

☞ 문서의 내용은 가장 하단 참고문헌 및 사이트를 참고하여 필자가 보기 쉽도록 정리한 내용입니다.
☞ 틀린 내용 및 저작권 관련 문의가 있는 경우 문의하시면 수정 및 삭제 조치하겠습니다.
머신러닝을 위한 Data set을 정제할 때, 특성별로 데이터의 Scale이 다르면 머신러닝이 잘 작동하지 않게 될 수 있다. 예를 들어 X1 특성은 0부터 1사이의 소수값을 가진다. X2 특성은 100000부터 100000000사이의 소수값을 가진다. y 값은 1000000부터 100000000까지의 값을 가진다. 그렇다면 X1의 특성은 y를 예측하는데 큰 영향을 주지 않는 것으로 생각 할 수 있다. 이 외에도 overflow, underflow 등의 문제가 있을 수 있다. 때문에 데이터 스케일링 작업을 통해 모든 특성의 범위(또는 분포)를 갖게 만들어야 한다.
스케일링 주의사항
-
Normalization, Standardization, Regularization의 용어는 모두 한국어로 정규화라고 번역된다. 때문에 가능한 용어들을 한글이 아닌 영어로 작성한다.
-
Scaler는 fit과 transform메서드를 지니고 있다. fit메서드로 데이터 변환을 학습하고, transform 메서드로 실제 데이터의 스케일을 조정한다. 이때, fit 메서드는 학습용 데이터에만 적용해야한다. 그 후, transform 메서드를 학습용 데이터와 테스트 데이터에 적용한다.
-
일반적으로 타겟(y) 데이터에 대한 스케일링은 진행하지 않는다.
-
많은 스케일러들이 이상치의 영향을 많이 받는다. 때문에 최대한 먼저 이상치를 제거해주는 것이 좋다.
-
스케일링 할 때, 모든 특성의 범위를 유사하게 만드는 것은 중요하지만, 반드시 같은 분포로 만들 필요는 없다.
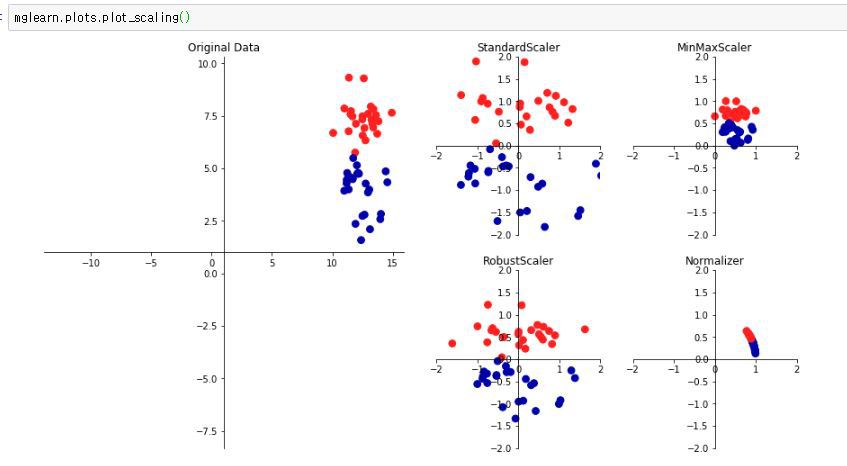
1. StandardScaler(Standardization)
값의 범위(scale)를 평균 0, 분산 1이 되도록 변환한다. 즉 데이터를 정규분포로 만든다. 하한값과 상한값이 존재하지 않을 수 있기에, 어떤 알고리즘에서는 문제가 있을 수 있다. 회귀보다 분류에 유용하다. 모든 특성 들이 같은 스케일을 갖게 된다.
2. RobustScaler
각 특성들의 평균과 분산 대신 특성들의 중앙값을 0, IQE을 1로 스케일링한다. 모든 특성들이 같은 크기를 갖는다는 점에서 StandardScaler와 비슷하지만, RobustScaler는 이상치에 영향을 받지 않는다.
3. MinMaxScaler(a,b) (Normalization)
각 특성의 하한값을 a, 상한값을 b로 스케일링합니다. a=0, b=1일 경우 Normalization으로 표기할 때도 있습니다. 데이터가 2차원 셋일 경우, 모든 데이터는 x축의 0과 1사이에 y축의 0과 1사이에 위치하게 된다. 분류보다 회귀에 유용합니다.
4. MaxAbsScaler
각 특성을 절대값이 0과 1사이가 되도록 스케일링합니다. 즉, 모든 값은 -1과 1사이로 표현되며, 데이터가 양수일 경우 MinMaxScaler와 같습니다. 큰 이상치에 민감할 수 있다.
5. Normalizer
앞의 4가지 스케일러는 각 특성(열, columns)의 통계치를 이용하여 진행됩니다. 그러나 Normalizer는 각 샘플(행, row)마다 적용되는 방식이다. Normalizer는 유클리드 거리(L2 norm)가 1이 되도록 조정한다. 일반적인 데이터 전처리의 상황에서 사용되는 것이 아니라, 모델(딥러닝) 내 학습 벡터에 적용하며, 특히나 피쳐들이 다른 단위(키, 나이, 소득 등)라면 사용하지 않는다.
참고 자료
데이터 스케일링(Data Scaling)
코드 머신러닝을 위한 데이터셋을 정제할 때, 특성별로 데이터의 스케일이 다르다면 어떤 일이 벌어질까요. 예를 들어, X1 특성은 0부터 1사이의 소수값을 갖는다 비해, X2 특성은 1000000부터 1000000
junklee.tistory.com
데이터 스케일링 (Data Scaling)
데이터 스케일링이란 데이터 전처리 과정의 하나입니다. 데이터 스케일링을 해주는 이유는 데이터의 값이 너무 크거나 혹은 작은 경우에 모델 알고리즘 학습과정에서 0으로 수렴하거나 무한으
homeproject.tistory.com
[딥러닝] 정규화? 표준화? Normalization? Standardization? Regularization?
딥러닝을 공부하다 보면 “정규화” 라는 용어를 참 자주 접하게 된다. 그런데 애석하게도 Normalization, Standardization, Regularization 이 세 용어가 모두 한국어로 정규화라고 번역된다. 이 세가지 용어
realblack0.github.io