

1. seq2seq이란?
seq2seq(sequence-to-sequence) 모델은 한 시퀀스를 다른 시퀀스로 변환하는 작업을 수행하는 딥러닝 모델로, 주로 자연어 처리(NLP) 분야에서 활용됩니다. 이 모델은 인코더(Encoder)와 디코더(Decoder)라는 모듈을 가지고 있습니다. 그래서 seq2seq를 Encoder-Decoder 모델이라고도 합니다. 이 두 모듈이 서로 협력하여 입력 시퀀스를 원하는 출력 시퀀스로 변환합니다. 아래 이미지는 seq2seq를 간단하게 도식화한 모습입니다.
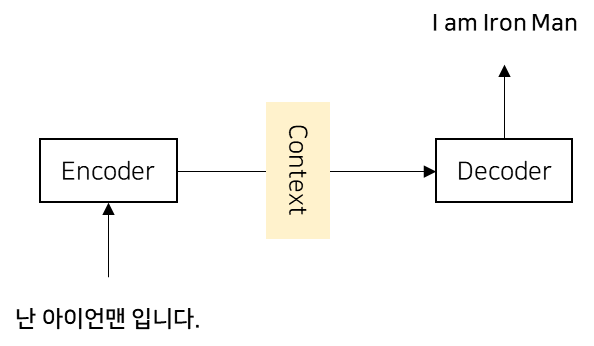
인코더는 입력 데이터를 인코딩하고, 디코딩은 인코딩된 데이터를 디코딩합니다. 쉽게 예를 들면 다음과 같습니다. 비밀편지를 쓸 때, 원래의 문장을 암호화해서 다른 사람이 쉽게 알아볼 수 없도록 바꾸는 과정이 필요합니다. 이 과정이 인코딩이 됩니다. "안녕 친구야"라는 문장을 "315, 526, 964"와 같은 숫자로 바꾸어 적는 것입니다. 디코딩은 인코딩과 반대로 다시 원래의 형태로 되돌려 주는 과정을 말합니다. "315, 526, 964"와 같은 문장을 다시 "안녕 친구야"라는 문장으로 바꾸어 읽는 것입니다.

2. 인코더
인코더는 일반적으로 RNN(Recurrent Neural Network)이나 LSTM(Long Short-Term Memory), GRU(Gated Recurrent Unit) 등의 순환 신경망 구조를 사용하여 입력 시퀀스를 고정 길이의 벡터로 변환하는 역할을 수행합니다. 이러한 구조는 시퀀스 데이터를 처리하는데 적합하며, 순차적인 정보를 효과적으로 인코딩할 수 있습니다.
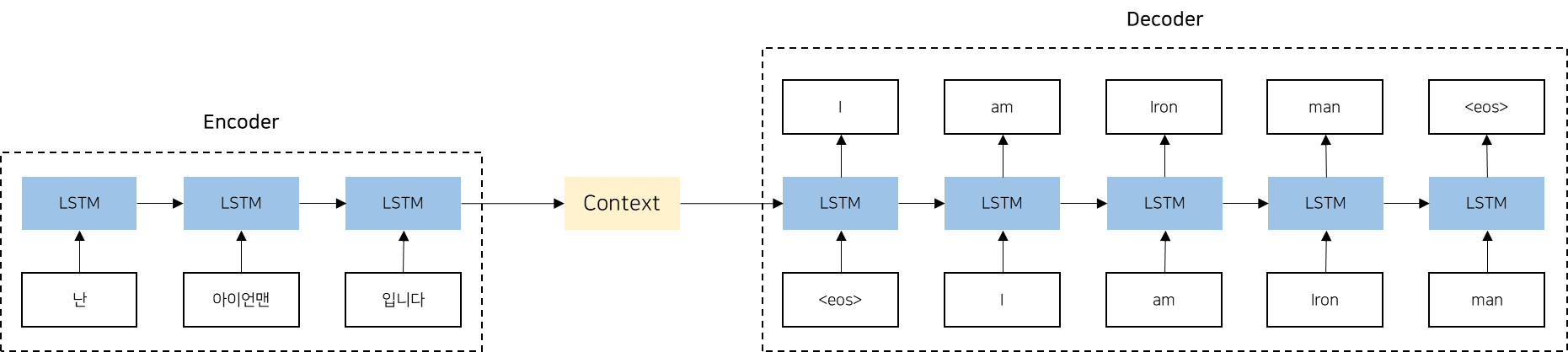
인코더는 아래의 그림같이 입력 시퀀스의 각 단어를 순차적으로 처리하면서 각 단계에서 hidden state를 업데이트하고, 최종적으로 전체 입력 시퀀스를 대표하는 고정 길에의 벡터를 생성합니다. 예를 들어 "난 아이언맨 입니다"라는 문장을 인코딩하여 고정 길이 벡터 h를 생성합니다. 인코딩된 정보는 디코더에 전달됩니다.
