

☞ 문서의 내용은 가장 하단 참고문헌 및 사이트를 참고하여 필자가 보기 쉽도록 정리한 내용입니다.
☞ 틀린 내용 및 저작권 관련 문의가 있는 경우 문의하시면 수정 및 삭제 조치하겠습니다.
R-CNN은 Image classification을 수행하는 CNN과 localization을 위한 regional proposal알고리즘이 결합된 regions-with-cnn의 약자로 이전의 최고 성능의 네트워크의 mAP보다 30% 높은 53.3%를 달성한 논문이다. object detection 분야에 새로운 방향성을 제시한 네트워크이다. R-CNN은 순차적으로 진행하는 대표적인 two-stage-detector로 딥러닝을 적용한 최초의 Object Detection모델이다. R-CNN은 두 가지 중요한 아이디어를 결합했다. 첫 번째는 region proposals로 object의 위치를 알아내고, 이를 CNN에 입력하여 class를 분류한다. 두 번째는 larger data set으로 학습된 pre-trained CNN을 fine tuning한다.
R-CNN Algorithm
R-CNN은 아래와 같은 프로세스로 작동한다.
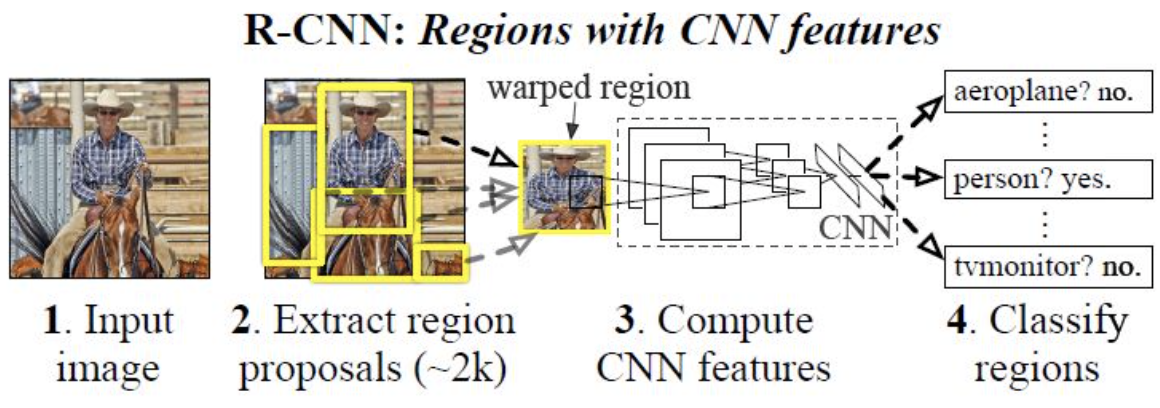
Image를 입력받는다. selective search 알고리즘에 의해 regional proposal output약 2000개를 추출한다.(이는 기존의 sliding window 방식의 비효율성을 극복하기 위해 제안한 것이다.) 추출한 regional proposal output을 모두 동일한 input size(227x227)로 만들어주기 위해 warp한다. 이 때 box의 비율 등은 고려하지 않는다. 동일 input size로 만들어 주는 이유는 마지막 fc layer에서의 input size가 고정이므로 output size가 동일해야 한다.
*Selective search방식은 색상, 질감, 크기를 이용해 non-object-based segmentation을 수행 한다. 이 작업을 통해 많은 small segmented areas를 얻을 수 있다. 그리고 bottom-up방식으로 small segmented areas들을 합쳐서 더 큰 segmented arear들을 만든다. 이 작업을 반복하여 2000개의 region proposal을 생성한다.
*Sliding window방식은 이미지에서 물체를 찾기 위해 window의 (크기, 비율)을 임의의로 마구 바꿔가면서 모든 영역에 대해서 탐색하는 것으로 모든 영역을 탐색하기 때문에 속도가 느리다.

Warp 작업을 통해 region proposal 모두 227x227크기로 resize되면 2000(region proposal) x 4096(feature vector의 차원)크기의 feature vector를 추출하기 위해 CNN모델에 넣는다. 여기서 CNN 모델은 5개의 convolutional layer와 2개의 FC layer를 가진 AlexNet형태이다. 여기서 soft-max layer가 아니라 FC layer가 있는 이유는 R-CNN은 SVM을 사용하였기 때문이다. 논문의 저자는 객체 탐지시 특정 도메인에 맞는 class를 예측하기 위해서 ILSVRC 2012 데이터셋을 통해 pre-trained된 CNN모델을 fine tune하는 방식을 제안한다. Fine tune된 모델을 사용하면 도메인에 맞게 보다 적합한 Feature vector를 추출하는 것이 가능해진다.
