨이 있는 감독된 기계 학습 프로그램을 이용한다. 구조화된 예측에 대해 말하는 가장 간단하고 쉬운 방법 중 하나는 분류 과제를 해결하기 위해 훈련 문제를 사용한다는 것이다.
Incorporating a Hierarchy
각 level 에는 서로 다른 유형의 Part 부분가 있다. 첫 번째 Level은 팔,다리 등과 같이 복합적인 Part로 구성되는 반면에 가장 마지막 Level에서는 전신을 캡처하는 단일 이미지로 구성된다. 각 Level에서의 Part는 $P_1, ..., P_L$로 표현된다.
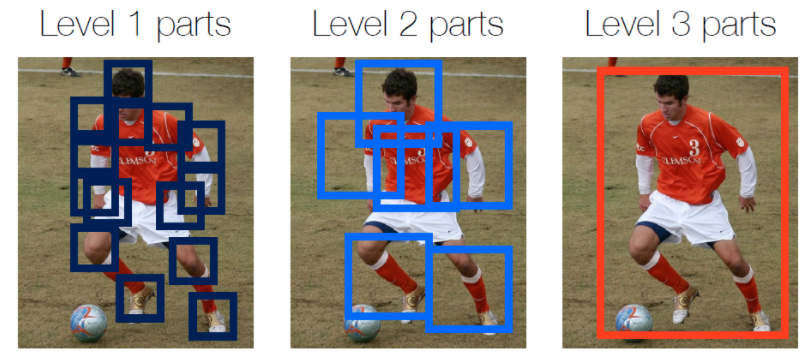
level에서 각 part에 대해 개별 예측 변수를 훈련할 수 있지만, 실제로는 계층의 특정 level에서 주어진 feature vector로 부터 모든 part에 대한 confidense set을 생성하는 single multi-class predictor를 사용한다. 간단하게 하기 위해 위첨자를 삭제하고 multi-class classifier를 $^{l}g_t(·)$로 표시한다.
각 부분의 위치에 대한 신뢰도의 초기 추정치를 얻기 위해 첫 번째 단계 (t =1)에서 predictor $^{l}g_1(·)$은 이미지 위치 z에서 추출된 patch에서 계산된 입력 특징으로, patch를 Stage의 l번째에 있는 parth들에 대해 $P_l$ part 클래스 또는 background 클래스 중 하나로 분류한다.
이미지 z위치를 중심으로 하는 계층 구조의 l번째 level에 대한 이미지 parch의 feature vector 인 $x_z^{l}$로 표시합니다. 따라서 첫 번째 단계 t = 1에서 계층 구조의 l 번째 level에 대한 분류자는 다음과 같은 신뢰값을 생성합니다. (첫 번째 분류기는 image feature만을 input으로 하고 있기 때문에 수식은 아래와 같다.)
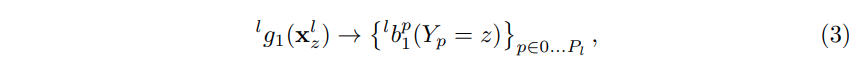
여기서 $^{l}b_1^{p}(Y_p = z)$는 이미지 위치 z의 첫 번째 단계에서 계층 구조의 l번째 level에 있는 p번째 부분을 할당하기 위해 분류기 $^{l}g_1$에 의해 예측 된 점수이다. 식2와 유사하게, 모든 part 위치에서 평가된 level의 모든 신뢰도 $z = (u,v)^{T}$ 이미지를 $^{l}b_t^{p} ∈ R^{w × h}$로 나타내며, 여기서 w와 h는 각각 영상의 폭과 높이를 나타낸다. 즉 아래식과 같다.

