

1. Pandas 소개
Pandas는 Python에서 사용하는 데이터 분석 라이브러리입니다. 이름은 "PANel DAta"의 약자로 금융 경제학 용어에서 유래되었습니다. Pandas는 데이터 조작 및 분석을 위해 설계되었으며, 빠르고 유연한 데이터 구조를 제공하여 대규모 데이터 세트를 효율적으로 처리할 수 있습니다.
Pandas는 다음과 같은 주요 특징을 가지고 있습니다.
- 다양한 데이터 타입 처리 : Pandas는 다양한 타입의 데이터를 처리할 수 있습니다. 예를 들어, 정수, 실수, 문자열, Python 객체 등을 처리할 수 있습니다.
- 누락된 데이터 처리 : Pandas는 누락된 데이터를 쉽게 처리할 수 있습니다. 예를 들어, 누락된 데이터를 특정 값으로 채우거나 누락된 데이터를 포함하는 행이나 열을 삭제할 수 있습니다.
- 데이터 병합 : Pandas는 여러 데이터프레임을 하나로 병합하거나 조인할 수 있는 기능을 제공합니다.
- 피벗 테이블 생성 : Pandas는 피벗 테이블을 쉽게 생성할 수 있습니다. 피벗 테이블은 데이터를 요약하고 분석하는데 유용합니다.
- 시계열 데이터 처리 : Pandas는 시계열 데이터를 다루는 데 매우 유용한 도구들을 제공합니다.
Pandas를 사용하기 위해서는 먼저 pandas 패키지를 설치해야 합니다. pip를 통해 설치하는 경우 아래와 같이 명령을 실행합니다.
pip install pandas
Python에서 Pandas를 사용하기 위해서는 일반적으로 아래와 같이 패키지를 불러옵니다.
import pandas as pd
2. Pandas 데이터 구조
Pandas는 Series, DataFrame, Index라는 세 가지 핵심 데이터 구조를 기반으로 작동합니다.
2.1 Series
Pandas Series는 기본 데이터 구조 중 하나로, 1차원 배열로과 유사하게 동작합니다. 이러한 구조는 일련의 데이터 항목을 저장하고 조작할 수 있는 기능을 제공합니다. Series는 index 을 가질 수 있으며, index를 기반으로 데이터를 액세스할 수 있습니다.

2.1.1 생성
pd.Series 객체는 여러 가지 데이터 유형으로부터 생성될 수 있습니다. 가장 일반적인 방법 중 하나는 리스트 또는 NumPy 배열에서 Series를 만드는 것입니다. 아래 코드는 정수, 실수, NaN(누락된 데이터를 나타냄)을 포함하는 Series를 만듭니다. 또한 딕셔너리를 통해 Series를 만들 수도 있습니다. 이 경우, 딕셔너리의 키가 Series의 index가 됩니다.
import pandas as pd
# 리스트를 사용하여 Series 생성
s1 = pd.Series([1, 3, 5, np.nan, 6, 8])
print(s1)
# 출력:
# 0 1.0
# 1 3.0
# 2 5.0
# 3 NaN
# 4 6.0
# 5 8.0
# dtype: float64
# Dictionary를 사용하여 Series 생성
s2 = pd.Series({'a': 1, 'b': 2, 'c': 3})
print(s2)
# 출력:
# a 1
# b 2
# c 3
# dtype: int64
2.1.2 인덱싱
Series의 요소에는 인덱스를 사용하여 엑세스 할 수 있습니다. 인덱스를 지정하지 않으면 Pandas는 기본적으로 0에서 시작하는 정수 인덱스를 제공합니다. 명시적으로 인덱스를 지정하는 경우에는, 고유한 인덱스 또는 시계열 데이터 등을 사용할 수 있습니다. 예제에서 인덱스 'a', 'b', 'c', 'd', 'e'는 Series의 각 값에 대한 인덱스 역할을 합니다. 이 인덱스를 사용하여 Series의 값을 참조할 수 있습니다.
s = pd.Series([1, 3, 5, np.nan, 6, 8])
print(s[0]) # 출력: 1.0
print(s[3]) # 출력: NaN
s2 = pd.Series({'a': 1, 'b': 3, 'c': 5})
print(s2['a']) # 출력: 1
print(s2['c']) # 출력: 5
s3 = pd.Series([1, 2, 3, 4, 5], index=['a', 'b', 'c', 'd', 'e'])
print(s)
print(s3['a']) # 출력: 1
print(s3['d']) # 출력: 4
2.1.3 메소드
Series에는 데이터 처리 및 변환을 돕는 다양한 메소드가 있습니다. 예를 들어, describe() 메소드는 Series의 기술 통계를 제공하고, hist() 메소드는 Series의 히스토그램을 그릴 수 있습니다. mean(), median(), max(), min()등의 메소드는 Series의 평균, 중앙값, 최대값, 최소값을 계산할 수 있습니다.