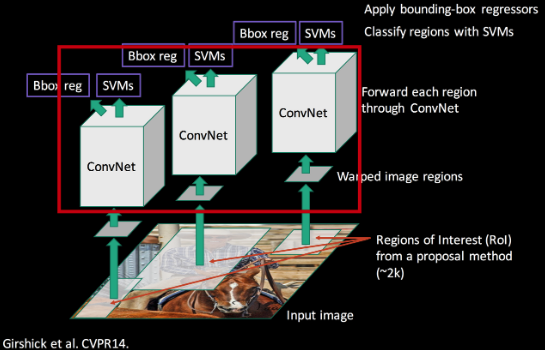
Fine tuning pre-trained AlexNet
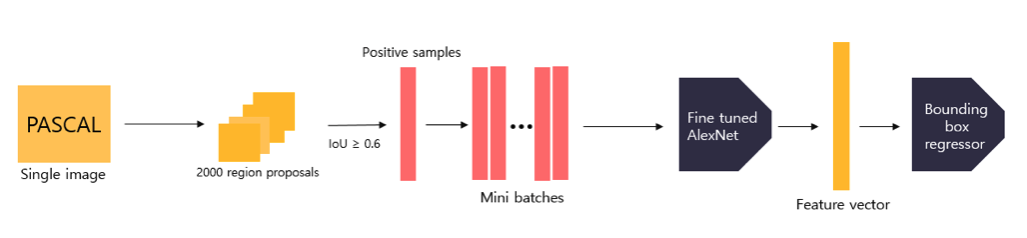
R-CNN모델이 추론 시 입력으로 들어온 region proposal은 객체를 포함할 수도 있으며, 배경을 포함하고 있을 수도 있다. 따라서 fine tune시 예측하려는 객체의 수가 N개라고 할 때 배경을 포함하여 (N+1)개의 class를 예측하도록 모델을 설계해야 하며 객체와 배경을 모두 포함한 학습 데이터를 구성해야한다. 이를 위해 PASCAL VOC 데이터셋에 Selective search 알고리즘을 적용하여 객체와 배경이 모두 포함된 후보 영역을 추출하여 학습 데이터로 사용한다. (Selective search 알고리즘은 R-CNN모델의 추론 시에도, AlexNet을 fine tune할 때도 사용하는 셈이다.)
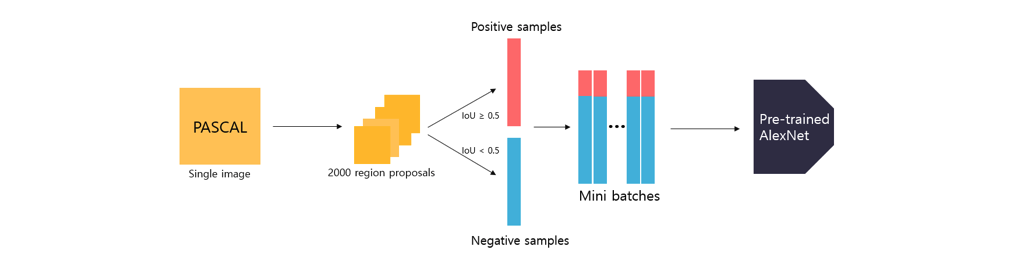
먼저 PASCAL VOC데이터셋에 Selective search 알고리즘을 적용하여 후보 영역을 추출하고, 후보 영역(=bounding box)과 ground truth box와의 IoU값을 구한다. IoU값이 0.5 이상인 경우 positive smaple(=객체)로 , 0.5미만인 경우에는 negative sample(=배경)로 저장한다. 그리고 positive sample = 32, negative sample = 96로 mini batch(=128)로 구성하여 pre-trained된 AlexNet에 입력하여 학습을 진행한다. 위의 과정을 통해 fine tune된 AlexNet을 사용하여 R-CNN 모델은 추론 시, feature vector를 추출한다.
