1. Numpy 집계 함수
Numpy는 데이터 분석을 위해 다양한 집계 함수(Aggregate functions)를 제공합니다. 이러한 함수를 사용하면 배열의 요소에 대해 특정 계산을 수행할 수 있습니다. 대표적인 집계 함수들은 다음과 같습니다.
- np.sum(): 배열의 모든 요소의 합을 계산합니다.
- np.min(), np.max(): 배열의 최소값 또는 최대값을 찾습니다.
- np.mean(): 배열의 평균 값을 계산합니다.
- np.median(): 배열의 중간값(median)을 찾습니다.
- np.std(): 배열의 표준 편차를 계산합니다.
- np.var(): 배열의 분산을 계산합니다.
1.1 np.sum()
이 함수는 배열의 모든 요소의 합계를 계산합니다. 데이터의 전체적인 누적치를 알고 싶을 때 유용합니다.
import numpy as np
data = np.array([[1, 2, 3], [4, 5, 6]])
# 모든 요소의 합계를 계산
total = np.sum(data, axis=None)
print("Total sum: ", total) # 출력: Total sum: 21
# 각 열의 합계를 계산
total_column = np.sum(data, axis=0)
print("Column sum: ", total_column) # 출력: Column sum: [5 7 9]
# 각 행의 합계를 계산
total_row = np.sum(data, axis=1)
print("Row sum: ", total_row) # 출력: Row sum: [ 6 15]

1.2 np.min(), np.max()
이 함수는 배열의 최소값(np.min())과 최대값(np.max())을 계산합니다. 데이터의 범위를 알고 싶을 때 유용하게 사용됩니다.
import numpy as np
data = np.array([8, 2, 6, 1, 5])
minimum = np.min(data)
maximum = np.max(data)
print("Min: ", minimum) # 출력: Min: 1
print("Max: ", maximum) # 출력: Max: 8

1.3 np.mean()
이 함수는 배열의 평균 값을 계산합니다. 데이터의 중심을 파악하는데 사용됩니다.
import numpy as np
data = np.array([8, 2, 6, 1, 5])
average = np.mean(data)
print("Mean: ", average) # 출력: Mean: 4.4
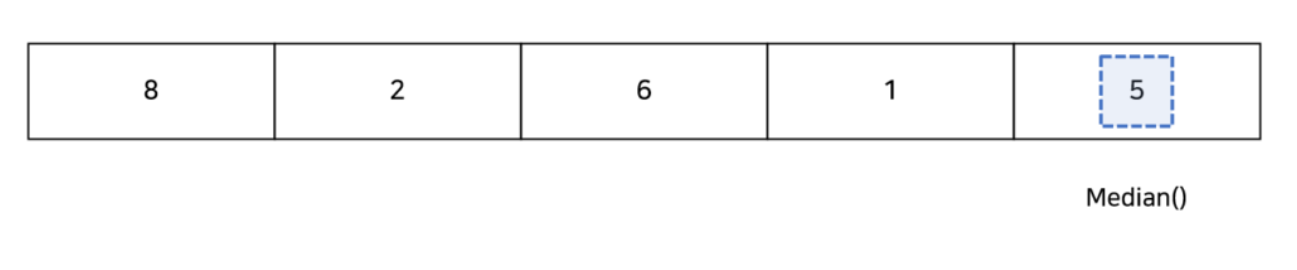
1.4 np.median()
이 함수는 배열의 중간값(median)을 계산합니다. 평균과 함께 데이터의 중심을 파악하는데 사용됩니다.
import numpy as np
data = np.array([8, 2, 6, 1, 5])
middle = np.median(data)
print("Median: ", middle) # 출력: Median: 5.0
1.5 np.std()
이 함수는 배열의 표준 편차를 계산합니다. 데이터가 평균으로부터 얼마나 퍼져 있는지를 나타내는 값입니다.