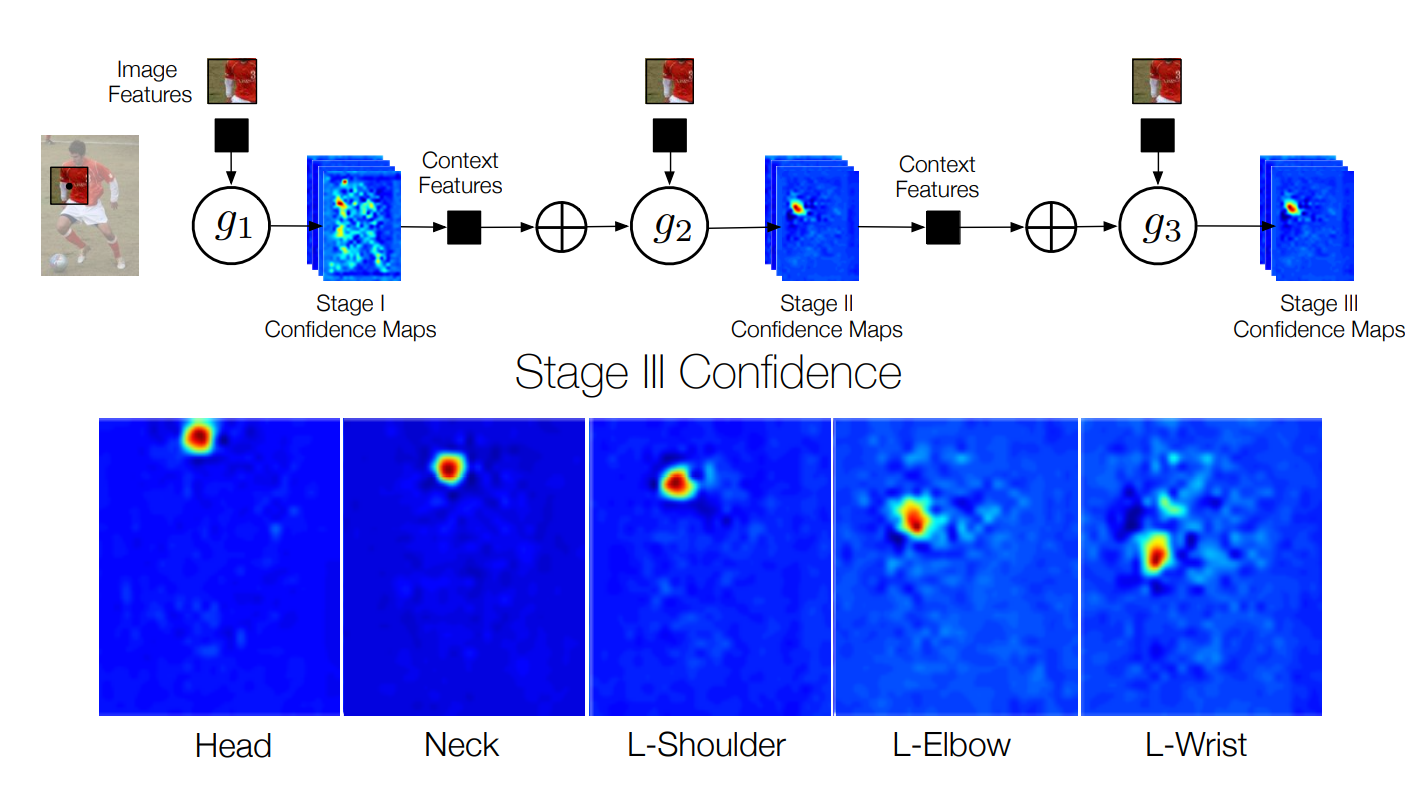
편의상, 우리는 $^{l}b_t^{p} ∈ R^{w × h × p_l}$로 라벨링되는 모든 part에 대한 confidences map의수집을나타낸다.(그림2(a) 참조) 이후 단계에서 각 변수에 대한 신뢰는 식 1과 유사하게 계산된다. 계층 구조의 scales/levels에 걸쳐 context를 활용하기 위해 예측은 아래와 같이 정의된다.

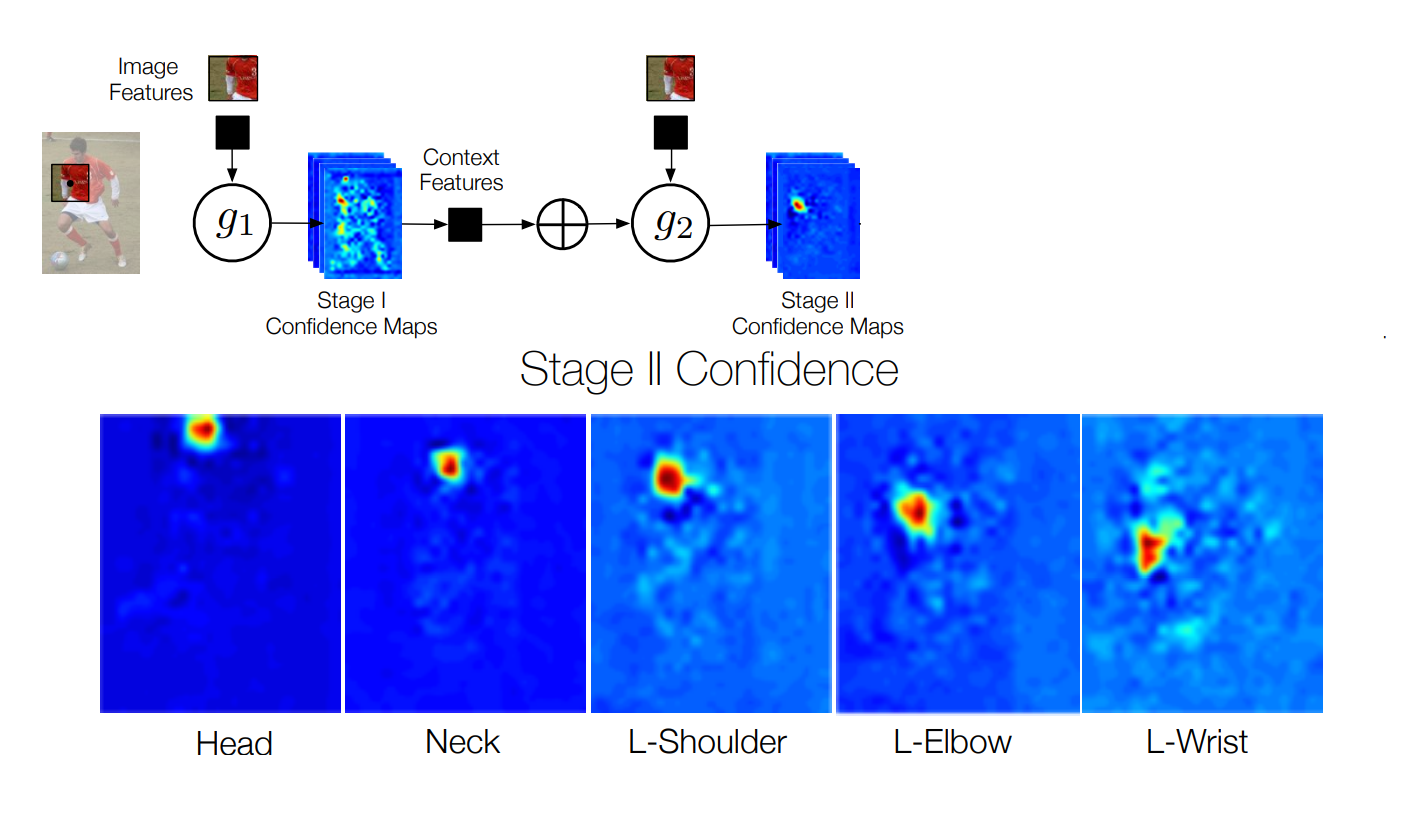
아래 그림 에서 볼 수 있듯이, 두 번째 단계에서 분류기 $^{l}g_2$는 이전 단계의 각 part에 대해 feature function ψ를 통해 신뢰도에서 계산 된 feature$x_l^{z}$ 과 $^{l}x_z$를 입력으로 취합니다.
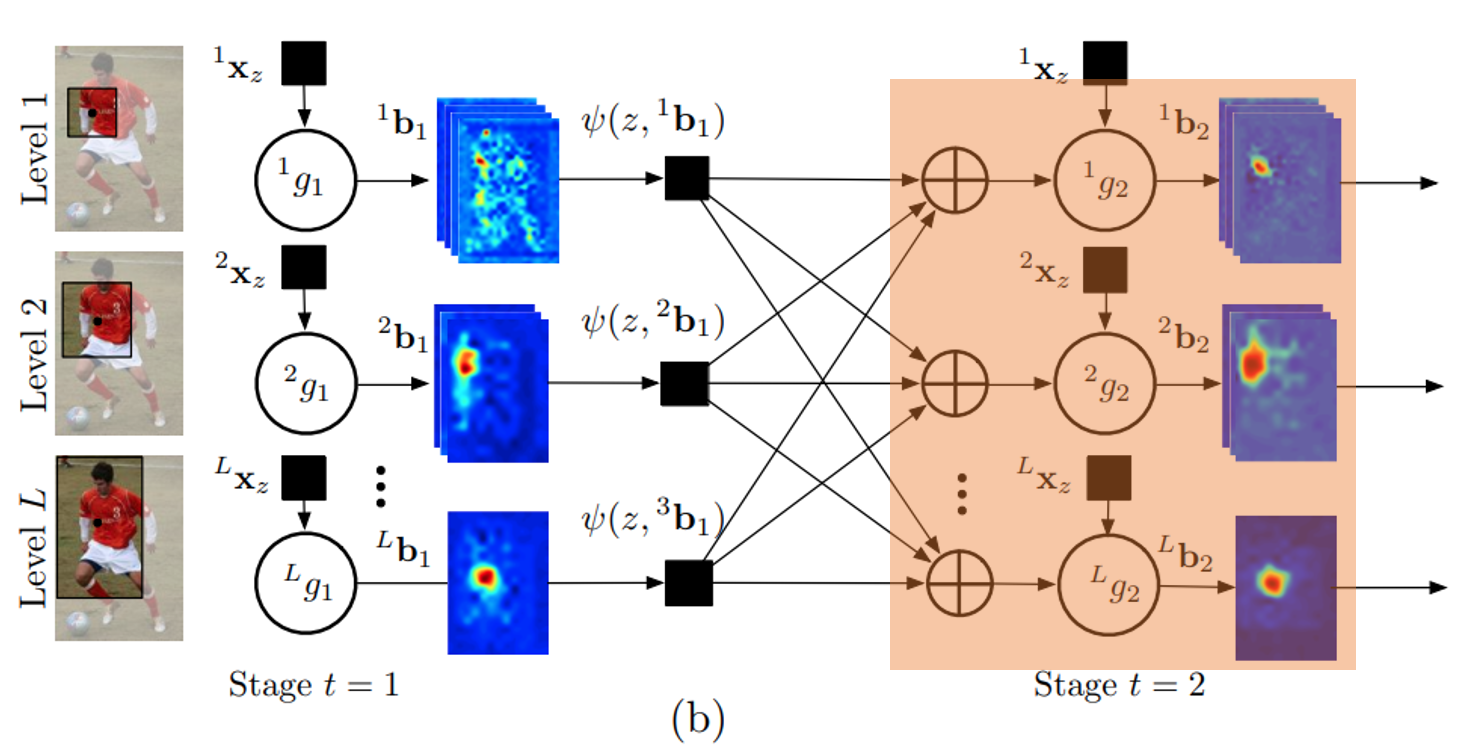
