

1. Numpy 배열
Numpy 배열은 값들이 동일한 데이터 타입을 갖는 그리드 형태의 데이터 구조입니다. 여기서 그리드 형태란 Numpy 배열 요소들이 행(row)과 열(column)로 이루어진 구조를 말합니다. 각 값은 양의 정수로 색인(index)화됩니다. 배열의 차원 수는 배열의 rank로 표현되며, 배열의 모양은 각차원에 따라 몇 개의 항목이 있는지를 나타내는 정수의 튜플로 표현됩니다. Numpy 배열은 파이썬의 기본 리스트와는 다른 형태를 가집니다.
Numpy 를 공부하다보면 ndarray라는 단어를 듣게됩니다. ndarray는 "N-dimensional array"의 줄임말로, 임의의 차원으로 구성된 배열을 의미합니다. N차원 배열은 단순한 배열로, 1차원이나 2차원부터 시작하여 임의의 수의 차원으로 구성될 수 있습니다. NumPy의 ndarray 클래스는 행렬과 벡터를 모두 나타내는 데 사용됩니다. 벡터는 단일 차원 배열로, 행 벡터와 열 벡터의 차이는 없습니다. 2차원 이상은 다차원 배열입니다. 3차원 이상의 다차원 배열은 일반적으로 "텐서"라는 용어로도 불리기도 합니다.
1.1 배열의 속성
Numpy 배열은 여러 가지 속성을 가지고 있습니다. 이러한 속성들을 활용하여 배열의 크기, 차원, 데이터 타입 등을 확인할 수 있습니다.
- ndarray.ndim : 배열의 차원(축)의 개수를 나타냅니다.
- ndarray.shape : 배열의 모양을 나타내는 정수의 튜플입니다. 각 차원에서 배열의 크기를 나타냅니다.
- ndarray.size : 배열의 모든 원소의 개수를 나타냅니다.
- ndarray.dtype : 배열에 저장된 원소의 타입을 나타내는 객체입니다.
- ndarray.itemsize : 배열에 저장된 각 원소의 크기를 바이트 단위로 나타냅니다

아래 코드는 Numpy를 사용하여 특정한 데이터 구조를 생성하고, 그 구조에 대한 속성을 출력하는 코드입니다. my_list는 3차원의 리스트입니다. 이 리스트는 2개의 2차원 리스트로 구성되며, 각 2차원 리스트는 3개의 1차원 리스트로 구성되어 있습니다. 이 리스트를 Numpy의 array 함수를 사용해 Numpy 배열로 변환하고 속성을 출력하면 차원은 3, 모양은 (2, 3, 4), 크기는 24, 데이터 타입은 int 64, 원소 크기는 8의 값을 출력하게 됩니다.
import numpy as np
my_list = [[[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]],
[[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]]]
my_array = np.array(my_list)
print("차원:", my_array.ndim)
print("모양:", my_array.shape)
print("크기:", my_array.size)
print("데이터 타입:", my_array.dtype)
print("각 원소 크기:", my_array.itemsize)
#결과
#차원: 3
#모양: (2, 3, 4)
#크기: 24
#데이터 타입: int64
#각 원소 크기: 8
1.2 Numpy 배열 생성
Numpy 배열을 생성하는 방법에는 여러 가지가 있습니다. 가장 간단한 방법은 numpy.array() 함수를 사용하여 입력 데이터를 ndarray로 변환하는 것입니다. numpy.array는 입력 데이터(리스트, 리스트의 튜플, 다른 배열 등)를 ndarray로 변환합니다.
import numpy as np
my_list = [1, 2, 3, 4, 5]
my_array = np.array(my_list)
#결과
#array([1, 2, 3, 4, 5])

numpy.arange는 특정 구간 안에서 일정 간격의 값으로 구성된 배열을 생성합니다. start 값에서 시작하여 stop 값까지 step 간격으로 숫자를 생성합니다. 여기서 stop값은 범위에 포함되지 않습니다. 아래 코드에서는 0에서 시작하여 10보다 작은 동안 2씩 증가하는 숫자를 생성합니다.
import numpy as np
my_array = np.arange(0, 10, 2)
#결과
#array([0, 2, 4, 6, 8])