import numpy as np
data = np.array([1, 2, 3, 4, 5])
std_dev = np.std(data)
print("Standard Deviation: ", std_dev) # 출력: Standard Deviation: 1.4142135623730951
1.6 np.var()
이 함수는 배열의 분산을 계산합니다. 표준 편차의 제곱이며, 데이터가 평균으로부터 얼마나 퍼져 있는지를 나타내는 또 다른 척도입니다.
import numpy as np
data = np.array([1, 2, 3, 4, 5])
variance = np.var(data)
print("Variance: ", variance) # 출력: Variance: 2.0
2. Numpy 정렬과 분할 함수
2.1 np.sort()
이 함수는 입력 배열을 오름차순으로 정렬한 새 배열을 반환합니다. 기본적으로 퀵 정렬 알고리즘을 사용하지만, 병합 정렬이나 힙 정렬도 선택할 수 있습니다. 아래 코드에서, np.sort() 함수는 새 배열을 반환합니다. 원본 배열을 직접 정렬하려면 배열의 sort() 메서드를 사용할 수 있습니다.
import numpy as np
data = np.array([5, 1, 6, 2, 3])
sorted_data = np.sort(data)
print("Original: ", data) # 출력: Original: [5 1 6 2 3]
print("Sorted: ", sorted_data) # 출력: Sorted: [1 2 3 5 6]
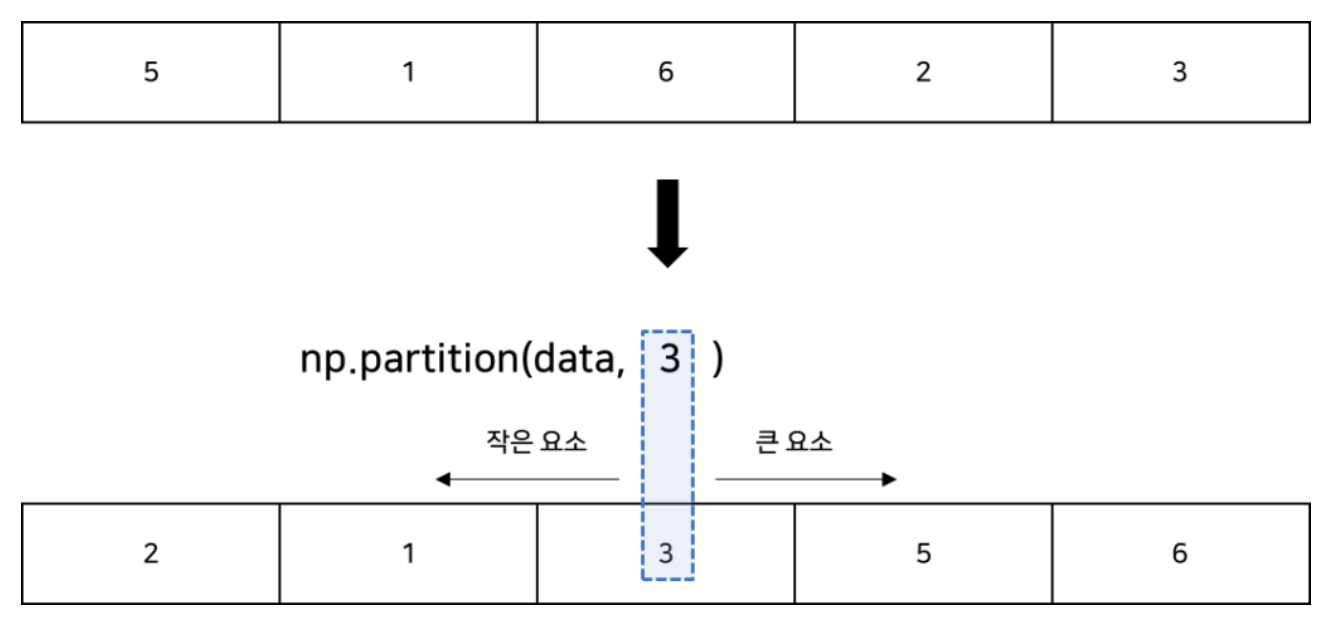
2.2 np.partition()
이 함수는 'k-번째' 위치에 있는 요소를 기준으로 작은 요소들을 왼쪽에, 큰 요소들을 오른쪽에 위치시킵니다. 이는 'k-번째' 최소값을 찾는 데 효율적입니다. 아래 코드에서, np.partition() 함수는 3번째 위치에 있는 요소를 기준으로 배열을 분할합니다. 그 결과 배열에서 첫 세 요소는 분할 지점보다 작거나 같고, 나머지 요소는 분할 지점보다 큽니다.