part에 대한 예측은 모든 part의 output과 계층의 모든 level $({^{l}b_t-1}_l∈1...L)$에서 계산된 feature을 사용한다. inference machine architecture는 (그래픽 모델에서 잠재적 함수를 지정하는 것이 아니라) 이전 단계의 output에 feature을 제공하고 분류기가 가장 예측 가능한 feature을 선택하여 상황 정보를 자유롭게 결합 할 수 있도록 함으로써 변수들 간의 잠재적으로 복잡한 상호작용을 학습할 수 있게 한다.
context features
본 논문에서는 local하게 estimation하는 것이 아닌 context하게 estimation하는 것이다. 때문에 context feature를 찾는 과정이 중요하다. context feature는 2가지의 context function으로 context feature를 구하고 합쳐 다음 예측기의 input으로 넣는 방식으로 신경망을 학습한다.
인접 part에 대한 각 part의 신뢰도 사이의 공간적 상관 관계를 알기 위해 $ψ_1$와 $ψ_2$로 표시된 context feature map과 함께 두 가지 유형을 설명한다.
위치 z의 feature map $ψ_1$는 계층 level l에서 각 part의 위치에 대한 confidence map을 입력하는 것으로 간주되고, confidece map에서 위치 z에서 추출된 미리 정의된 너비의 벡터화된 patch인 feature를 생성한다. (그림 3a 참조).
계층 level l의 part beliefs 에서 $C_1(z, ^{l}b_t-1^{p})$을 기준으로 위치 z에서 추출되고 벡터화된 patch set을 나타낸다. 따라서 feature map $ψ_1$은 아래의 식과 같이 주어진다.


즉 context feature는 계층 구조의 각 level에 있는 모든 part의 confidence map에서 추출된 z 좌표의 점수를 연결한 것이다. context patch는 factor graph에서 메시지로 전달되는 위치 z 주변의 주변 정보를 인코딩한다. 모든 부분의 contexst를 인코딩 하기 때문에 이는 완전한 그래프 구조를 가진 그래픽 모델을 갖는 것과 유사하며 최적화 하기 어렵다.
