

☞ 문서의 내용은 가장 하단 참고문헌 및 사이트를 참고하여 필자가 보기 쉽도록 정리한 내용입니다.
☞ 틀린 내용 및 저작권 관련 문의가 있는 경우 문의하시면 수정 및 삭제 조치하겠습니다.
Fully Convolutional Networks(FCN)
Fully Convolutional networks(이하 FCN)은 제목에서 나타나듯 Semantic Segmentation문제를 위해 제안된 딥러닝 모델이다. Semantic Segmentation은 단순히 BB(bounding box)을 하는 문제가 아니라 이미지를 pixel단위로 구분해 각 pixel이 어떤 물체 class인지 구분하는 문제이다. FCN은 기존에 이미지 분류에서 사용된 CNN기반 모델(AlexNet, VGG, GoogLeNet)을 Segmentation 목적에 맞춰 마지막 출력층 FCL(Fully Connected layer)을 FCN으로 대체하여 문제를 해결했다.
FCN 네트워크 구조
-
(1) Feature Extraction(특징 추출)
- 일반적인 CNN의 구조에서 많이 보이는 Convolutional layer들로 구성되어 있다.
-
(2) Feature-level Classification
- 추출된 Feature map의 모든 pixel 마다 classification을 수행한다.
- 이때 classification 된 결과는 매우 Coarse 하다.
-
(3) Upsampling
- Coarse한 결과를 Upconvolution을 통해 upsampling 하여 원래의 image size로 키운다.
-
(4) Segmentation
- 각 Class의 upsampling된 결과를 사용하여 하나의 Segmentation 결과 이미지를 만든다.
Convolutionalization
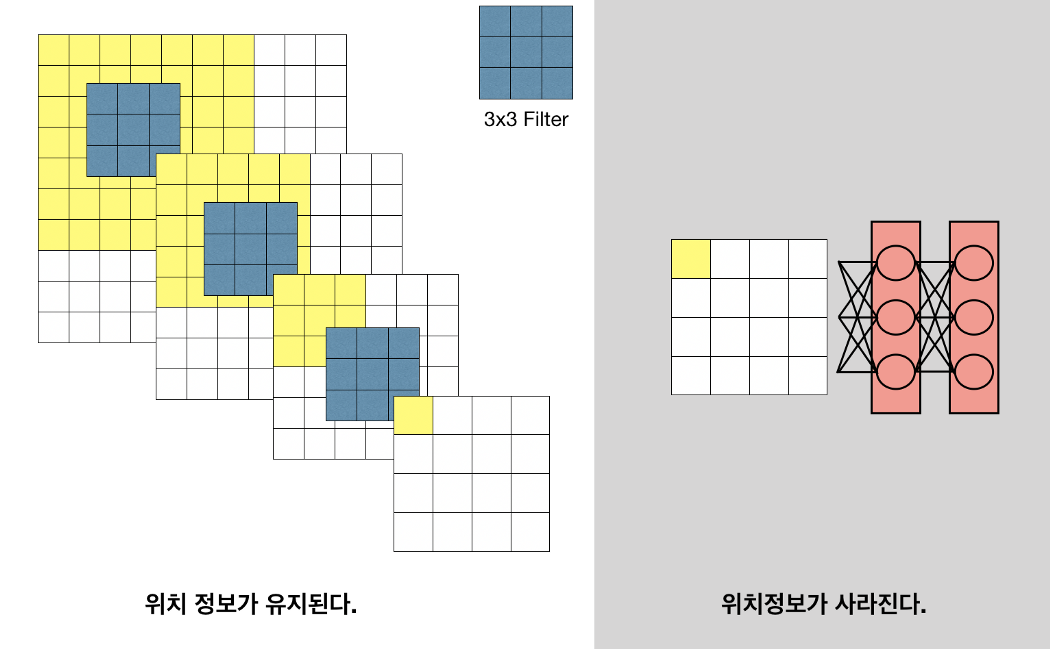
Image Classification 모델들은 기본적으로 내부 구조와 관계없이 모델의 근본적인 목표를 위해 출력층이 FCL로 구성되어 있다. 그런데 Semantic Segmentation의 관점에서는 FCL이 갖는 한계점이 있다. 첫 번째로 이미지의 위치 정보가 사라진다. 두 번째로 입력 이미지 크기가 고정된다. Segmentation의 목적은 원본 이미지의 각 픽셀에 대해 클래스를 구분하고 인스턴스 및 배경을 분할하는 것으로 위치 정보가 매우 중요하다. 이러한 FCL의 한계를 보완하기 위해 모든 FCL을 FCN으로 대체하는 방법을 택하였다.
아래 그림(좌)를 보게 되면 fully-connected layer 연산 이후 Receptive field 개념이 사라진다. 그림(우)를 보게 되면 Dense layer에 가중치 개수가 고정되어 있기 때문에 바로 앞 레이어의 Feature Map의 크기도 고정되며, 연쇄적으로 각 레이어의 Feature Map 크기와 Input Image 크기 역시 고정된다.