Input : 227x227 sized 2000 region proposals
Process : Feature extraction by fine tuned AlexNet
output : 2000x4096 sized feature vector
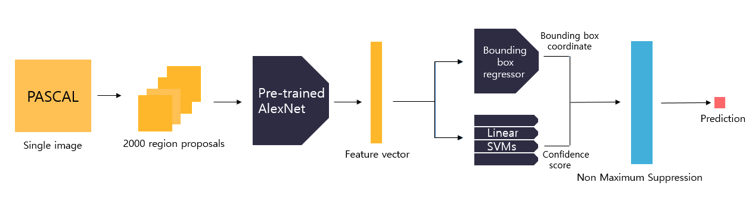
linear SVM모델은 2000x4096 feature vector를 입력 받아 class를 예측하고 confidence score를 반환한다. 이 때 linear svm모델은 특정 class에 해당하는지 여부만을 판단하는 이진 분류기(binart classifier)이다. 따라서 N개의 class를 예측한다고 할 때, 배경을 포함한 (N+1)개의 독립적인 linear svm모델을 학습시켜야 한다.
Classification by linear SVM
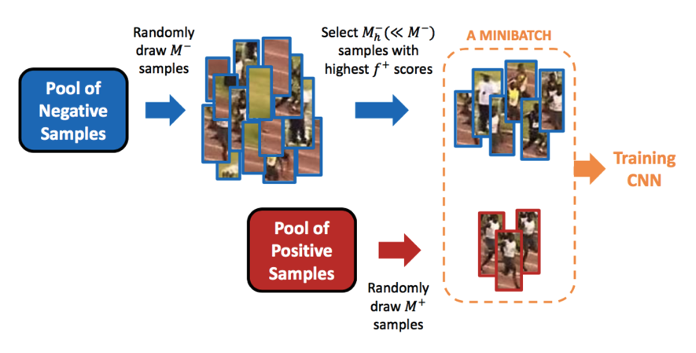
먼저 객체와 배경을 모두 학습하기 위해 PSCAL VOC 데이터셋에 selective search 알고리즘을 적용하여 region proposals를 추출한다. AlexNet 모델을 fine tune할 때와는 다르게 오직 Ground truth box만을 Positive sample로, IOU값이 0.3미만인 예측 Bounding box를 negative sample로 저장한다. IOU값이 0.3 이상인 bounding box는 무시한다. positive sample =32, negative smaple = 96이 되도록 mini batch(=128)을 구성한 뒤 fine tuned AlexNet에 입력하여 feature vector를 추출하고, 이를 linear SVM에 입력하여 학습시킨다. 이 때 하나의 linear svm모델은 특정 class에 해당하는지 여부를 학습하기 때문에 output unit = 2이다. 학습이 한 차례 끝난 후 , hard negative mining 기법을 적용하여 재학습시킨다. 학습된 linear SVM에 2000x4096 크기의 feature vector를 입력하면 class와 confidence score를 반환합니다.
Input : 2000x4096 sized feature vector
Process : class prediction by linear SVM
output : 2000 classes and confidence scores
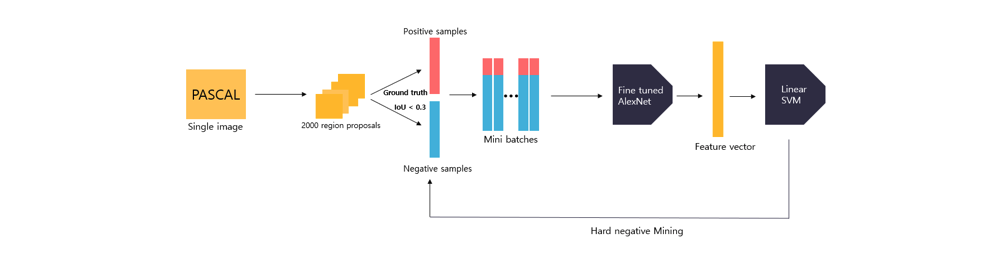
Hard Negative Mining
Hard negative mining은 모델이 예측에 실패하는 어려운 sample들을 모으는 기법으로, hard negative mining을 통해 수집된 데이터를 활용하여 모델을 보다 강건하게 학습시키는 것이 가능해진다. 모델은 주로 False positive라고 예측하는 오류를 주로 범한다. 이는 객체 탐지 시, 객체의 위치에 해당하는 positive sample보다 배경에 해당하는 negative sample이 훨씬 많은 클래스 불균형(class imbalance)으로 인해 발생한다. 이러한 문제를 해결하기 위해 모델이 잘못 판단한 false positive sample을 학습 과정에서 추가하여 재학습하면 모델은 보다 강건해지며, False Positive라고 판단하는 오류가 줄어든다.