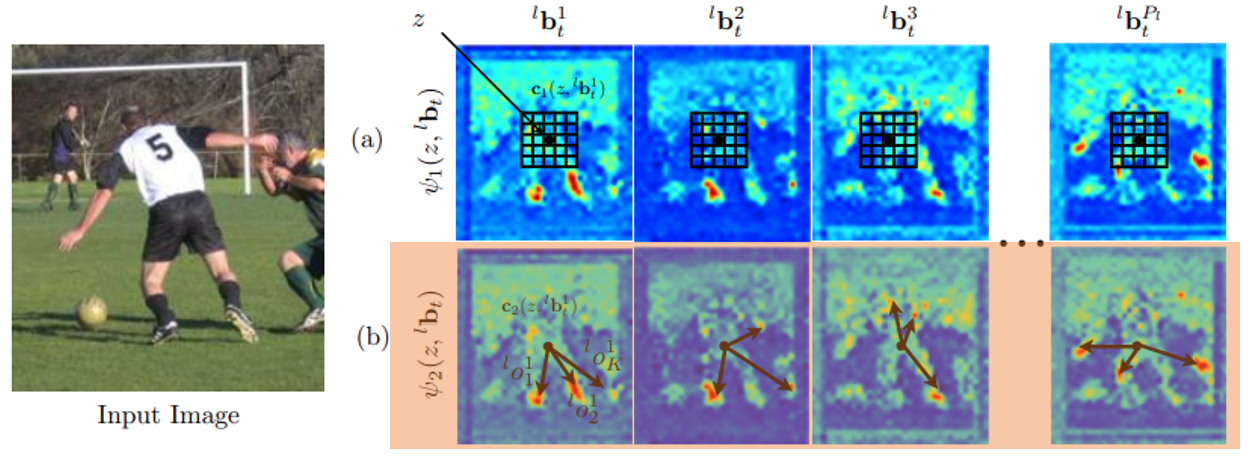
불균일한 relative offests에 있을 수 있는 part들 사이의 long-range interactions을 인코딩하기 위해 두 번째 유형의 feature인 ψ2를 계산한다. 첫 번째로 l번째 계층 level의 모든 part에 대해 각 $P_l$ confidence map $^{l}b_t-1^{P}$에서 K peaks의 정렬된 목록을 얻기 위해 non-maxima suppresion을 수행한다.
그런 다음 $^{l}o_p^{k} ∈ R^{+} × R$ 로 표시된 p 번째 부분과 l 번째 수준의 confidecne map에서 z 위치에서 각 k번째 peak까지의 극좌표 오프셋 벡터를 계산한다.(그림 3b 참조). 한 part의 confidence map에서 계산된 context offset feature set은 다음과 같이 정의 된다.
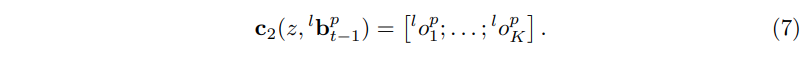
그런 다음, context offset feaure map은 계층 구조의 각 part에 대한 context offest feautre $C_2(z, ^{l}b_t-1^{p})$을 연결함으로써 형성된다.
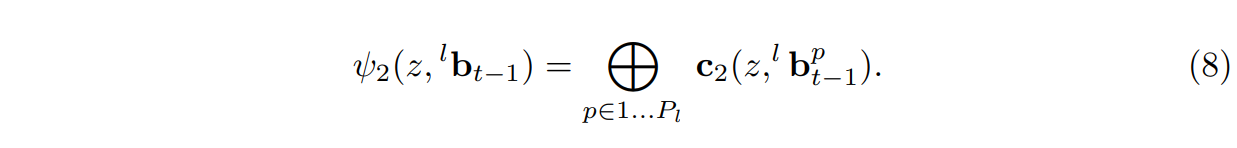
context patch features(ψ1)은 인접 part의 신뢰도와 관련된 대략적인 정보를 캡처한다. offset feature(ψ2)은정확한 상대위치 정보를 캡처한다. 최종 context feature ψ는 다음 두개를 연결하여 계산된다 $ψ (·) = [ψ1 (·); ψ2 (·)].$
Stacking
인공신경망을 통한 학습의 중점은 예측기인 g를 학습시키는 것이다. 그런데 g에 계속 똑같은 image feature를 다시 학습하는 과정이기 때문에 overfitting될 확률이 높다. 때문에 cross-validation과 비슷한 stacking을 적용했다고 한다.

참고자료
[논문 정리] Pose Machines: Articulated Pose Estimation via Inference Machines
이전까지는 graphical models에 근간하여 사람의 pose estimator를 만들었으나 카네기멜론에서 제안하는 새로운 방식은 이전의 방식에서 벗어나 새로운 method를 제안한다. Introduction 사람 관절 추정의 어
powerofsummary.tistory.com
Pose machines: Articulated pose estimation via inference machines (ECCV 2014)
논문 제목: Pose machines: Articulated pose estimation via inference machines 연구 기관: Carnegie Mellon University 본 연구는 multi-stage cla...
kaiertech.blogspot.com
Pose Machines: Articulated Pose Estimation via Inference Machines
State-of-the-art approaches for articulated human pose estimation are rooted in parts-based graphical models. These models are often restricted to tree-structured representations and simple...
link.springer.com