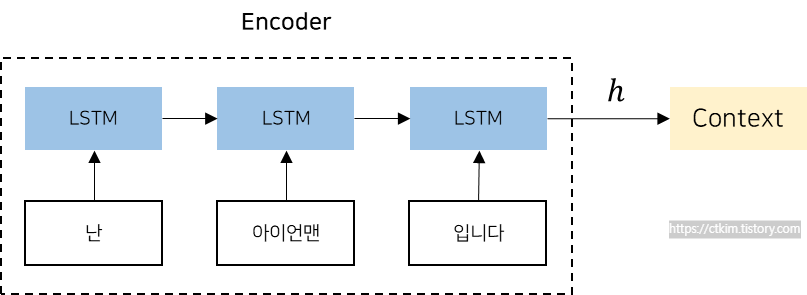
인코더가 생성한 벡터 h는 LSTM의 마지막 hidden state입니다. 여기서 중요한 점은 고정 길이 벡터라는 것입니다. 인코더가 인코딩 한다는 것은 임의의 길이의 문장을 고정 길이 벡터로 변환하는 작업이라고 말 할 수 있습니다.
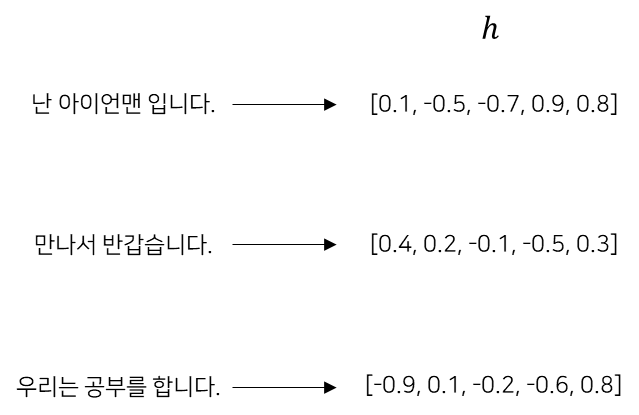
3. 디코더
디코더는 인코더의 출력인 고정 길이의 벡터를 기반으로 원하는 출력 시퀀스를 생성하는 역할을 수행합니다. 디코더 역시 RNN, LSTM, GRU 등의 순환 신경망 구조를 사용합니다. 기존 순환 신경망 구조와 다른 점은 벡터 h를 입력으로 받는다는 것입니다. 디코더의 예측은 일반적으로 소프트맥스 활성화 함수를 통해 확률 분포로 변환되며, 가장 확률이 높은 단어가 선택됩니다. 이 과정을 반복하여 최종적으로 출력 시퀀스가 생성됩니다.