Detailed localization by bounding box regressor
Selective search 알고리즘을 통해 얻은 객체의 위치는 다소 부정확할 수 있다. 이러한 문제를 해결하기 위해 bounding box의 좌표를 변환하여 객체의 위치를 세밀하게 조정해주는 bounding box regressor을 사용하여 성능을 올려준다.
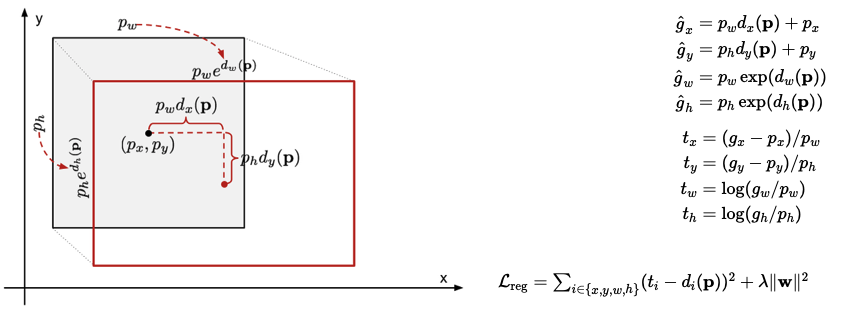
먼저 하나의 박스를 다음과 같이 표기할 수 있다. 여기서 x, y는 이미지의 중심점 w,h는 각각 너비와 높이이다.
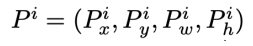
Ground Truth에 해당하는 박스도 다음과 같이 표기할 수 있다.
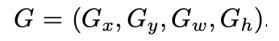
우리의 목표는 P에 해당하는 박스를 최대한 G에 가깝도록 이동시키는 함수를 학습시키는 것이다. box가 input으로 들어왔을 때 x, y, w, h를 각각 이동 시켜주는 함수들을 표현해보면 다음과 같다.
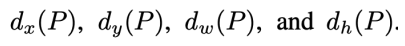
이 때 x, y는 점이기 때문에 이미지의 크기에 상관없이 위치만 이동시켜주면 된다. 반면에 너비와 높이는 이미지의 크기에 비례하여 조정을 시켜주어야 한다. 이러한 특성을 반영하여 P를 이동시키는 함수의 식을 짜보면 다음과 같다.
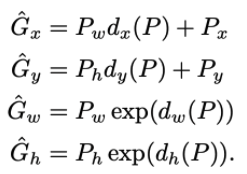
학습을 통해서 얻고자 하는 함수는 저 d 함수이다. 저자들은 이 d함수를 구하기 위해서 앞서 CNN을 통과할 때 pool5 레이어에서 얻어낸 특징 벡터를 사용한다. 그리고 함수에 학습 가능한 weight vector를 주어 계산한다. 이를 식으로 나타내면 아래와 같다.
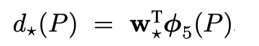
이제 weight를 학습시킬 loss 함수를 세워보면 다음과 같다. 일반적인 MSE에러 함수에 L2 normalization을 추가한 형태이다. 저자들은 람다를 1000으로 설정하였다. (Pi)는 VGG넷의 pool5를 거친 피쳐맵으로, 원래의 VGG에서는 이를 쫙 펴서 4096 차원의 벡터로 만든 다음 FC에 넘겨줍니다. 즉, φ(Pi)를 4096 차원 벡터라고 보면 w*역시 4096 차원 벡터인 것을 알 수 있습니다.
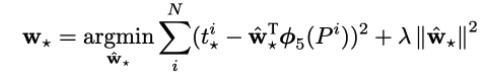
여기서 t는 p를 G로 이동시키기 위해서 필요한 이동량을 의미하며 식으로 나타내면 아래와 같다.