import numpy as np
data = np.array([5, 1, 6, 2, 3])
partitioned_data = np.partition(data, 3)
print("Original: ", data) # 출력: Original: [5 1 6 2 3]
print("Partitioned: ", partitioned_data) # 출력: Partitioned: [2 1 3 5 6]
2.3 np.array_split()
이 함수는 입력 배열을 주어진 수의 동일한 크기의 하위 배열로 분할합니다. 만약 배열을 동일한 크기로 분할할 수 없다면, 마지막 하위 배열만 더 작을 수 있습니다. 아래 코드에서, `np.array_split()` 함수는 입력 배열을 3개의 하위 배열로 분할합니다.
import numpy as np
data = np.array([1, 2, 3, 4, 5, 6])
split_data = np.array_split(data, 3)
print("Original: ", data) # 출력: Original: [1 2 3 4 5 6]
print("Split: ", split_data) # 출력: Split: [array([1, 2]), array([3, 4]), array([5,6])]
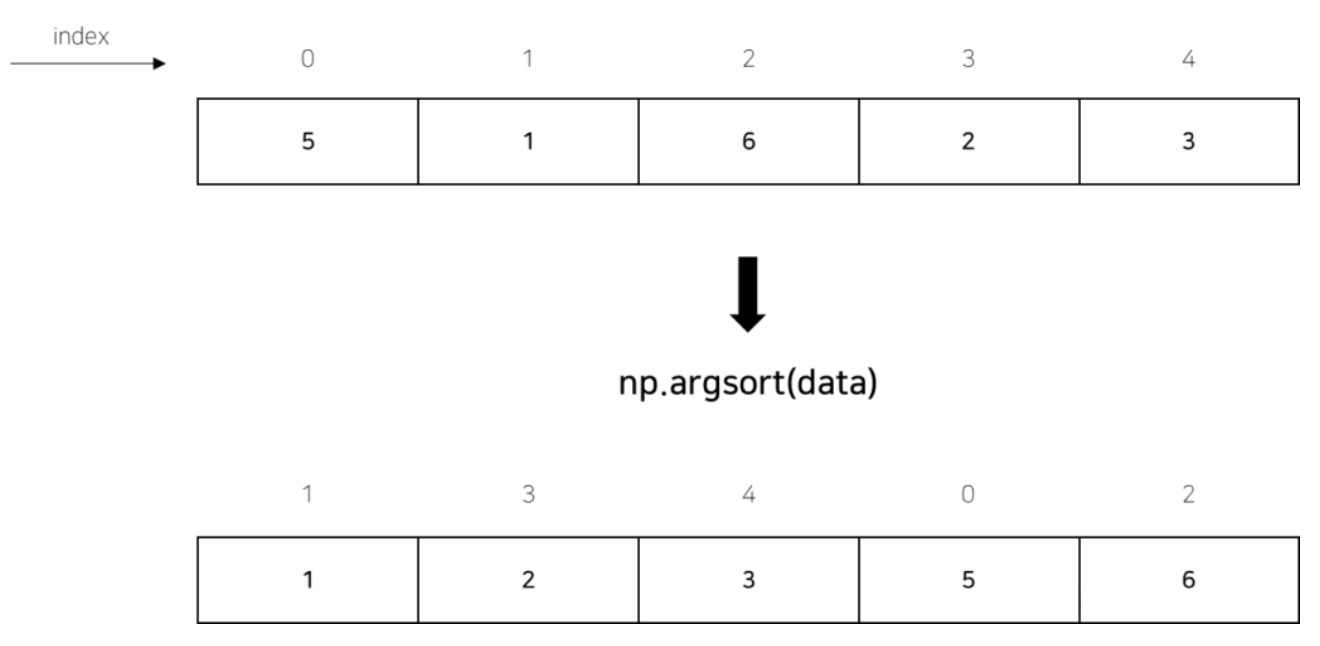
2.4 np.argsort()
이 함수는 배열을 정렬했을 때의 인덱스를 반환합니다. 즉, 원래 배열에서 정렬된 배열로 요소를 재정렬하려면 어떤 순서로 인덱스를 사용해야 하는지를 알려줍니다. 아래 코드에서, np.argsort() 함수는 정렬된 배열에서 각 요소의 인덱스를 반환합니다. 예를 들어, 원래 배열에서 가장 작은 요소는 1이며, 이는 원래 배열의 인덱스 1에 위치해 있습니다.