numpy.zeros는 모든 원소가 0인 배열을 생성합니다. 괄호 안의 숫자는 배열의 형태를 나타냅니다. (3, 3)은 이 배열이 3행 3열의 2차원 배열임을 의미합니다. 이 함수는 모델 초기화나 임시 데이터 생성 등에 유용하게 사용됩니다. 이 함수는 데이터 타입을 flot64로 설정하여 실수 0을 배열에 저장합니다. 만약 다른 데이터 타입의 0으로 배열을 채우고 싶다면, dtype 인자를 이용해야 합니다.
import numpy as np
zeros_array = np.zeros((3, 3))
#결과
#array([[0., 0., 0.],
# [0., 0., 0.],
# [0., 0., 0.]])

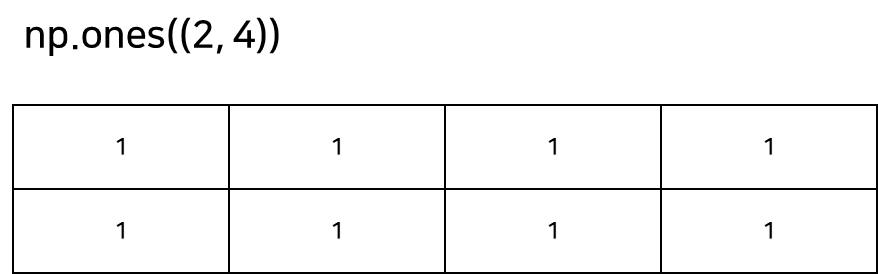
numpy.ones는 모든 원소가 1인 배열을 생성합니다. (2, 4)은 이 배열이 2행 4열의 2차원 배열임을 의미합니다. 이 함수는 가중치를 초기화 할 때, 연산에서 모든 원소가 1인 배열이 필요할 때 주로 사용됩니다. 이 함수는 데이터 타입을 flot64로 설정하여 실수 0을 배열에 저장합니다. 만약 다른 데이터 타입의 0으로 배열을 채우고 싶다면, dtype 인자를 이용해야 합니다.
import numpy as np
ones_array = np.ones((2, 4))
#결과
#array([[1., 1., 1., 1.],
# [1., 1., 1., 1.]])
numpy.empty는 초기화되지 않은 원소로 구성된 배열을 생성합니다. 이 함수를 이용해서 만들어지는 배열의 초기값은 메모리 상태에 따라 결정되므로 어떤 값이 들어있는지 알 수 없습니다. 그래서 보통 무작위 값이 들어가게 됩니다. 이 함수는 배열을 생성만 하고 초기화를 하지 않으므로 np.zeros, np.ones 보다 빠르게 실행될 수 있습니다.
import numpy as np
empty_array = np.empty((2, 3))
#결과
#array([[6.90738604e-310, 4.67296746e-307, 4.67296746e-307],
# [1.89146896e-307, 1.37961302e-306, 1.60219306e-306]])