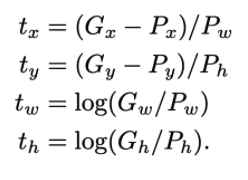
정리를 해보면 CNN을 통과하여 추출된 벡터와 x , y, w, h를 조정하는 함수의 weight를 곱해서 boundig box를 조정해주는 선형 회귀를 학습시키는 것이다.
Traing bounding box regressor using fine tuned alexnet
PASCAL 데이터셋에 Selective search 알고리즘을 적용하여 얻은 region proposals를 학습 데이터로 사용한다. 이 때 별도의 negative sample은 정의하지 않고 IoU값이 0.6이상인 sample을 positive sample로 정의한다. IoU값이 지나치게 작거나 겹쳐진 영역이 없는 경우, 모델을 통해 학습시키기 어렵기 때문이다. positive sample을 fine tuned된 AlexNet에 입력하여 얻은 feature vector를 Bounding Box regressor에 입력하여 학습시킨다. 추론 시 Bounding box regressor는 feature vector를 입력 받아 조정된 bounding box 좌표 값(output unit = 4)을 반환한다.
Input : 2000x4096 sized feature vector
Process : bounding box coordinates transformation by Bounding box regressor
output : 2000 bounding box coordinates
non-maximum suppression
linear svm모델과 bounding box regressor 모델을 통해 얻은 2000개의 bounding box를 전부 다 표시할 경우 하나의 객체에 대해 지나치게 많은 bounding box가 겹칠 수 있다. 이로 인해 객체 탐지의 정확도가 떨어질 수 있다. 이러한 문제를 해결하기 위해 감지된 box 중에서 비슷한 위치에 있는 box를 제거하고 가장 적합한 box를 선택하는 non maximum suppression 알고리즘을 적용한다. Non maximum suppression 알고리즘은 confidence score threshold가 높을 수록, iou treshold가 낮을수록 많은 box가 제거됩니다. 위의 과정을 통해 겹쳐진 box를 제거하고 최소한의 최적의 bounding box를 반환합니다. non maximum suppression은 다음 링크에서 확인 할 수 있습니다.
Input : 2000 bounding boxes
Process : removing unnecessary boxes with Non maximum suppression
output : optimal bounding boxes with classes
참고문헌
R-CNN 논문(Rich feature hierarchies for accurate object detection and semantic segmentation) 리뷰
이번 포스팅부터는 본격적으로 Object Detection 모델에 대해 살펴보도록 하겠습니다. 어떤 논문을, 어떤 순서에 따라 읽어야할지 고민하던 중, hoya님이 작성하신 2014~2019년도까지의 Object Detection 논
herbwood.tistory.com
(논문리뷰) R-CNN 설명 및 정리
컴퓨터비전에서의 문제들은 크게 다음 4가지로 분류할 수 있다. 1. Classification 2. Object Detection 3. Image Segmentation 4. Visual relationship 이중에서 4. Visual relationship은 나중에 다루고 먼저 위..
ganghee-lee.tistory.com
[논문 리뷰] R-CNN (2013) 리뷰
안녕하세요! 2021년이 시작함과 동시에 Object detection 논문을 읽게 되었습니다. 첫 번째로 읽어볼 논문은 R-CNN 'Rich feature hierarchies for accurate object detection and semantic segmentation' 입..
deep-learning-study.tistory.com
갈아먹는 Object Detection [1] R-CNN
들어가며 2020년을 맞이하여 가장 먼저 Object Detection을 공부해보기로 결심하여, 논문들을 차례로 리뷰해보려 합니다. (열정 충만!) 그 첫 번째 논문으로 딥 러닝 기반의 Object Detection의 시작을 연 R-
yeomko.tistory.com
딥러닝을 활용한 객체 탐지 알고리즘 이해하기
인공지능의 기반 기술 중 하나인 딥러닝은 눈부신 혁신을 거듭하고 있습니다. 텍스트 번역이나 이미지 분류 애플리케이션에 적합한 새로운 수준의 신경망이 개발되면서 사물인터넷(IoT)과 자율
blogsaskorea.com
Rich feature hierarchies for accurate object detection and semantic segmentation
Object detection performance, as measured on the canonical PASCAL VOC dataset, has plateaued in the last few years. The best-performing methods are complex ensemble systems that typically combine multiple low-level image features with high-level context. I
arxiv.org