import numpy as np
data = np.array([5, 1, 6, 2, 3])
sort_indices = np.argsort(data)
print("Data: ", data) # 출력: Data: [5 1 6 2 3]
print("Sort Indices: ", sort_indices) # 출력: Sort Indices: [1 3 4 0 2]
2.5 np.split()
이 함수는 배열을 동일한 크기의 여러 하위 배열로 분할합니다. np.array_split()과는 달리, np.split()은 배열을 동일한 크기의 하위 배열로 정확히 분할할 수 없는 경우 오류를 발생시킵니다. 예제에서, np.split() 함수는 입력 배열을 3개의 하위 배열로 분할합니다.
import numpy as np
data = np.array([1, 2, 3, 4, 5, 6])
split_data = np.split(data, 3)
print("Original: ", data) # 출력: Original: [1 2 3 4 5 6]
print("Split: ", split_data) # 출력: Split: [array([1, 2]), array([3, 4]), array([5, 6])]
3. Numpy 수학 함수
3.1 np.sin(), np.cos(), np.tan()
이들 함수는 각각 배열의 요소에 대한 사인, 코사인, 탄젠트 값을 계산합니다.
import numpy as np
angles = np.array([0, np.pi / 2, np.pi])
print("sin: ", np.sin(angles)) # 출력: sin: [0.0000000e+00 1.0000000e+00 1.2246468e-16]
print("cos: ", np.cos(angles)) # 출력: cos: [ 1.000000e+00 6.123234e-17 -1.000000e+00]
print("tan: ", np.tan(angles)) # 출력: tan: [ 0.00000000e+00 1.63312394e+16 -1.22464680e-16]
3.2 np.exp()
이 함수는 배열의 각 요소에 대해 자연 상수 e (약 2.71828)의 거듭제곱을 계산합니다.
import numpy as np
values = np.array([1, 2, 3])
print("exp: ", np.exp(values)) # 출력: exp: [ 2.71828183 7.3890561 20.08553692]
3.3 np.log(), np.log2(), np.log10()
이들 함수는 각각 자연 로그, 로그 밑 2, 로그 밑 10을 계산합니다.
import numpy as np
values = np.array([1, np.e, np.e**2])
print("log: ", np.log(values)) # 출력: log: [0. 1. 2.]
print("log2: ", np.log2(values)) # 출력: log2: [0. 1.44269504 2.88539008]
print("log10: ", np.log10(values)) # 출력: log10: [0. 0.43429448 0.86858896]
3.4 np.sqrt()
이 함수는 배열의 각 요소의 제곱근을 계산합니다.
import numpy as np
values = np.array([1, 4, 9])
print("sqrt: ", np.sqrt(values)) # 출력: sqrt: [1. 2. 3.]