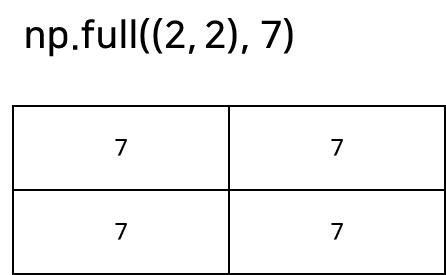
numpy.full는 모든 원소가 지정한 특정 값으로 채워진 배열을 생성합니다. 괄호 안의 첫 번째 인자는 배열의 형태를 나타냅니다. 두 번째 인자는 배열의 모든 요소를 초기화하는 값입니다. 아래 코드의 경우에는 7이므로, 모든 요소가 7로 초기화됩니다.
import numpy as np
full_array = np.full((2, 2), 7)
#array([[7, 7],
# [7, 7]])
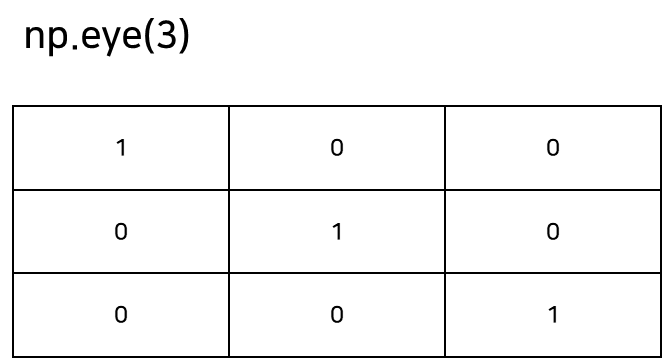
numpy.eye는 주어진 크기의 단위 행렬(Identity matrix)을 생성합니다. 단위 행렬은 대각선 원소들이 모두 1이고, 나머지 원소들이 모두0인 정방 행렬입니다. 이 행렬은 선형대수학에서 중요한 역할을 합니다. 그래서 역행렬을 계산하거나 선형 방정식의 해를 구할 때 사용하기도 합니다.
import numpy as np
eye_array = np.eye(3)
#array([[1., 0., 0.],
# [0., 1., 0.],
# [0., 0., 1.]])
1.3 데이터 타입
Numpy 배열은 다양한 종류의 데이터 타입을 지원합니다. 배열 생성 시 데이터 타입을 명시적으로 지정할 수도 있고, Numpy가 자동으로 데이터 타입을 추론할 수도 있습니다. 일반적으로 사용되는 데이터 타입에는 다음과 같은 것들이 있습니다.
- int : 정수 타입
- float : 부동소수점 타입
- bool : 불리언 타입
- str : 문자열 타입
아래 예시 코드에서는 dtype=np.float64를 사용하여 배열의 데이터 타입을 부동소수점으로 명시적으로 지정했습니다.
import numpy as np
my_array = np.array([1, 2, 3, 4, 5], dtype=np.float64)
Numpy에서 데이터 타입에 따라 배열의 각 원소의 크기(itemsize)가 다를 수 있습니다. 다음은 몇 가지 일반적인 데이터 타입에 따른 크기 변화의 예시입니다.
- np.int8: 1 바이트
- np.int16: 2 바이트
- np.int32: 4 바이트
- np.int64: 8 바이트
- np.float16: 2 바이트
- np.float32: 4 바이트
- np.float64: 8 바이트
아래 예시 코드에서 np.int32 데이터 타입의 배열은 각 원소가 4 바이트 크기이고, np.float64 데이터 타입의 배열은 각 원소가 8 바이트 크기임을 알 수 있습니다. 이와 같이 데이터 타입에 따라 배열의 원소 크기가 달라집니다.
import numpy as np
int_array = np.array([1, 2, 3], dtype=np.int32)
float_array = np.array([1.0, 2.0, 3.0], dtype=np.float64)
print("int_array의 원소 크기:", int_array.itemsize)
print("float_array의 원소 크기:", float_array.itemsize)
#int_array의 원소 크기: 4
#float_array의 원소 크기: 8
Numpy에서 bool과 str 데이터 타입에 대한 크기는 다음과 같습니다. bool 데이터 타입은 True 또는 False 값을 가지는 불리언 타입입니다. 그래서 일반적으로 1 바이트 크기를 차지합니다. str 데이터 타입은 문자열을 표현하는 타입입니다. 문자열은 길이에 따라 크기가 달라집니다. 예를 들어, 10글자짜리 문자열은 10 바이트 크기의 메모리를 차지합니다.
아래 예시 코드에서 np.bool 데이터 타입의 배열은 각 원소가 1 바이트 크기이고, np.str_ 데이터 타입의 배열은 가변적인 길이를 가지므로 -1로 표시됩니다.
import numpy as np
bool_array = np.array([True, False, True], dtype=np.bool)
str_array = np.array(["Hello", "World", "안녕하세요"], dtype=np.str_)
print("bool_array의 원소 크기:", bool_array.itemsize)
print("str_array의 원소 크기:", str_array.itemsize)
#결과
#bool_array의 원소 크기: 1
#str_array의 원소 크기: -1