hist() 메소드는 그래프를 생성하는 메소드입니다. 아래 코드를 실행하면 다음과 같은 hist()가 생성됩니다. 이 hist()는 모두 유니크하고, 그 간격이 일정하기 때문에 즉, 각 숫자가 한번씩만 나타나고, 각 숫자 사이의 간격이 동일하므로, 히스토그램에서 각 bin(구간)의 높이는 모두 동일하게 나타납니다.
import pandas as pd
import matplotlib.pyplot as plt
s = pd.Series([1, 2, 3, 4, 5])
s.hist()
plt.show()
아래 코드는 describe(), mean(), median(), max(), min() 메소드를 사용한 예시 코드입니다.
import pandas as pd
# Series 생성
s = pd.Series([1, 2, 3, 4, 5])
# 기본 통계 요약 출력
print(s.describe())
# 출력:
# count 5.000000
# mean 3.000000
# std 1.581139
# min 1.000000
# 25% 2.000000
# 50% 3.000000
# 75% 4.000000
# max 5.000000
# 평균 출력
print(s.mean())
# 출력: 3.0
# 중앙값 출력
print(s.median())
# 출력: 3.0
# 최대값 출력
print(s.max())
# 출력: 5
# 최소값 출력
print(s.min())
# 출력: 1
2.1.4 결측치 처리
Pandas에서는 누락된 데이터를 표현하는 데 NaN 값을 사용합니다. Series에서는 .isnull() 또는 .notnull() 메소드를 사용하여 이러한 값들을 감지하고, .dropna() 메소드를 사용하여 이를 제거할 수 있습니다. 또한, .fillna(value) 메소드를 사용하여 NaN 값을 특정 값으로 대체할 수 있습니다.
import pandas as pd
import numpy as np
# NaN 값이 포함된 Series 생성
s = pd.Series([1, 2, np.nan, 4, 5])
# NaN 값이 있는지 확인
print(s.isnull())
# 출력:
# 0 False
# 1 False
# 2 True
# 3 False
# 4 False
# dtype: bool
# NaN 값을 제거
s_no_nan = s.dropna()
print(s_no_nan)
# 출력:
# 0 1.0
# 1 2.0
# 3 4.0
# 4 5.0
# dtype: float64
# NaN 값을 특정 값(예: 0)으로 대체
s_filled = s.fillna(0)
print(s_filled)
# 출력:
# 0 1.0
# 1 2.0
# 2 0.0
# 3 4.0
# 4 5.0
# dtype: float64
2.1.5 벡터화 연산
Series는 벡터화된 연산을 지원합니다. 이는 Series의 각 요소에 함수를 적용하거나, 두 Series 사이의 산술 연산을 수행할 수 있음을 의미합니다. 이러한 연산은 속도와 효율성 측면에서 매우 유용합니다.
s1 = pd.Series([1, 2, 3, 4, 5])
s2 = pd.Series([10, 20, 30, 40, 50])
# 두 시리즈를 더합니다.
s3 = s1 + s2
2.2 DataFrame
Pandas DataFrame은 2차원 테이블로, 서로 다른 타입의 데이터를 보관할 수 있습니다. DataFrame은 각 열마다 다른 타입의 데이터(숫자, 문자열, 불리언 등)를 저장할 수 있으며, 데이터는 열이나 행을 기준으로 선택, 정렬, 조작될 수 있습니다. DataFrame은 스프레드시트, SQL 테이블, 또는 R의 data.frame과 같은 2차원 테이블 형식의 데이터 구조와 유사합니다. DataFrame은 다양한 방법으로 생성할 수 있습니다. 가장 일반적인 방법은 딕셔너리를 사용하는 것입니다.
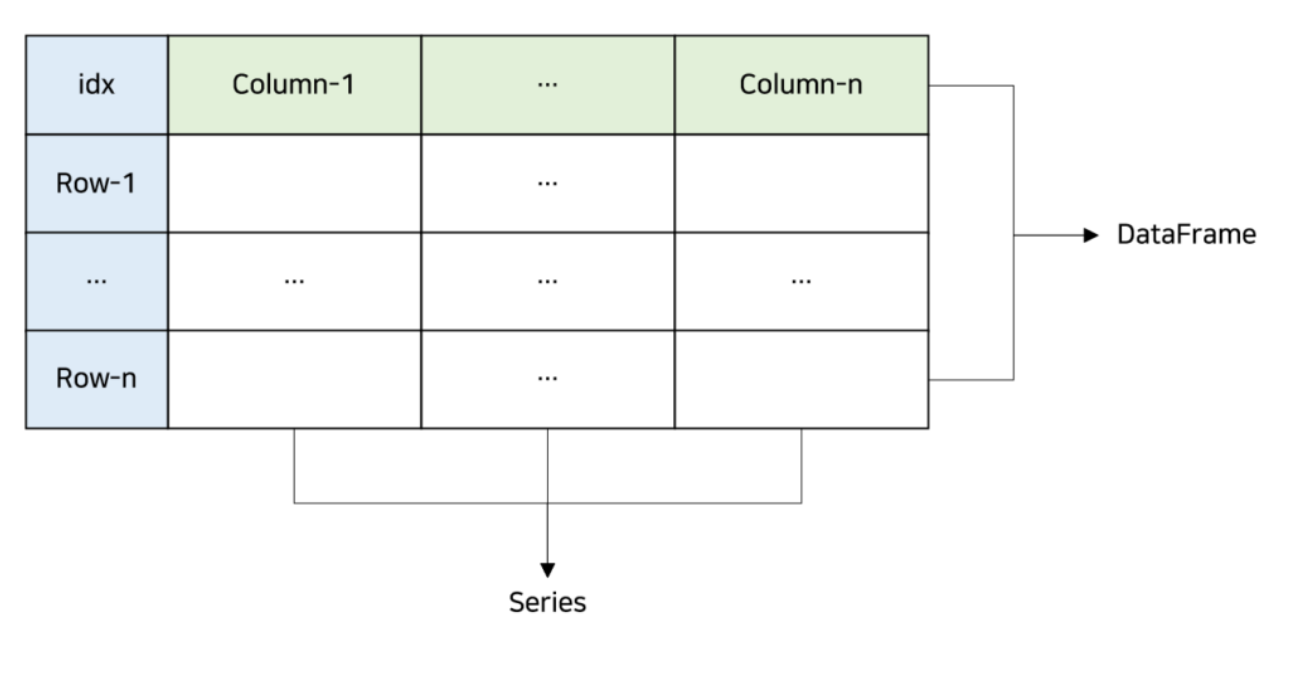
2.2.1 생성