4. Numpy 유용한 함수
4.1 np.any(), np.all()
np.any() 함수는 배열 내에서 어느 한 요소라도 참(True)이면 True를 반환하고, np.all() 함수는 배열의 모든 요소가 참(True)일 때 True를 반환합니다.
import numpy as np
arr = np.array([True, False, True])
print("Any: ", np.any(arr)) # 출력: Any: True
print("All: ", np.all(arr)) # 출력: All: False
4.2 np.where()
np.where() 함수는 특정 조건을 만족하는 요소의 인덱스를 반환합니다. 아래 코드에서는 배열 arr에서 값이 3보다 큰 요소의 인덱스를 찾습니다. 이 인덱스를 다시 배열 arr에 적용하면 조건을 만족하는 값들을 얻을 수 있습니다.
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
index = np.where(arr > 3)
print("Index: ", index) # 출력: Index: (array([3, 4]),)
print("Values: ", arr[index]) # 출력: Values: [4 5]
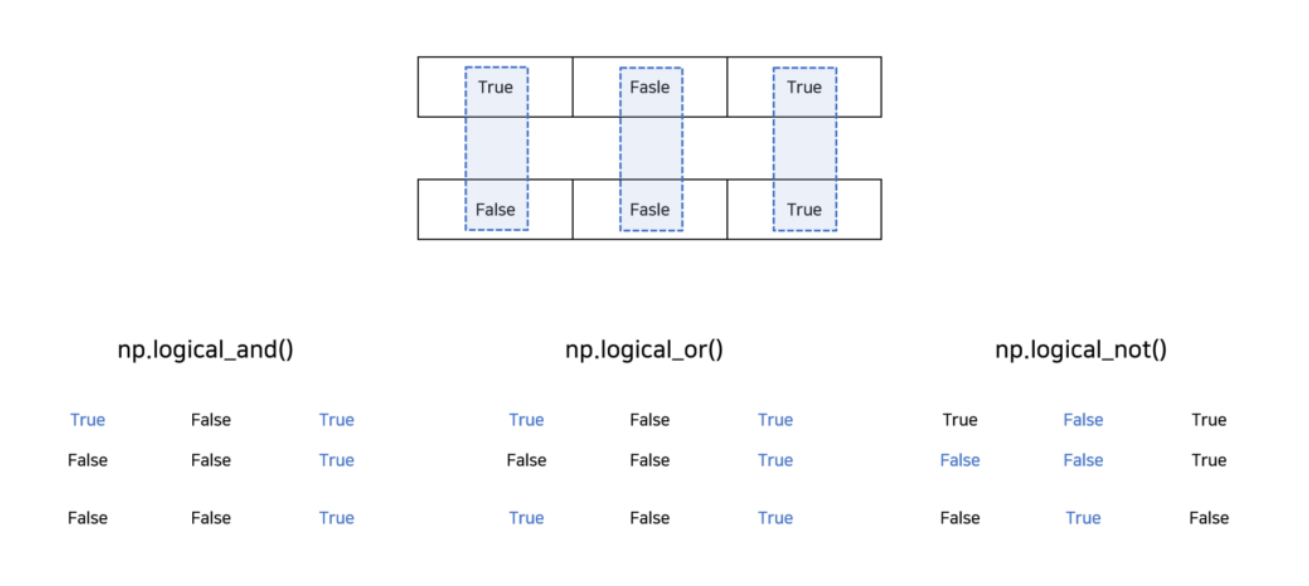
4.3 np.logical_and(), np.logical_or(), np.logical_not()
이들 함수는 요소별 논리 연산을 수행합니다. 각각 논리 'AND', 'OR', 'NOT' 연산에 해당합니다. 코드에서는 각 논리 연산 함수를 사용하여 두 개의 Boolean 배열을 연산합니다.
import numpy as np
arr1 = np.array([True, False, True])
arr2 = np.array([False, False, True])
print("Logical AND: ", np.logical_and(arr1, arr2)) # 출력: Logical AND: [False False True]
print("Logical OR: ", np.logical_or(arr1, arr2)) # 출력: Logical OR: [ True False True]
print("Logical NOT: ", np.logical_not(arr1)) # 출력: Logical NOT: [False True False]