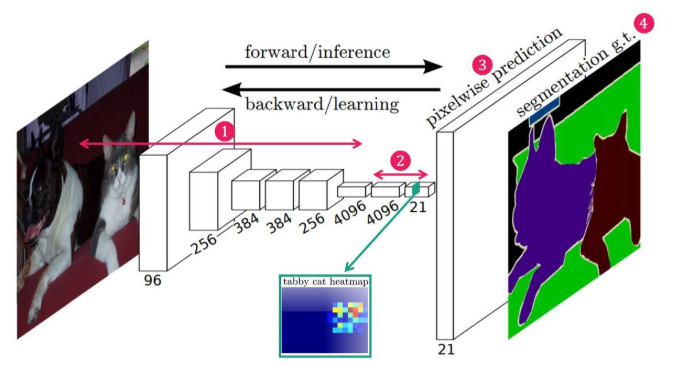
VGG-16은 feature의 뒤에 4096, 4096, 1000으로 이어지는 FCL을 연결하여 Classification을 한다. 하지만 본 논문에서는 아래 그림처럼 FCL을 모두 1x1형태의 Convolution으로 전환한다. 그 이유는 위에서 설명한 것 처럼 위치 정보가 손실되지 않고, 어떠한 입력 이미지의 크기도 허용될 수 있기 때문이다. 이 1x1 conv의 결과물이 class의 feautre map상에서의 classification(즉, segmentation)이 된다. 1x1 conv depth channel은 각 class를 의미하므로, 어떤 class의 segmentation heatmap도 추정할 수 있다.