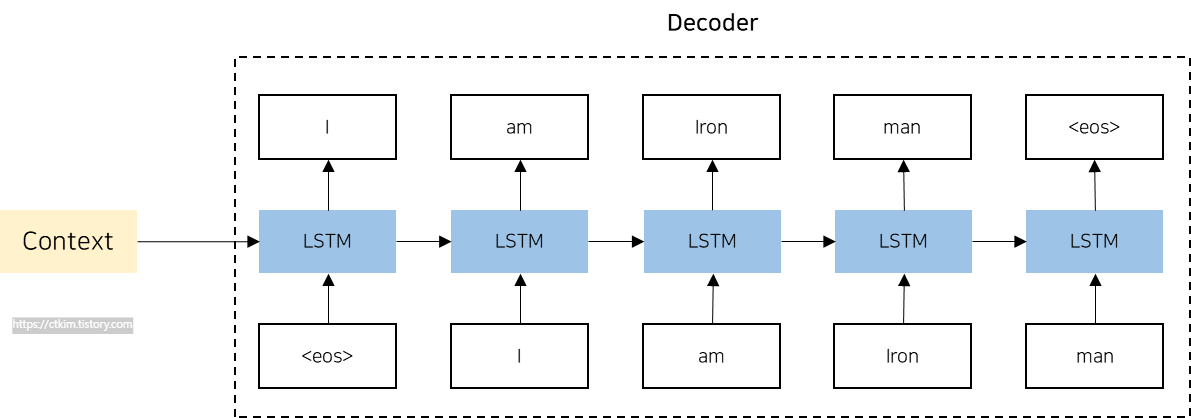
디코더에 보면 <eos>라는 구분 기호가 있는 것을 확인할 수 있습니다. 이 구분 기호는 디코더에게 문장 생성 시작과 종료를 알리는 신호로 사용됩니다. 이런 구분 기호는 <go>, <start>, <s>, 등을 이용하기도 합니다.
3. seq2seq architecture
아래 그림은 seq2seq의 전체적인 아키텍처를 보여줍니다. 이 그림에서 볼 수 있듯이, 인코더와 디코더 역할을 하는 두 개의 LSTM으로 구성되어 있습니다. 인코더와 디코더 사이에는 컨텍스트 벡터가 존재하며, 이를 통해 인코딩된 정보가 디코더로 전달됩니다. 역전파 과정에서는 컨텍스트 벡터를 통해 기울기가 디코더에서 인코더로 전달되어 모델이 학습됩니다.
4. seq2seq 코드
아래 코드는 간단한 seq2seq 예제 코드입니다. 이 예제에서는 LSTM 인코더와 디코더를 사용하며, 학습 데이터는 간단한 쌍으로 구성된 가상 데이터를 사용합니다.
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Input, LSTM, Dense
from tensorflow.keras.models import Model
# 가상의 학습 데이터 생성 (예: 입력 시퀀스: [1, 2, 3], 출력 시퀀스: [2, 3, 4])
input_data = np.array([[[1, 2, 3]]], dtype=np.float32)
output_data = np.array([[[2, 3, 4]]], dtype=np.float32)
#인코더 정의
encoder_inputs = Input(shape=(None, 1))
encoder_lstm = LSTM(units=16, return_state=True)
_, encoder_h, encoder_c = encoder_lstm(encoder_inputs)
encoder_states = [encoder_h, encoder_c]
필요한 라이브러리를 임포트하고 가상의 학습 데이터를 생성합니다. 그리고 인코더를 정의합니다. 이때 LSTM을 사용하며 '_, encoder_h, encoder_c' 출력값은 사용하지 않고, 은닉 상태('encoder_h')와 셀 상태('encoder_c')만 사용합니다. 출력값을 사용하지 않는 이유는 인코더의 목적은 고정된 길이의 컨텍스트 벡터로 변환해서 사용하는 것이기 때문입니다.
# 디코더 정의
decoder_inputs = Input(shape=(None, 1))
decoder_lstm = LSTM(units=16, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(decoder_inputs, initial_state=encoder_states)
decoder_dense = Dense(units=1, activation='linear')
decoder_outputs = decoder_dense(decoder_outputs)
# seq2seq 모델 구성
model = Model(inputs=[encoder_inputs, decoder_inputs], outputs=decoder_outputs)
# 모델 컴파일 및 학습
model.compile(optimizer='adam', loss='mean_squared_error')
model.fit([input_data, input_data], output_data, batch_size=1, epochs=100)
디코더에서도 LSTM을 사용합니다. 'decoder_outputs, _, _ ' 디코더는 은닉상태와 셀 상태는 사용하지 않기 때문에, 이 값은 무시하고 출력값만 사용합니다. 디코더 정의가 끝나면 모델을 구성하고 학습합니다.
5. seq2seq 한계
인코더가 입력 시퀀스를 하나의 고정된 길이의 벡터로 압축합니다. 이로 인해 입력 시퀀스의 길이가 길어질수록 정보의 손실이 발생할 수 있습니다. 또한 RNN의 고질적인 문제인 경사 소실 또는 폭발 문제가 존재한다는 것입니다. 이를 극복하기 위해 제안된 방법이 어텐션 매커니즘입니다.