DataFrame은 다양한 방법으로 생성할 수 있습니다. 가장 간단한 방법 중 하나는 딕셔너리를 사용하는 것입니다. 코드는 각각 'name', 'age', 'city'라는 열 이름과 연관된 데이터를 가진 딕셔너리를 DataFrame으로 변환합니다. 데이터프레임을 생성할 때 index 매개변수를 사용하여 인덱스 값을 지정할 수 있습니다. 이를 통해 인덱스에 특정 값을 할당할 수 있습니다.
import pandas as pd
data = {
'name': ['John', 'Anna', 'Peter', 'Linda'],
'age': [28, 24, 35, 32],
'city': ['New York', 'Paris', 'Berlin', 'London']
}
df = pd.DataFrame(data)
df2 = pd.DataFrame(data, index=['Person 1', 'Person 2', 'Person 3', 'Person 4'])
print(df)
print(df2)
#출력
# name age city
#0 John 28 New York
#1 Anna 24 Paris
#2 Peter 35 Berlin
#3 Linda 32 London
#출력
# name age city
#Person 1 John 28 New York
#Person 2 Anna 24 Paris
#Person 3 Peter 35 Berlin
#Person 4 Linda 32 London
2.2.2 접근하기
DataFrame에는 데이터를 조작하는데 유용한 다양한 메소드가 있습니다. 예를 들어, describe() 메소드는 숫자형 열의 기본적인 통계적 정보를 제공합니다. sort_values() 메소드는 특정 열의 값에 따라 행을 정렬합니다.
import pandas as pd
data = {
'name': ['John', 'Anna', 'Peter', 'Linda'],
'age': [28, 24, 35, 32],
'city': ['New York', 'Paris', 'Berlin', 'London']
}
df = pd.DataFrame(data)
print(df.describe())
df_sorted = df.sort_values('age')
print(df_sorted)
2.2.3 결측치 처리
결측치는 np.nan으로 표시되며, 이를 처리하는 데에는 주로 dropna()와 fillna() 함수를 사용합니다. dropna(): NaN 값이 있는 행 또는 열을 삭제합니다. fillna(): NaN 값을 특정 값으로 채웁니다. 자세한 내용은 강좌-5 에서 다룹니다.
df = pd.DataFrame({
'A': [1, 2, np.nan],
'B': [5, np.nan, np.nan],
'C': [1, 2, 3]
})
print(df.dropna())
print(df.fillna(value='FILL VALUE'))
2.2.4 데이터 필터링
조건에 맞는 데이터를 선택하는 것입니다. 자세한 내용은 강좌-3 에서 다룹니다.
df = pd.DataFrame({
'A': ['foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'foo'],
'B': ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'],
'C': np.random.randn(8),
'D': np.random.randn(8)
})
# 'A'열이 'foo'인 행만 선택
print(df[df['A'] == 'foo'])
2.2.5 그룹화
groupby() 함수를 사용하면, 하나 이상의 열을 기준으로 데이터를 그룹화하고, 그룹별로 집계 함수를 적용할 수 있습니다. 자세한 내용은 강좌-7 에서 다룹니다.
# 'A'열을 기준으로 그룹화하고, 각 그룹별로 'D'열의 평균을 구함
print(df.groupby('A')['D'].mean())
2.2.6 데이터 합치기
merge(), join(), concat() 등의 함수를 사용해 데이터프레임을 여러 가지 방법으로 합칠 수 있습니다. concat(): 데이터프레임을 이어 붙입니다. merge(): 하나 이상의 키를 기준으로 데이터프레임의 행을 합칩니다. join(): 인덱스를 기준으로 데이터프레임을 합칩니다. 자세한 내용은 강좌-6 에서 다룹니다.