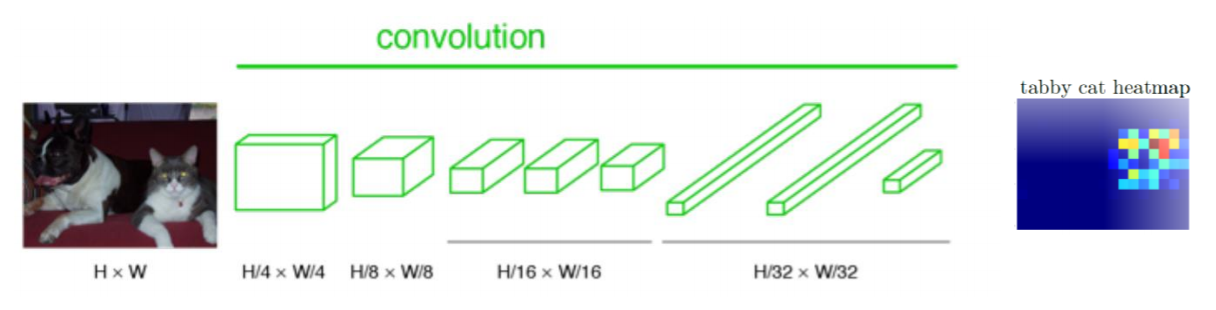
Convolutionalization을 통해 출력 Feature map은 원본 이미지의 위치 정보를 내포할 수 있게 되었다. 그러나 Semantic segmentation의 최종 목적인 픽셀 단위 예측과 비교했을 때, FCN의 출력 Feature map은 너무 coarse 하다. 따라서, Coarse map을 원본 이미지 크기에 가까운 Dense map으로 변환해줄 필요가 있다. (예를 들면, 고양이 Calss에 대한 heatmap이라면 고양이가 있는 위치의 픽셀값이 높고 강아지 Class에 대한 heatmap이라면 강아지 위치의 픽셀 값들이 높을 것이다. 그렇기에 대력적인(coase) heatmap들의 크기를 원래 이미지의 크기로 다시 복원해줄 필요가 있다. (이미지의 모든 픽셀에 대해 Class를 예측(dense prediction)하는 것이 semantic segmentation의 목적이기 때문에)
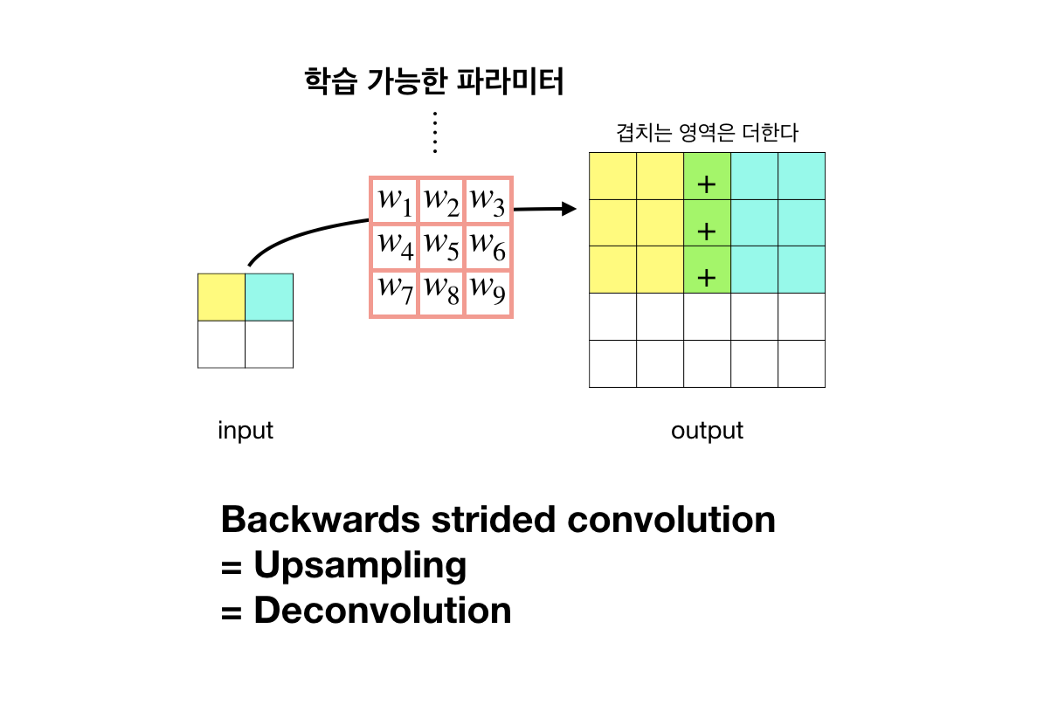
Upsampling
heatmap을 dense하게(원래의 image size) 만들어줘야 한다. 본 논문에서는 backward convolution(deconvolution, transposed convolution)이라고 불리는 학습 기반 upsampling을 적용했다. Stride가 2이상인 Convolution 연산의 경우 input iamge에 대해 크기가 줄어든 특징 맵을 출력한다. 이것은 Down-sampling에 해당한다. Convolution 연산을 반대로 할 경우 자연스럽게 Up-Sampling효과를 볼 수 있다. 또한, 이때 사용하는 Filter의 가중치 값은 학습 파라미터에 해당한다. 그런데 upsampling 과정에서 coarse한 결과를 dense 하게 만들어 줄 때 너무 많이 커지기 때문에 아래 그림처럼 뭉개진 segmentation 결과를 얻을 수 밖에 없다. 때문에 보다 정교한 Segmentation을 위해서 추가적인 작업이 필요하다.


Skip Architecture
정확하고 상세한 Segmentation을 얻기 위해 Deep&Coarse(추상적인) 레이어의 의미적(Semantic)정보와 Shallow&fine층의 외관적(appearance) 정보를 결합한 Skip architecture(얕은 층의 fine location 정보와 깊은 층의 global semantic 정보를 결합하는)를 정의한다.

아래 그림을 보면 시각화 모델을 통해 입력 이미지에 대해 얕은 층에서는 주로 직선 및 곡선, 색상 등의 낮은 수준의 특징에 활성화되고, 깊은 층에서는 보다 복잡하고 포괄적인 개체 정보에 활성화된다는 것을 확인할 수 있다. 또한 얕은 층에선 local feature를 깊은 층에선 global feature를 감지한다고 볼 수 있다.

FCN 연구팀은 이러한 직관을 기반으로 앞에서 구한 Dense map에 얕은 층의 정보를 결합하는 방식으로 Segmentation의 품질을 개선했다. 논문에서는 Upsample stride를 32, 16, 8을 각각 사용했는데, upsample stride가 32라면 feature map의 정보 하나를 32개로 늘려놓는다는 것이다. 즉, 아래의 사진과 같이 원래의 크기대로 복원시켜 segmentation 된 output을 얻겠다는 것이다.

위 그림을 보면, 마지막 pool 5 layer에서 stride 32로 upsample을 해서 prediction map을 만들어낸다. 하지만, pooling layer를 거치면 거칠수록 원래의 정보보단 고차원적인 feature들의 정보가 있으므로 32배로 upsample 한 결과는 디테일하지 못하다. 그렇기에 이 논문에서 제안하는 것이 그 전의 layer의 정보도 같이 사용하자(skip combining)는 것이다. 그 전의 layer는 현재의 layer가 가지는 정보보다 디테일한 정보를 가지고 있기 때문에 복원하는 데에 있어서 좀 더 효율적이라는 이야기이다.

Skip combining은 이전의 결과 다음에 pool 5 layer를 bilinear interpolation을 이용하여 stride 2로 upsample을 해서 초기화(initialize)한 prediction map을 구한다. 그 후에 그 전의 layer인 pool4 layer와 pixelwise summation을 실행하여 stride 16으로 upsample을 시행하여 prediction map을 구한다. 다음 계속해서 이전의 stride16으로 upsample 하기 전의 summation의 값을 bilinear interpolation으로 stride 2로 upsample 해 prediction map을 구한다. 그 후에 pool4의 전 layer 인 pool3 layer와 pixelwise summation을 한다. 그다음 stride 8로 upsample을 해서 최종 prediction map을 생성해내게 된다. 이러한 Skip Architecture를 통해 아래와 같이 개선된 Segmentation 결과를 얻을 수 있다.

참고 자료
Fully Convolutional Networks for Semantic Segmentation
논문 링크 : Fully Convolutional Networks for Semantic Segmentation Introduction Semantic Segmentation는 영상을 pixel단위로 어떤 object인지 classification 하는 것이라고 볼 수 있습니다. (언제나 강력추천하는) cs231n 강의
modulabs-biomedical.github.io
[Semantic Segmentation] FCN 원리
* 논문 : https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn.pdf 1. Semantic Segmentation의 목적 : https://kuklife.tistory.com/118?category=872136 2. Semantic Segmentation 알고리즘 - FCN..
kuklife.tistory.com
FCN 논문 리뷰 — Fully Convolutional Networks for Semantic Segmentation
딥러닝 기반 OCR 스터디 — FCN 논문 리뷰
medium.com